GTC 2024落下帷幕了,但这个大会的信息仍在AI产业和经济中发酵。咨询机构WIKIBON认为,GTC 2024在整个科技史中的意义超过了当年史蒂夫·乔布斯的iPod和iPhone发布。在AI将永久改变人类的共识下,GTC 2024在广度、愿景、生态系统等方面都有着深远影响。其中,堪比iPhone发布的“产品”,就是面向万亿参数大模型的NVIDIA智算中心。
黄仁勋在前几年就提出了产品化智算中心的理念,后来又不断强调“AI工厂”的概念,直到GTC 2024才完整揭晓——面向万亿参数大模型的模块化智算中心,顶配版基本模块为多节点、液冷、机架集群系统NVL72,搭配了最新GPU芯片GB200的8个NVL72可互联为一个GB200 SuperPOD、共576个Blackwell GPU,GB200 SuperPOD是DGX SuperPOD的“顶配版”,DGX GB200 SuperPOD被NVIDIA称为是全球首个“交钥匙”的AI智算中心。

(DGX GB200 SuperPOD)
在GTC 2024大会之后的一个月,关于NVIDIA智算中心“产品”的更多信息被披露出来,业界开始有了较全面的认知——NVIDIA对AI数据中心又称为智算中心或“AI工厂”,有着完整的计划和多种配置的产品线,同时与 NVIDIA 认证合作伙伴提供的高性能存储集成后,每个SuperPOD都在出厂前完成了搭建、布线和测试,极大加快了在用户数据中心的部署速度,而多个SuperPOD还能轻松互联组成万卡级别的智算中心。
多年蓄势、厚积薄发
在了解NVIDIA智算中心产品线之前,我们有必要了解一下这几年NVIDIA在AI数据中心领域的布局,有助于真正了解所谓NVIDIA智算中心“产品”或产品化的智算中心。
NVIDIA在2016年发布了面向深度学习的服务器产品线DGX以及第一代产品DGX-1,当时该服务器对于深度学习计算的处理性能相当于250台X86服务器。
DGX成为NVIDIA旗下自有技术体系、自有品牌的AI服务器产品线,同时NVIDIA还向服务器合作伙伴发布了AI服务器技术参考架构HGX,允许X86服务器厂商在X86技术体系内参考DGX的技术架构,自行设计和生产AI服务器。

(DGX H100服务器)
简单理解,DGX相当于是顶配和高配的NVIDIA GPU服务器,HGX相当于中低配的NVIDIA GPU服务器。在完整的DGX产品线中,DGX SuperPOD和DGX BasePOD为AI服务器集群,也可以视为一个AI数据中心或智算中心。
其中,DGX SuperPOD相当于NVIDIA自产的顶配和高配AI服务器集群,又叫“DGX AI Supercomputer”超级AI计算机或AI数据中心,也可理解为智算中心;DGX BasePOD为提供给X86服务器厂商、在X86技术体系内的AI服务器集群参考架构,相当于中低配版AI服务器集群。
黄仁勋认为全球数据中心市场是一个高达几千亿美元的市场。为了进入这一市场,NVIDIA从很早之前就开始布局AI服务器和AI服务器集群技术以及合作伙伴生态。
AI服务器属于加速计算领域,除了GPU外,还需要加速芯片和更高的互联技术。NVIDIA在2019年以69亿美元的价格收购网络芯片公司Mellanox,并于次年推出BlueField-2 DPU。2023年,NVIDIA推出了BlueField-3 DPU,相比上一代产品具有2倍的网络带宽、4倍的计算能力以及4倍的IPsec加密速度,BlueField-3 DPU也是首款支持第五代PCIe总线并提供数据中心时间同步加速的DPU。
在网络技术方面,NVIDIA共有两条产品线,分别是面向高端Infiniband的NVIDIA Quantum和面向中低端以太网的NVIDIA Spectrum。与面向互联网的以太网络不同,Infiniband是一种高带宽、低时延的服务器端高性能网络通信技术,Infiniband通常都是昂贵的设备。NVIDIA为Quantum和Spectrum都提供了完整的交换机设备、网卡和网络设计参考蓝图。
在片内互联以及服务器板互联技术方面,NVLink是用于服务器内部GPU通信的高带宽通信协议,可以实现服务器内部GPU到GPU的高速直连。NVIDIA在2014年推出了NVLink的首个版本,能让型号相同的显卡实现直接通信,包括共享卡上的显存。但NVLink主要用于单节点服务器内的GPU直连,能够连接的GPU数量有限,为了搭建AI服务器集群,NVIDIA推出了NVSwitch。通过NVSwitch交换设备,能够用NVLink连接集群内多节点上的GPU卡。
NVIDIA在2019年就已经推出了DGX POD,作为一种经过优化的数据中心机架,可配备多台 DGX-1 GPU 服务器或DGX-2服务器、存储服务器和网络交换机,支持单节点和多节点AI模型训练和推理。2020年,NVIDIA打造了当时最大的基于V100的DGX-2集群,也是DGX POD。
2019年,NVIDIA推出了由96台DGX-2H组成的超级计算集群NVIDIA DGX SuperPOD,在国际超算TOP500上排名22。2021年,NVIDIA推出了基于DGX A100的DGX SuperPOD;同时还发布了 NVIDIA Base Command,可让多个用户和 IT 团队安全地访问、共享和操作DGX SuperPOD。当时的DGX SuperPOD由20套以上的DGX A100和NVIDIA Infiniband设备组成,是一整套AI数据中心规制。
NVIDIA智算中心“产品”线
有了上面的基本知识,让我们来认识最新的NVIDIA智算中心产品线,首先从大的“POD”可分为DGX SuperPOD和DGX BasePOD。
最新的产品化的DGX SuperPOD和BasePOD都不是凭空而来的模块化智算中心,而是经过了前期TOP 500超算集群和AI就绪型数据中心等演进,直到今天的产品化模块化智算中心。

DGX GB200 SuperPOD顶配版包括8个或更多的DGX GB200。每个DGX GB200为一个NVL72液冷集群通过NVLink互联而成,每个NVL72为两个18U机架组成,即每个机架包含 18 个 Grace CPU 和 36 个 Blackwell GPU,并通过第四代 NVIDIA NVLink 交换机连接。因此每个DGX GB200包含了36个GB200,即36个Grace CPU和72个Blackwell GPU。
这里容易混淆:NVL72代表了采用NVLink互联技术和液冷技术的集群,而DGX GB200是DGX服务器线中配置了GB200超级芯片的顶配服务器,由于其超强的功耗和需要超级的互联技术而采用了NVL72机架集群,72代表了72个Blackwell GPU,也就是说该技术体系下的机柜可承载72个Blackwell GPU,NVIDIA还推出了另一个NVL36机架集群,即只有一半数量的GPU与CPU配置。因此,采用了NVL72液冷集群的DGX GB200就是DGX GB200 SuperPOD基础模块。

(GB200 NVL72)
与DGX GB200 SuperPOD“顶配版”同时上市的还有第五代 NVIDIA NVLink 网络、NVIDIA Quantum-X800 InfiniBand,加上NVIDIA BlueField-3 DPU, 这个架构可为计算平台中的每块GPU提供高达每秒1800 GB的带宽。
为了提升万亿级参数模型和混合专家大模型的性能,最新一代的第五代NVIDIA NVLink为每块GPU提供突破性的1.8TB/s双向吞吐量,确保多达576块GPU之间的无缝高速通信,满足了当今最复杂大模型的需求。
NVIDIA Quantum-X800 InfiniBand,包含了NVIDIA Quantum Q3400交换机和NVIDIA ConnectX-8 SuperNIC智能网卡,二者互连达到了业界领先的端到端800Gb/s吞吐量,交换带宽容量较上一代产品提高了5倍,网络计算能力凭借新一代的NVIDIA SHARP技术(SHARPv4)提高了9倍,达到了14.4Tflops。
“顶配版”DGX GB200 SuperPOD外,还有DGX B200 SuperPOD以及DGX H100 SuperPOD,也就是所谓高配版SuperPOD。而与SuperPOD相对应的就是基于X86架构的“中低配版”DGX BasePOD。最新的DGX BasePOD包括采用风冷机柜的DGX B200和DGX H00,以及采用DGX A100的“低配版”。
其中,“中配版”采用的是最新B200 GPU芯片和风冷架构以及新推出的Spectrum-X800以太网络平台,借助800Gb/s的Spectrum SN5600交换机和NVIDIA BlueField-3 SuperNIC,为多租户生成式AI云和大型企业级带来先进功能。
“中低配版”搭载了已经上市的H100 GPU和NVIDIA ConnectX-7 SmartNIC。考虑到上市两年的H100仍处于供不应求的状态,DGX BasePOD“中低配版”对于很多客户来说也已经是“高配版”了。
DGX BasePOD还有一个“低配版”,这就是2021年推出的配置了A100 GPU的DGX A100参考架构。NVIDIA还提供了AWS部署的DGX H100与DGX A100参考架构。
全栈AI软件与大模型
NVIDIA对于AI数据中心的“野心”不仅限于硬件层面,而是从软件、算法模型以及最终应用的全栈布局。因此,NVIDIA DGX SuperPOD与BasePOD都是基础设施和软硬一体优化的系统工程。
首当其冲的NVIDIA软件当属CUDA。CUDA全称为 Compute Unified Device Architecture,是英伟达于2006年推出的一个专门用于自有GPU硬件进行软件开发的接口,包括编译器、调试器、丰富的库函数、各种软件工具等,提供了庞大的资源。
CUDA降低了GPU编程的门槛,让开发者使用C/C++/Python等语言,就可以通过CUDA编写GPU程序。例如,CUDA包括了线性函数、快速傅里叶变换(FFT)等常用的加速函数。2019年,NVIDIA推出了面向Tensor Core GPU的CUDA-X函数库,提供了丰富的并行算法库、图像与视频库、深度学习库、通信库以及合作伙伴库等。可以说,CUDA和CUDA- X是NVIDIA通用GPU计算的护城河。
在CUDA的基础上,NVIDIA推出一系列AI与大模型软件产品组合,与自有硬件生态相配合,共同为用户交付完整的智算中心及服务。
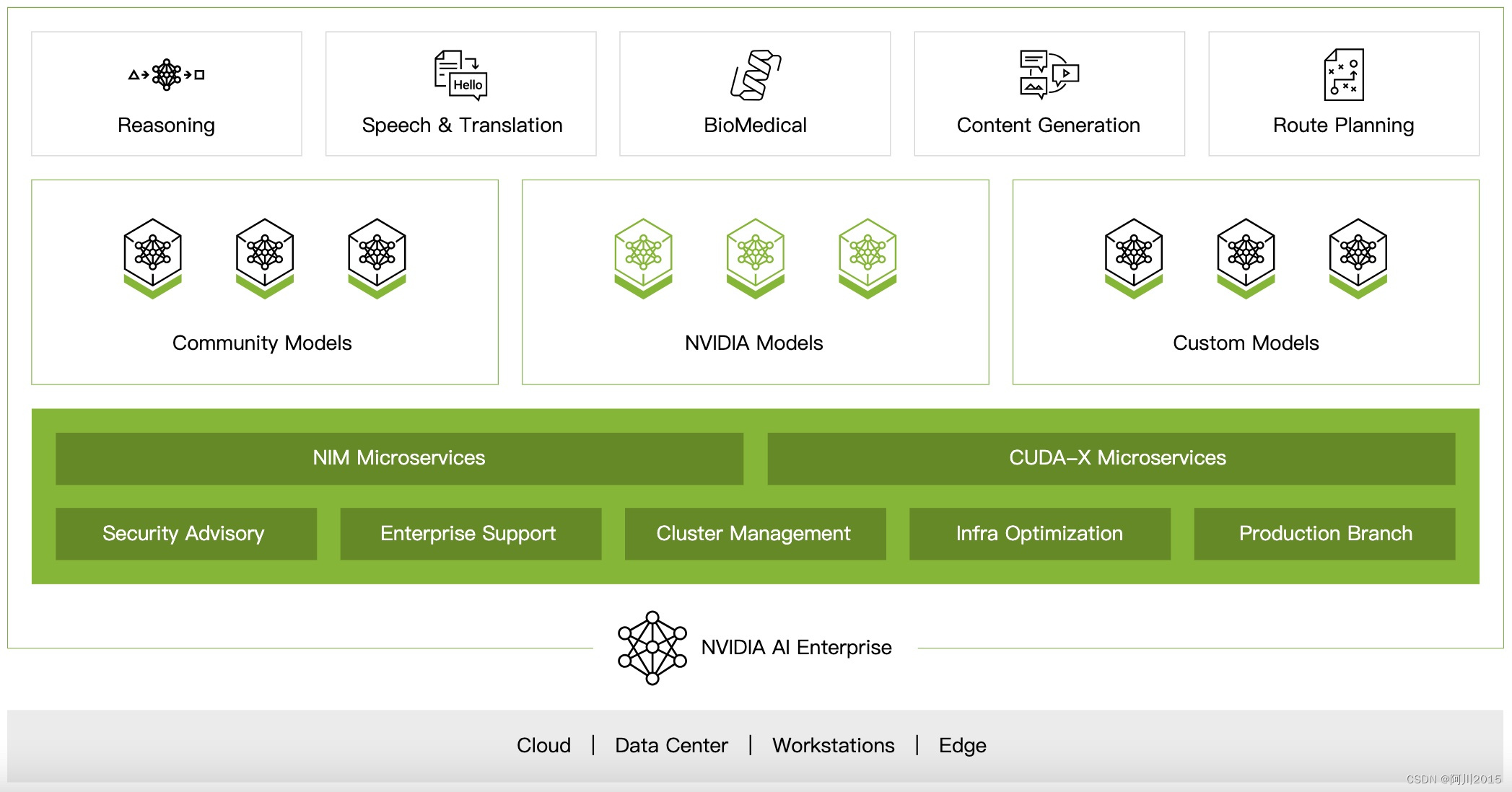
首先是NVIDIA AI Enterprise Platform。这款在2021年推出的企业级AI平台,面向 AI 研究人员、数据科学家和开发人员使用的应用程序、框架和工具。该套件可以加快开发人员构建人工智能和高性能分析的速度,跨越多个节点也能实现接近裸机服务器的性能,支持大型、复杂的训练和机器学习工作负载。
GTC 2024上发布的NVIDIA AI Enterprise5.0提供了广泛的微服务,其中包括NVIDIA NIM和CUDA-X微服务,这些微服务针对生产中部署AI模型进行了优化,支持GPU加速,为用户提供了更高效的推理过程。NVIDIA NIM微服务通过打包算法、系统和运行时优化,以及添加行业标准API,简化了AI模型部署过程,让开发人员能够轻松将 NIM集成到现有的应用程序和基础设施中,支持的模型包括LLM、VLM、语音、图像、视频、药物发现、医学成像等。
在NVIDIA AI Enterprise之上,NVIDIA又相继开发了丰富的AI与大模型软件。这些软件资产相当丰富,仅面向大模型的软件就包括Megatron-LM、Megatron Core、NeMo、TensorRT、TensorRT-LLM、Triton推理服务器等。
其中,Megatron-LM大模型分布式训练框架是由NVIDIA开发的一个开源的大模型加速训练框架,通过并行计算等优化方法可极大缩短大模型的训练时间,很多互联网和云公司的自研大模型底层都是Megatron-LM,其4D并行计算技术已经成为大模型训练标准范式之一。
众多厂商也基于Megatron-LM推出了自家的Megatron“发行版”,因此NVIDIA也推出了Megatron Core,相当于“Linux Kernel”内核。Megatron Core代表了NVIDIA对于大模型软件平台软件体系的愿景:打造大模型平台软件的开源“内核”,成为所有大模型软件和生态式AI应用的“操作系统”。
NVIDIA NeMo是一个用于构建先进的对话式AI模型的框架;NeMo framework是一个端到端的容器化分布式框架,可高效地训练和部署具有数十亿和数万亿参数的大语言模型;Triton 推理服务器是NVIDIA发布的一款开源软件,可简化深度学习模型在生产环境中的部署;TensorRT是NVIDIA提供的一款高性能深度学习推理SDK;TensorRT-LLM可在NVIDIA GPU上加速和优化大语言模型的推理性能……
NVIDIA在AI软件特别是大模型软件方面的研发,已经遥遥领先于业界,而所有这些软件的基础都是CUDA,它们自下而上地优化了NVIDIA的AI数据中心,提供了丰富的大模型应用开发和部署工具,也是“交钥匙”和开箱即用智算中心“产品”的保障。
“交钥匙”的智算中心
NVIDIA DGX GB200 SuperPOD被NVIDIA称为是全球首个“交钥匙”的AI智算中心。与以往将各种零部件运送到数据中心现场再组装起来的模式不同,新的SuperPOD基础模块都是在合作伙伴工厂里生产、搭建和测试成功后,再运送到客户数据中心现场简单安装即可,大幅缩短了整个智算中心的上线周期。

NVIDIA还将前期在Omniverse元宇宙方案中积累的数字孪生应用到AI智算中心的设计:Ansys、Cadence、PATCH MANAGER、Schneider Electric、Vertiv等合作伙伴为AI智算中心的数字孪生提供支持,允许企业用户在生产实际系统之前对数据中心设计进行全面测试、优化和验证,还能以集成方式平衡不同的边界条件(例如布线长度、电源、冷却和空间),从而增强数据中心和集群设计,让工程师和设计团队以更快的速度、更高的效率和更好的优化,让集群投入使用。
正如黄仁勋所言:以全新DGX GB200 SuperPOD为代表的NVIDIA DGX AI超级计算机,是推进 AI产业变革的“工厂”。而咨询机构WIKIBON之所以称GTC 2024在整个科技史中的意义超过了当年史蒂夫·乔布斯的iPod和iPhone发布,是因为新一代DGX SuperPOD和BasePOD已经是模块化的智算中心,而且是面向万卡和万亿参数大模型的智算中心。这就意味着企业用户不仅能够标准化地获得面向万亿参数的AI智算中心,还能获得一整套赋能软件和云服务体系以及一个完整的生态。从此,AI数据中心/智算中心迈进“智能机”时代。(文/宁川)