清华大学驭风计划
因为篇幅原因实验答案分开上传,后续持续更新中,请敬请期待
如果需要详细的实验报告或者代码可以私聊博主
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
实验1: Word2Vec&TranE的实现
案例简介

Word2Vec是词嵌入的经典模型,它通过词之间的上下文信息来建模词的相似度。TransE是知识表示学习领域的经典模型,它借鉴了Word2Vec的思路,用“头实体+关系=尾实体”这一简单的训练目标取得了惊人的效果。本次任务要求在给定的框架中分别基于Text8和Wikidata数据集实现Word2Vec和TransE,并用具体实例体会词向量和实体/关系向量的含义。
A ,Word2Vec实现
在这个部分,你需要基于给定的代码实现Word2Vec,在Text8语料库上进行训练,并在给定的WordSim353数据集上进行测试
WordSim353是一个词语相似度基准数据集,在WordSim353数据集中,表格的第一、二列是一对单词,第三列中是该单词对的相似度的人工打分(第三列也已经被单独抽出为ground_truth.npy)。我们需要用我们训练得到的词向量对单词相似度进行打分,并与人工打分计算相关性系数,总的来说,越高的相关性系数代表越好的词向量质量。
我们提供了一份基于gensim的Word2Vec实现,请同学们阅读代码并在Text8语料库上进行训练, 关于gensim的Word2Vec模型更多接口和用法,请参考[2]。
由于gensim版本不同,模型中的size参数可能需要替换为vector_size(不报错的话不用管)
运行`word2vec.py` 后,模型会保存在`word2vec_gensim`中,同时代码会加载WordSim353数据集,进行词对相关性评测,得到的预测得分保存在score.npy文件中
之后在Word2Vec文件夹下运行 ``python evaluate.py score.npy``, 程序会自动计算score.npy 和ground_truth.npy 之间的相关系数得分,此即为词向量质量得分。
任务
- 运行`word2vec.py`训练Word2Vec模型, 在WordSim353上衡量词向量的质量。
- 探究Word2Vec中各个参数对模型的影响,例如词向量维度、窗口大小、最小出现次数。
- (选做)对Word2Vec模型进行改进,改进的方法可以参考[3],包括加入词义信息、字向量和词汇知识等方法。请详细叙述采用的改进方法和实验结果分析。
快速上手(参考)
在Word2Vec文件夹下运行 ``python word2vec.py``, 即可成功运行, 运行生成两个文件 word2vec_gensim和score.npy。
B, TransE实现
这个部分中,你需要根据提供的代码框架实现TransE,在wikidata数据集训练出实体和关系的向量表示,并对向量进行分析。
在TransE中,每个实体和关系都由一个向量表示,分别用$h, r,t$表示头实体、关系和尾实体的表示向量,首先对这些向量进行归一化
h=h/||h||
r=r/||r||
t=t/||t||
则得分函数(score function)为
f(h,r,t)=||h+r-t||
其中||\cdot||表示向量的范数。得分越小,表示该三元组越合理。
在计算损失函数时,TransE采样一对正例和一对负例,并让正例的得分小于负例,优化下面的损失函数
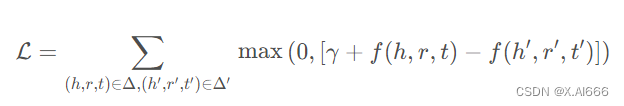
其中(h,r,t), (h',r',t')分别表示正例和负例,gamma是一个超参数(margin),用于控制正负例的距离。
任务
- 在文件`TransE.py`中,你需要补全`TransE`类中的缺失项,完成TransE模型的训练。需要补全的部分为:
- `_calc()`:计算给定三元组的得分函数(score function)
- `loss()`:计算模型的损失函数(loss function)
- 完成TransE的训练,得到实体和关系的向量表示,存储在`entity2vec.txt`和`relation2vec.txt`中。
- 给定头实体Q30,关系P36,最接近的尾实体是哪些?
- 给定头实体Q30,尾实体Q49,最接近的关系是哪些?
- 在 https://www.wikidata.org/wiki/Q30 和 https://www.wikidata.org/wiki/Property:P36 中查找上述实体和关系的真实含义,你的程序给出了合理的结果吗?请分析原因。
- (选做)改变参数`p_norm`和`margin`,重新训练模型,分析模型的变化。
快速上手(参考)
在TransE文件夹下运行 ``python TransE.py``, 可以看到程序在第63行和第84行处为填写完整而报错,将这两处根据所学知识填写完整即可运行成功代码(任务第一步),然后进行后续任务。
评分标准
请提交代码和实验报告,评分将从代码的正确性、报告的完整性和任务的完成情况等方面综合考量。
参考资料
[1] https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
[2] https://radimrehurek.com/gensim/models/word2vec.html
[3] A unified model for word sense representation and disambiguation. in Proceedings of EMNLP, 2014.