Swin Transformer:将卷积网络和 Transformer 结合
- 网络结构
- 层次化设计
- Swin Transformer 块
- W-MSA、SW-MSA
- 环状 SW-MSA
前置知识:ViT:视觉 Transformer
论文地址:https://arxiv.org/abs/2106.13230
代码地址:https://github.com/SwinTransformer/Video-Swin-Transformer
网络结构
Transformer 在视觉上的问题:
- 如果图像尺寸变化大,性能不稳定,时好时坏
- 在像素点多的图像上,全局注意力计算量要大于 CNN
Swin 是滑动窗口的缩写。
用滑动窗口让注意力机制,在局部范围内(减少计算量),同时跨窗口的连接(保持全局信息)。
Swin Transformer 和 ViT 对比图:
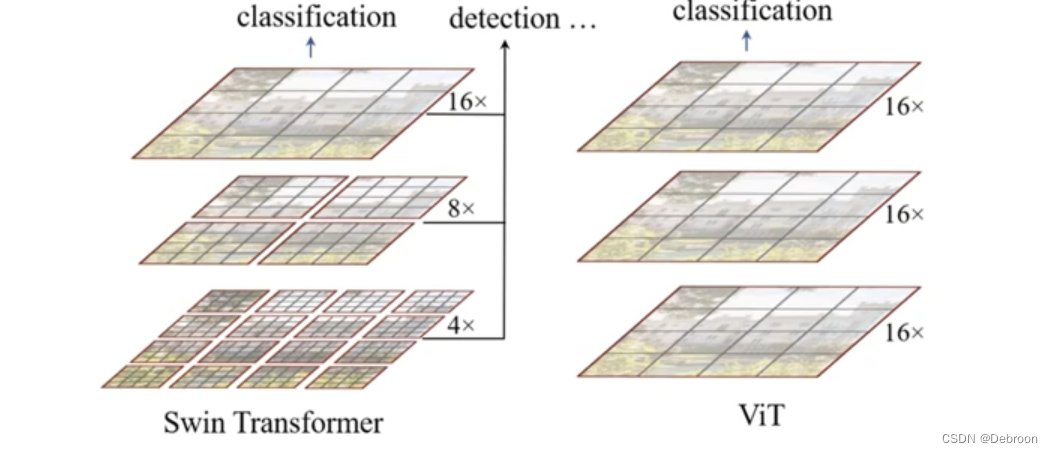
滑动窗口能实现卷积网络的效果,对局部特征的提取,大大节省计算量。
层次化设计
网络结构,采用层次化设计:

图(a),从左往右看:
- Patch Partition:先把图像切分为固定大小的图像块
- Linear Embeding:进行嵌入位置向量
- Basic Layer:再分 4 个阶段,每个阶段都在缩小分辨率(从 1 4 \frac{1}{4} 41 到 1 8 \frac{1}{8} 81、 1 16 \frac{1}{16} 161、 1 32 \frac{1}{32} 321),感受野会逐步扩大,从关注线条、斑点、色彩,到眼睛、鼻子、头发,再到整个脸

图像没变,Patch 变大了,这样就改变了注意力的区域,虽然越来越大,加入邻域要素,但不是全局注意力。
- Patch Merging:每个阶段都会先合并图像块(降低图像分辨率)
- Swin Transformer Block:基本构建单元,由局部窗口交互、全局窗口交互和转换层组成,用于在局部和全局范围内进行特征交互。
Swin Transformer 块
图 (b),就是 Swin Transformer Block 具体细节:
- MLP:多层感知器,就是一个分类网络
- LN:层归一化
- W-MSA:窗口多头自注意力模块,在窗口范围内做attention
- SW-MSA:滑动窗口多头自注意力模块,在滑动窗口范围内做attention
W-MSA、SW-MSA
Block 核心是用了 W-MSA、SW-MSA:
- W-MSA 是为了减少计算量,注意力限制在一个小窗口内,当然窗口会越来越大,考虑邻域要素。
- SW-MSA 解决的是注意力机制局部化,导致的信息、特征损失,信息和信息之间没有交流。
好像读一本书:
-
首先,W-MSA可以将你的注意力限制在一个小窗口内,比如每次只关注故事中的一小段内容。这样,就可以更集中地理解每个人物和事件之间的关系,而不需要一次性地理解整个故事。
-
接着,SW-MSA可以让你通过滑动窗口的方式,将不同窗口中的内容进行比较和交互。这样,就能够捕捉到故事中的重要事件和关键人物,不受它们在故事中的具体位置影响。可以在不同位置观察故事中的情节,而不会错过任何重要的细节。
SW-MSA 的设计遇到问题,如果只是简单的将原始的窗口向右下角移动2个patch,会导致每个窗口大小不一样,且每个窗口内的patch数量不同,既加重了模型的计算复杂度,也不能并行计算。
环状 SW-MSA
作者提出了,环状 SW-MSA。
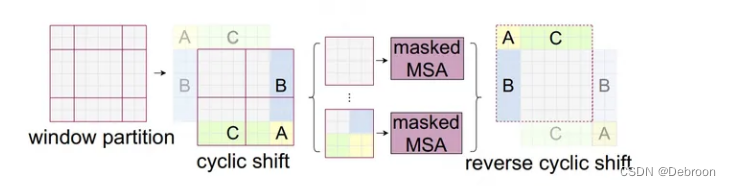
最开始是9个不均匀的patch。
为了均匀,将原来的 A、B、C 部分做一个旋转拼接,就又可以恢复成一个有 4 个窗口,且patch数量均匀的数据了。
- cyclic shift:将 A、B、C 移动到反向位置(窗口补齐),保证窗口大小一致(原来是 9 个不规则窗口,方便并行计算)
- MSA 掩码:把原本不属于一个窗口的数据,不会得到较高的注意力(绿色C、蓝色B、黄色A 的值都低)
Masked Attention 计算过程:

左图的 Window0 窗口,patch没有任何拼接处理,因此不需要做任何掩码(masked)操作,可以正常做attention。
- 右图的 window0 的颜色为全黑,意味着无需任何掩码操作。
左图的 Window2 这个窗口,标号为 3 的来自同一批patch,标号为 6 的来自环状移动过来的另一批patch。
因此 3 和 6 之间是不能做 attention 的,这意味着如果 attention score 是由 3 的一块 patch 和 6 的一块 patch 计算得来,我们就需要把这个score设置成 -100,这样一来在后续做softmax时,对应位置的结果就可以小到忽略不计,以此来取得遮掩效果。
- 右图的 window2 的黄色部分表示不需要做 mask 的分数,黑色部分表示需要做 mask 的分数。
这代表什么呢?
- 相同区域之间做 MSA 操作,就没掩码
- 不同区域之间做 MSA 操作,就带掩码
环状 SW-MSA 不仅能跨窗口连接,还支持并行计算。