目录
一、工作原理
二、工作流程
2.1 初始化环境
2.2 添加规则文件
2.3 编译规则文件
2.4 插入到工作内存
2.5 规则匹配与激活
2.6 规则执行
三、Drools 其他特性
3.1 符合事实
3.2 决策表
3.3 规则生命周期管理
3.4 规则流
四、Rete 算法
一、工作原理
Drools 规则引擎的工作原理围绕以下几个核心概念和组件:
规则(Rules):规则是以声明性的方式表达业务逻辑的关键元素,由条件 LHS 和结论 RHS 构成。条件部分定义了触发规则的情景,结论部分则指明了当条件满足时应执行的动作。
事实(Fact):事实是传递给规则引擎的数据对象实例,代表了当前的状态或事件。规则引擎会将事实对象放入工作内存(Working Memory)中,规则的条件部分会对这些事实进行匹配。
工作内存(Working Memory):工作内存是规则引擎暂存事实的地方,也是规则引擎的执行场所。当事实被插入工作内存时,引擎会重新评估所有规则,看是否有规则的条件得到满足。
生产内存(Production Memory):在 Drools 中,生产内存同村指的是存放规则本身的地方,也就是规则库。这里的规则已经被编译并准备好了执行。
议程(Agenda):议程负责追踪所有满足条件的规则,以及他们的执行顺序。当规则的条件部分被满足,规则会被添加到议程中等待执行,Drools 支持多种执行策略,如正向链路、反向链路、冲突解决策略等,来决定规则的激活和执行顺序。
RETE算法 : RETE(Rapidly Exploring Random Trees)或其改进型 RETEOO,是 Drools 规则引擎背后的一种高效模式匹配算法,用于优化规则匹配过程,减少重复计算。它维护一个内部网络结构来跟踪条件之间的关系,以加速对工作内存中变化的事实进行反应。
二、工作流程
执行流程如下图:

2.1 初始化环境
首先,你需要通过 KieServices 获取 KieRepository 和 KieFileSystem,用于管理和加载规则文件。
KieServices kieServices = KieServices.Factory.get();
KieFileSystem kieFileSystem = kieServices.newKieFileSystem();2.2 添加规则文件
将.drl规则文件或者其他类型的资源文件添加到 KieFileSystem 中。
kieFileSystem.write(ResourceFactory.newClassPathResource("rules/myRule.drl"));
2.3 编译规则文件
使用 KieBuilder 构建 KieModule,从而将规则文件编译成可执行的形式。
KieBuilder kieBuilder = kieServices.newKieBuilder(kieFileSystem);
kieBuilder.buildAll(); // 编译
Results results = kieBuilder.getResults();
if (results.hasMessages(Message.Level.ERROR)) {// 处理编译错误
}KieContainer kieContainer = kieServices.newKieContainer(kieBuilder.getKieModule().getReleaseId()); 通过调用 kieBuilder.buildAll() 方法即可编译规则文件,通过 DrlParser 类来实现 规则文件的编译,并将其存储在规则库中。如下代码调用栈: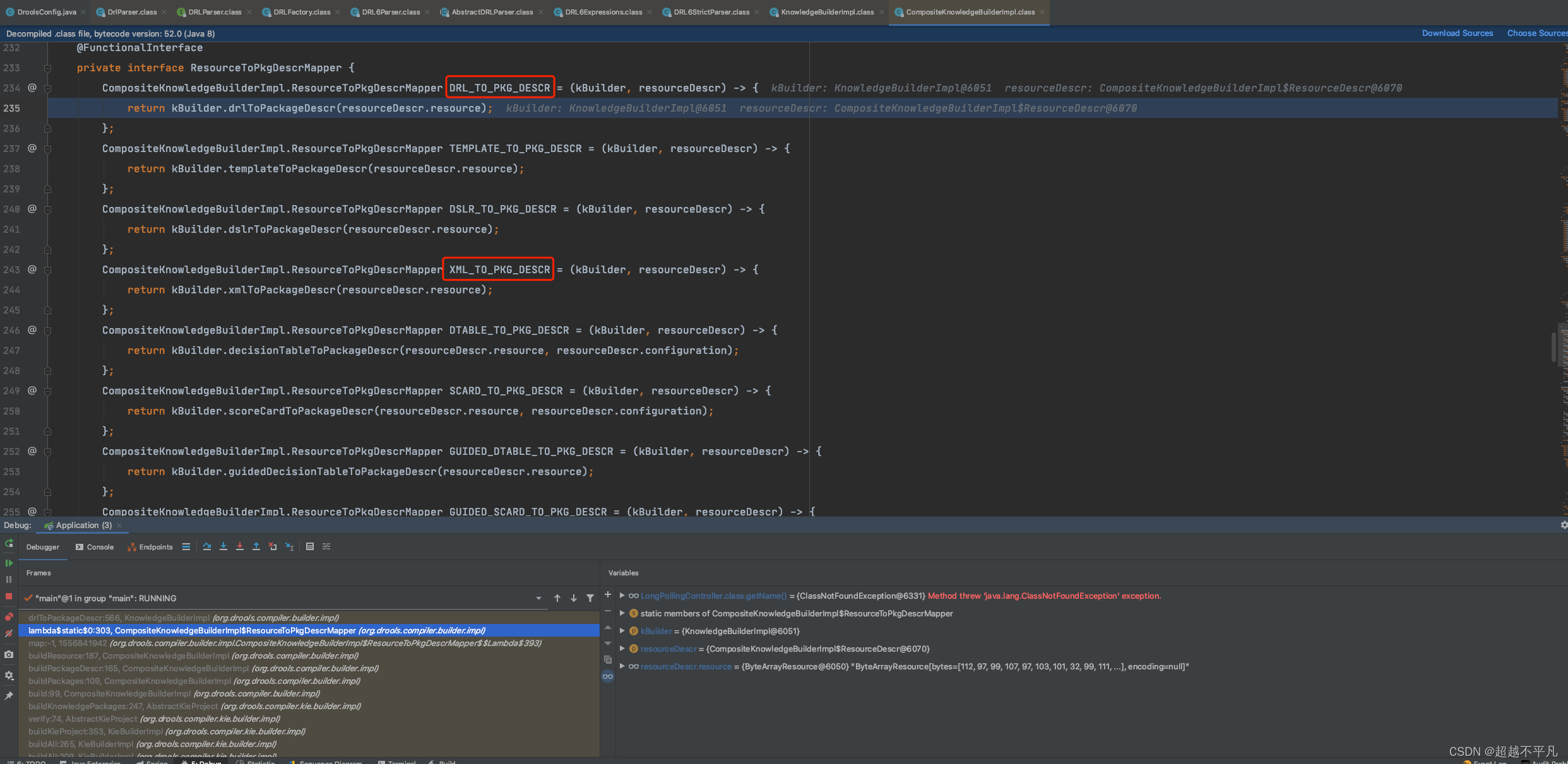
通过上图调用栈课发现,Drools 同时支持多种规则人间类型,经过规则编译后规则就进入到了生产内存中,二所谓的生产内存其实就是 KieBase,它包含了从 .drl 规则文件中加载并编译好的规则。在运行时,可以从这个 KieBase 中创建 KieSession,并在 KieSession 中插入实时对象、执行规则。
规则编译后的内容如下,详细内容请自行查看。
2.4 插入到工作内存
当调用 kieSession.insert(fact); 方法时,对象事实就会插入到工作内存中,所谓的工作内存就是 KieSession。
2.5 规则匹配与激活
当某个事实对象被插入或更新时,引擎遍历 Rete 网络,查找与该事实想匹配的规则条件。若规则的所有条件均满足,规则讲呗激活并添加到议程 Agenda 中。
2.6 规则执行
通过调用 kieSession.fireAllRules() 方法来触发所有已经匹配的规则开始执行,执行直至 Agenda 为空,即所有符合条件的规则都已经关闭,或者遇到终止条件。
规则执行的过程可能有副作用,具体包括:更新 Working Memory 中的事实、执行系统外部操作、出发新的规则激活等。
总之,fireAllRules 方法启动了一轮完成的规则执行周期,该周期会持续地匹配、激活、执行规则,直到没有更多的规则可以执行为止。
最后需要调用 dispose() 方法用于释放和清理当前 kieSession 相关的所有资源。这样一次完成的规则执行就结束了。
三、Drools 其他特性
3.1 符合事实
在复杂的业务场景中,有时需要组合多个对象形成一个新的事实来参与规则匹配。复合事实可以通过事实对象继承、聚合或嵌套等方式构造。
3.2 决策表
Drools 支持使用决策表(Spreadsheet Decision Tables)来编写规则,这种方式特别适合于那些基于表格形式展现的复杂条件逻辑,例如Excel文件格式。决策表可以清晰地可视化规则条件和结果,方便非程序员维护。
3.3 规则生命周期管理
Drools 支持规则的动态加载、更新和卸载。例如,通过 KieScanner 实现规则库的热部署,当规则文件发生变化时,可以自动重新加载规则。
3.4 规则流
使用 Drools Workbench 或 jBPM 流程设计器,可以创建流程图来定义规则执行的顺序和流程,从而实现流程驱动的规则执行。
在使用规则引擎时有一些需要注意的事项
- 注意工作内存管理:不要一次性插入过多的事实对象,否则可能会导致性能下降升值内存溢出。
- 规则的组织应保持清晰,毕淼规则交叉和互相依赖。
- 对象事实的生命周期要清晰,了解合适插入,何时更新等。
- 在并发环境下,注意正确的使用 KieSession 实例。
四、Rete 算法
Drools Rete 算法是基于Charles Forgy在1979年提出的 Rete 算法的一种实现,它是规则引擎中用于高效处理大量规则和事实的模式匹配算法。Rete 算法的目标是解决在大型规则库中多次检查相同事实的问题,通过构建一种数据结构(Rete网络),将规则条件分割并缓存中间结果,使得当事实发生变化时,只需要沿着网络进行局部传播,大大减少了不必要的计算。
在 Drools 中,Rete 算法以及其变种(如ReteOO)被用来优化规则引擎的性能,它构建了一个高效的推理网络,该网络能够记住之前的匹配结果,从而在新的事实插入、更新或删除时,迅速识别出受到影响的规则,以及哪些规则条件已经满足,应当被触发执行。
Rete算法的工作原理如下:
- 将规则拆分成多个条件节点,并在网络中构建层次结构。
- 当事实对象插入工作内存时,它们在网络中传播并激活与之匹配的节点。
- 激活的节点形成路径,如果这条路径上的所有节点都被激活,则规则被视为满足条件,加入到议程(Agenda)中等待执行。
往期经典推荐
深入浅出 Drools 规则引擎-CSDN博客
系统优化都没做过?看这篇就够了-CSDN博客
SpringBoot项目并发处理大揭秘,你知道它到底能应对多少请求洪峰?_一个springboot能支持多少并发-CSDN博客
你真的了解Tomcat一键启停吗?-CSDN博客
直击Redis集群痛点:数据倾斜优化实战,打造高效分布式缓存架构_redis集群实现的集群如何解决数据倾斜-CSDN博客