c语言常见的排序方法大概有这些,今天我们所讲的是就是qsort快排的讲解

头文件

qsort的使用
我们先使用msdn查看他的相关资料,得知这个函数的传参请情况
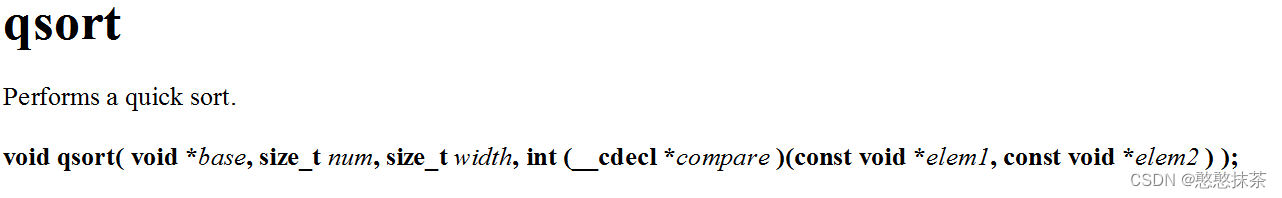
1.void *base
 翻译过来就是将要排序的函数的起始位置/数组首元素地址
翻译过来就是将要排序的函数的起始位置/数组首元素地址
2.size_t num
 翻译过来就是数组个数(要注意这里的个数是指该数组元素的个数,单位是个)
翻译过来就是数组个数(要注意这里的个数是指该数组元素的个数,单位是个)
3.size_t width
 翻译过来就是每个元素大小(以字节计)
翻译过来就是每个元素大小(以字节计)
4. int (__cdecl *compare )(const void *elem1, const void *elem2 )
最后一个参数看起来很长,但实际看起来,他就是一个函数指针 ,我们看看在msdn上他的解释是什么

compare elem1 elem2
[数] 比较函数 指向搜索键的指针 指向要与键进行比较的数组元素的指针

经过阅读以上文章得知,compare函数的作用便是
compare( (void *) elem1, (void *) elem2 );
所以我们便不难实现compare函数
返回类型为int 两个形参全都是void*
int compare(const void* e1, const void* e2)
{return (*(int*)e1 - *(int*)e2);
}以上就是通过msdn查阅资料得知其功能,从而得知其的使用方法
以下排序展示效果
#include <stdio.h>
#include <stdlib.h>
int compare(const void* e1, const void* e2)
{return (*(int*)e1 - *(int*)e2);
}
int main()
{int arr[10] = { 8,5,2,3,6,4,1,7,9,0 };int sz = sizeof(arr) / sizeof(arr[0]);qsort(arr, sz, sizeof(arr[0]),compare);int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}代码运行起来便是如此效果
当然降序只需要将第四个参数的逻辑该反,具体就是如下
int compare(const void* e1, const void* e2)
{return (*(int*)e2 - *(int*)e1);
}qsort排序结构体
上文的使用只在整形数组内使用了,但如果是结构体的话使用会不会又不同呢?
我们带着这个疑问,对上文的代码进行改进,使其可以对结构体排序;
#include <stdio.h>
#include<stdlib.h>
struct stu
{char name[20];int age;char sex[5];
};
int compare(const void* e1, const void* e2)
{return (*(int*)e1 - *(int*)e2);
}
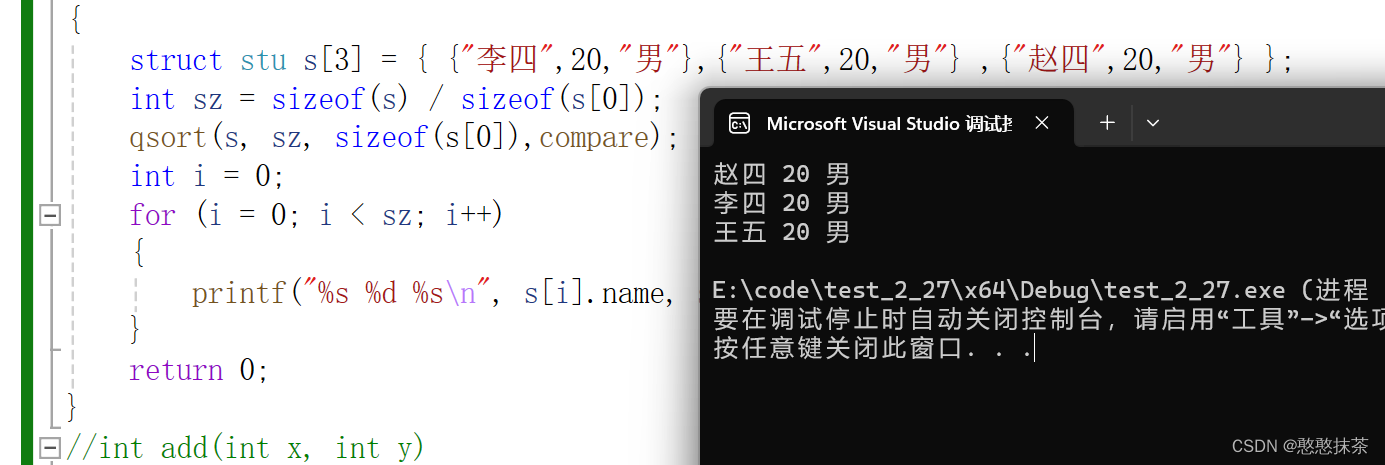
int main()
{struct stu s[3] = { {"李四",20,"男"},{"王五",20,"男"} ,{"赵四",20,"男"} };int sz = sizeof(s) / sizeof(s[0]);qsort(s, sz, sizeof(s[0]),compare);int i = 0; for (i = 0; i < sz; i++){printf("%s %d %s\n", s[i].name, s[i].age, s[i].sex);}return 0;
}
貌似也是可以行的通的,但是思考过后,发现我们是以什么方式排序的呢?我们没有修改第四个形参的函数的内部修改,第四个形参的作用就意在说明我们是利用什么方式在排序,(结构体以名字排序)那么我们就对于不同的类型要使用不同的compare,
以下代码 便是compare 通过name
#include<string.h>
int com_name(const void* e1, const void* e2)
{return (strcmp(((struct stu*)e1)->name, ((struct stu*)e2)->name));
}//这里一定要记得强制类型转换qsort的实现(排序整形)
qsort我们会用以后,那么就要去尝试着怎么自己实现,
我们先看以下冒泡排序的实现方法
void Bubble_sort(int arr[], int size)//int arr[]等价于int *arr
{int j, i;for (i = 0; i < size - 1; i++)//size-1是因为不用与自己比较,所以比的数就少一个{int count = 0;for (j = 0; j < size - 1 - i; j++) //size-1-i是因为每一趟就会少一个数比较{if (arr[j] > arr[j + 1])//这是升序排法,前一个数和后一个数比较,如果前数大则与后一个数换位置{int tem = arr[j];arr[j] = arr[j + 1];arr[j + 1] = tem;count = 1;}}if (count == 0) //如果某一趟没有交换位置,则说明已经排好序,直接退出循环break;}
}
int main()
{int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };int i = 0;Bubble_sort(arr, 10);for (i = 0; i < 10; i++){printf("%d ", arr[i]);}return 0;
}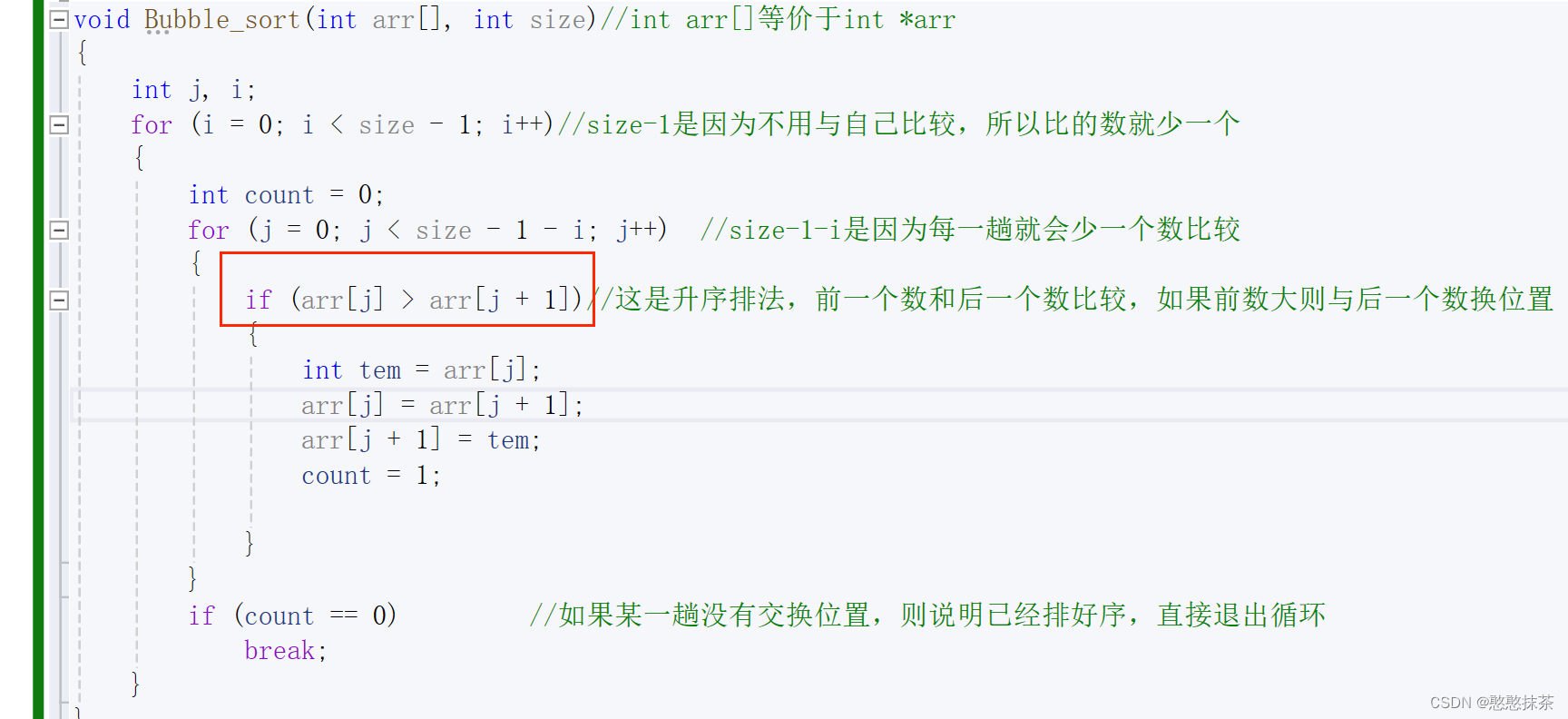
所标红的地方便是相当于qsort里面第四个参数(比较),我们在冒泡排序实现代码基础上进行修改
对于实现者:不知道排序的是什么类型的数组
对于使用者:知道其排序的是什么类型的数组
所以使用去qsort最重要的是对于不同类型使用的com(第四个参数)是不同的
对于第一个参数
msdn上是void*类型的,void*类型的好处就是可以接受任何类型的地址,利用这一点就可以排序任何类型的数组
对于第二个参数跟冒泡排序的参数sz一样,第三个参数与第一个参数结合,不就是解释了每个元素大小(把第一个参数强制类型转化为char*)(也大致就了解是什么类型)达到了冒泡排序第一个参数作用
修改参数:
void Bubble_sort(void* base, size_t num, size_t width, int (*com)(const void* e1, const void* e2)
)大致思路路就是
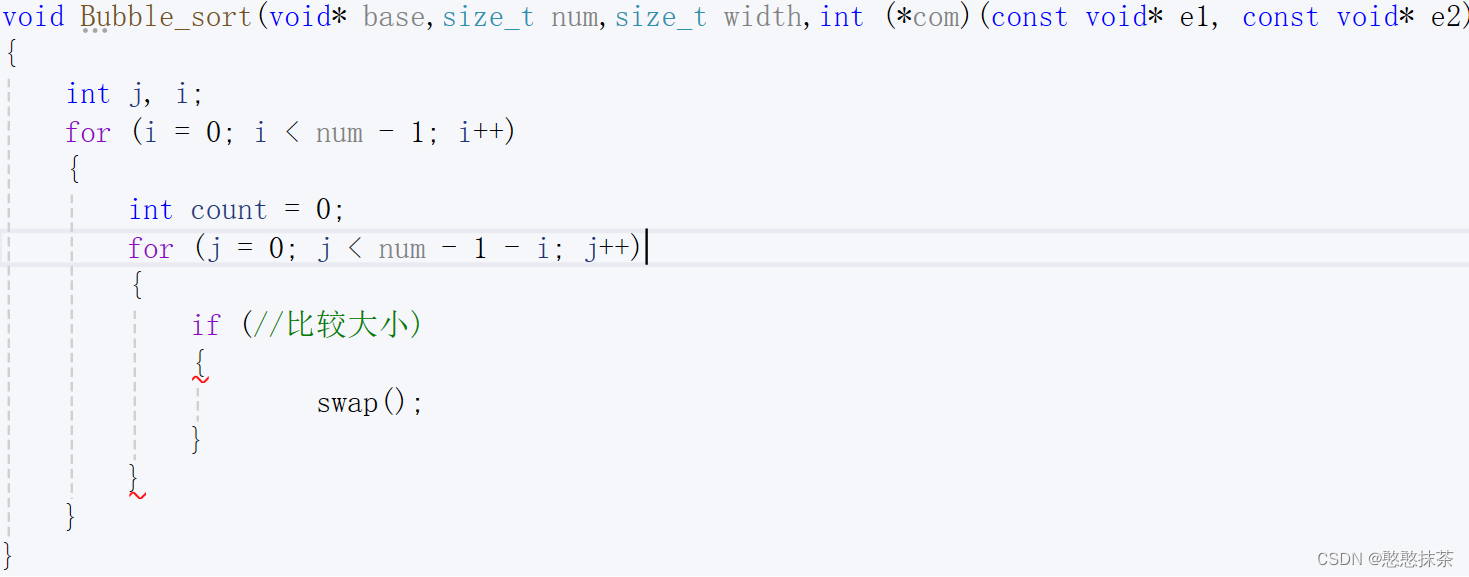
com(比较大小)
if (com((char*)base + j * width, (char*)base + (j + 1) * width)>0)int com(const void* e1, const void* e2)
{return *(int*)e1 - *(int*)e2;
}swap(交换)
swap((char*)base + j * width, (char*)base + (j + 1) * width, width);void swap(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++, buf2++;}
}总结
#include<stdio.h>
void swap(char* buf1, char* buf2, int width)
{int i = 0;for (i = 0; i < width; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++, buf2++;}
}
int com(const void* e1, const void* e2)
{return *(int*)e1 - *(int*)e2;
}
void Bubble_sort(void* base,size_t num,size_t width,int (*com)(const void* e1, const void* e2))
{int j, i;for (i = 0; i < num - 1; i++){int count = 0;for (j = 0; j < num - 1 - i; j++){if (com((char*)base + j * width, (char*)base + (j + 1) * width)>0){swap((char*)base + j * width, (char*)base + (j + 1) * width, width);}}}
}
int main()
{int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };int i = 0;int sz = sizeof(arr) / sizeof(arr[0]);Bubble_sort(arr, sz, sizeof(arr[0]), com);for (i = 0; i < 10; i++){printf("%d ", arr[i]);}return 0;
}
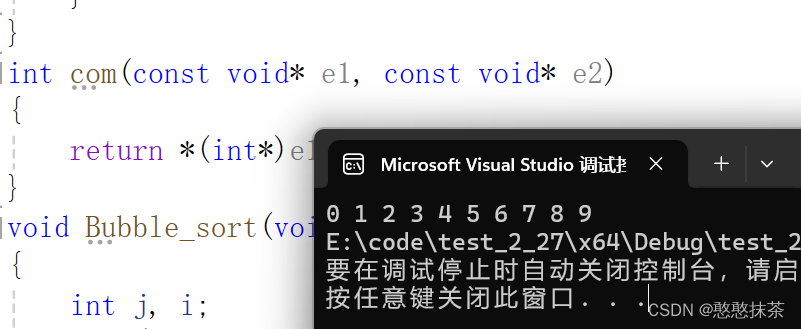
排序结构体的数组只需要改变com函数即可
![[渗透教程]-013-嗅探工具-wireshark操作](/images/no-images.jpg)
![[⑥5G NR]: 无线接口协议,信道映射学习](https://img-blog.csdnimg.cn/direct/5d499b0894094dc89c24f1f19051c6ee.png)