目录
ES高级查询Query DSL
match_all
返回源数据_source
返回指定条数size
分页查询from&size
指定字段排序sort
术语级别查询
Term query术语查询
Terms Query多术语查询
exists query
ids query
range query范围查询
prefix query前缀查询
wildcard query通配符查询
fuzzy query模糊查询
ES高级查询Query DSL
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specified Language 领域专用语言),Query DSL是利用Rest API传递JSON格式的请求体(RequestBody)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大更简洁。
语法:
GET /es_db/_doc/_search {json请求体数据}
可以简化为下面写法
GET /es_db/_search {json请求体数据}示例
#无条件查询,默认返回10条数据
GET /user/_search
{"query":{"match_all":{}}
}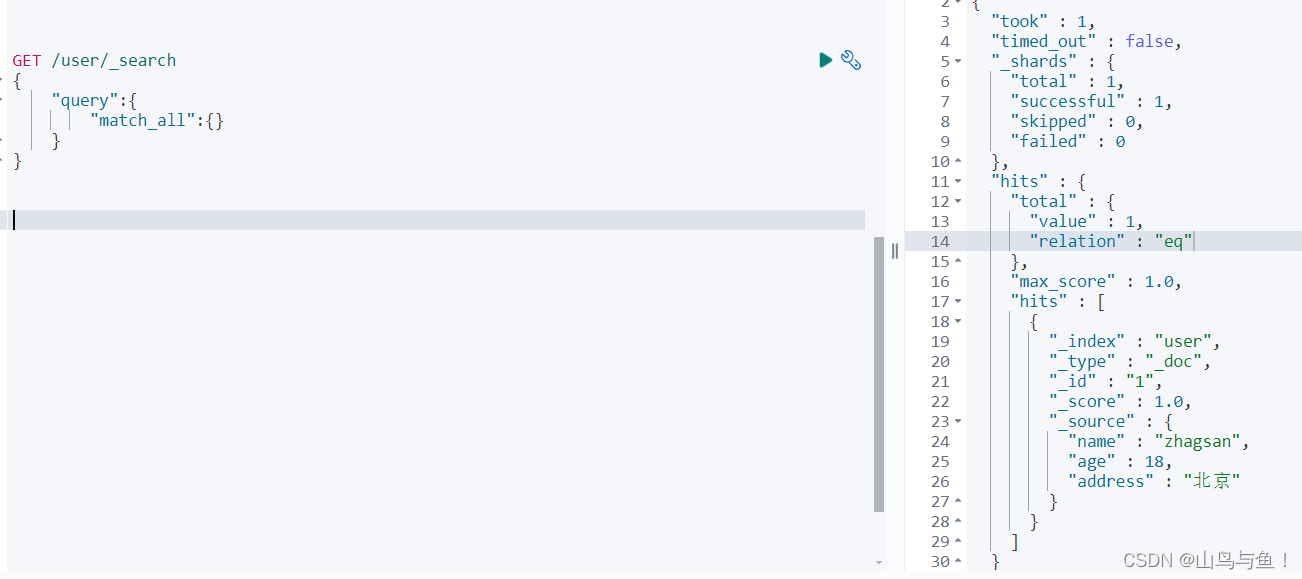
took:花费的时间
total.value:符合条件的总文档
hits:结果集,默认前10个文档
_index:索引名
_id:文档的id
_score:相关度评分
source:文档原生信息
示例数据
#指定ik分词器
PUT /user
{"settings" : {"index" : {"analysis.analyzer.default.type": "ik_max_word"}}
}# 创建文档,指定id
PUT /user/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "北京",
"remark": "java"
}
PUT /user/_doc/2
{
"name": "李四",
"sex": 1,
"age": 28,
"address": "南京",
"remark": "java"
}PUT /user/_doc/3
{
"name": "王五",
"sex": 0,
"age": 26,
"address": "广州白云山",
"remark": "php"
}PUT /user/_doc/4
{
"name": "赵六",
"sex": 0,
"age": 22,
"address": "长沙",
"remark": "python"
}PUT /user/_doc/5
{
"name": "张龙",
"sex": 0,
"age": 19,
"address": "天津",
"remark": "java"
} PUT /user/_doc/6
{
"name": "赵虎",
"sex": 1,
"age": 32,
"address": "长沙",
"remark": "java"
} PUT /user/_doc/7
{
"name": "李虎",
"sex": 1,
"age": 32,
"address": "广州",
"remark": "java"
}PUT /user/_doc/8
{
"name": "张星",
"sex": 1,
"age": 32,
"address": "武汉",
"remark": "golang"
}match_all
使用match_all,匹配所有文档,默认只会返回10条数据。
原因:_search查询默认采用的是分页查询,每页记录数size的默认值为10。如果想显示更多数据,指定size。
GET /user/_search
等同于
GET /user/_search
{
"query":{
"match_all":{}
}
}返回源数据_source
# 返回指定字段
GET /user/_search
{"query": {"match_all": {}},"_source": ["name","address"]
}#在查询中过滤
#不查看源数据,仅查看元字段
{"_source": false,"query": {...}
}#只看以obj.开头的字段
{"_source": "obj.*","query": {...}
}返回指定条数size
size 关键字:指定查询结果中返回指定条数。默认返回值10条。
GET /user/_search
{"query": {"match_all": {}},"size": 100
}分页查询from&size
size:显示应该返回的结果数量,默认是 10
from:显示应该跳过的初始结果数量,默认是 0
from 关键字用来指定起始返回位置,和size关键字连用可实现分页效果
GET /user/_search
{"query": {"match_all": {}},"from": 0,"size": 5
}指定字段排序sort
注意:会让得分失效
GET /user/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}]
}#排序,分页
GET /user/_search
{"query": {"match_all": {}},"sort": [{"age": "desc"}],"from": 10,"size": 5
}术语级别查询
术语级别查询(Term-Level Queries)指的是搜索内容不经过文本分析直接用于文本匹配,这个过程类似于数据库的SQL查询,搜索的对象大多是索引的非text类型字段。Elasticsearch 中的一些术语级别查询示例包括 term、terms 和 range 查询。
Term query术语查询
术语查询直接返回包含搜索内容的文档,常用来查询索引中某个类型为keyword的文本字段,类似于SQL的“=”查询,使用十分普遍。
注意:最好不要在term查询的字段中使用text字段,因为text字段会被分词,这样做既没有意义,还很有可能什么也查不到。
# 对bool,日期,数字,结构化的文本可以利用term做精确匹配
# term 精确匹配
GET /user/_search
{"query": {"term": {"age": {"value": 28}}}
}# 采用term精确查询, 查询字段映射类型为keyword
GET /user/_search
{"query":{"term": {"address.keyword": {"value": "广州"}}}
}在ES中,Term查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能。
将Query 转成 Filter,忽略TF-IDF计算,避免相关性算分的开销,Filter可以有效利用缓存。
GET /user/_search
{"query": {"constant_score": {"filter": {"term": {"address.keyword": "广州"}}}}
}term处理多值字段时,term查询是包含,不是等于。
POST /employee/_bulk
{"index":{"_id":1}}
{"name":"小明","interest":["跑步","篮球"]}
{"index":{"_id":2}}
{"name":"小红","interest":["跳舞","画画"]}
{"index":{"_id":3}}
{"name":"小丽","interest":["跳舞","唱歌","跑步"]}POST /employee/_search
{"query": {"term": {"interest.keyword": {"value": "跑步"}}}
}Terms Query多术语查询
Terms query用于在指定字段上匹配多个词项(terms)。它会精确匹配指定字段中包含的任何一个词项。
POST /user/_search
{"query": {"terms": {"remark.keyword": ["java", "php"]}}
}exists query
在Elasticsearch中可以使用exists进行查询,以判断文档中是否存在对应的字段。
#查询索引库中存在remarks字段的文档数据
GET /user/_search
{"query": {"exists": {"field": "remark"}}
}ids query
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档。
GET /user/_search
{"query": {"ids": {"values": [1,2]}}
}range query范围查询
- range:范围关键字
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时
POST /user/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}#日期范围比较
DELETE /product
POST /product/_bulk
{"index":{"_id":1}}
{"price":100,"date":"2021-01-01","productId":"XHDK-1293"}
{"index":{"_id":2}}
{"price":200,"date":"2022-01-01","productId":"KDKE-5421"}GET /product/_mappingGET /product/_search
{"query": {"range": {"date": {"gte": "now-2y"}}}
}prefix query前缀查询
它会对分词后的term进行前缀搜索。
prefix的原理:需要遍历所有倒排索引,并比较每个term是否以所指定的前缀开头。
GET /user/_search
{"query": {"prefix": {"address": {"value": "广州"}}}
}wildcard query通配符查询
通配符查询:工作原理和prefix相同,只不过它不是只比较开头,它能支持更为复杂的匹配模式。
GET /user/_search
{"query": {"wildcard": {"address": {"value": "*京*"}}}
}fuzzy query模糊查询
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。
fuzzy 查询会用到两个很重要的参数,fuzziness,prefix_length
1. fuzziness(模糊度):fuzziness参数指定了允许的编辑距离(Levenshtein距离)。编辑距离是指在两个字符串之间,从一个字符串转换到另一个字符串所需的最小编辑操作数(插入、删除、替换)。在Fuzzy查询中,编辑距离表示允许的最大差异数。较大的编辑距离意味着更宽松的匹配条件,允许更多的不匹配。常见的编辑距离值包括0、1、2,其中0表示精确匹配,1表示允许一个字符的差异,2表示允许两个字符的差异,以此类推。
2. prefix_length(前缀长度):prefix_length参数用于控制在执行Fuzzy查询时要忽略的术语的前缀长度。在实际文本中,可能存在大量共享前缀的术语,而这些前缀不应该影响Fuzzy匹配。通过设置prefix_length参数,你可以指定要忽略的前缀长度,以便更精确地匹配剩余的部分。较大的前缀长度可以提高查询性能,因为它减少了需要比较的字符数。
GET /user/_search
{"query": {"fuzzy": {"address": {"value": "呗京","fuzziness": 1 }}}
}