继上一章:
CSDN
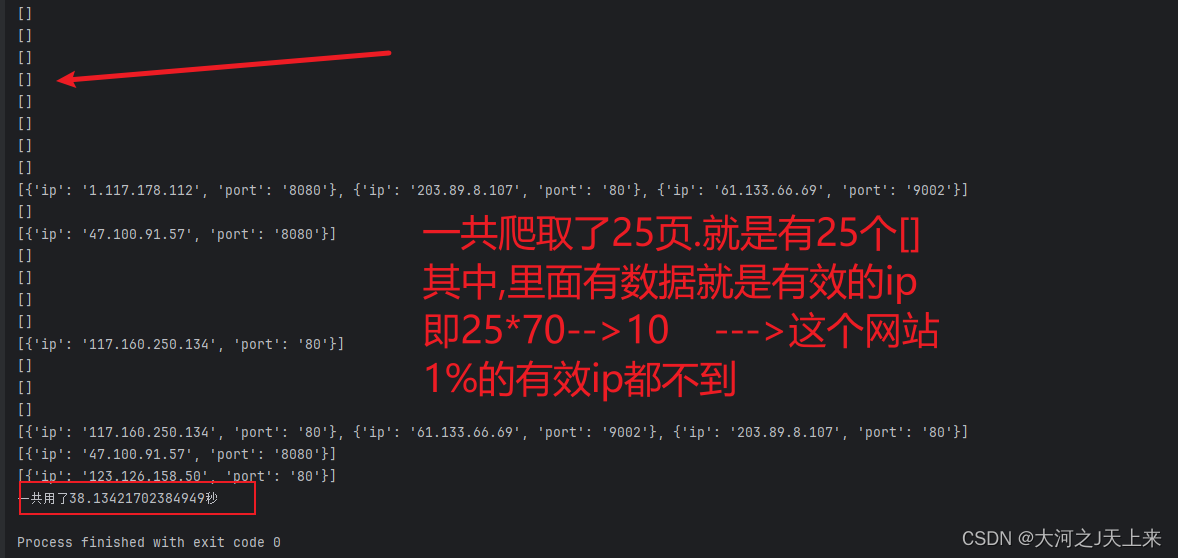
本次需要做的是进行有效ip的验证!
我们知道,从网页上爬取上千上万个ip之后,因为是免费的代理,所以,对这上千上万个ip进行验证有效性就需要考虑效率上的问题了;
而验证ip有效性的唯一办法,就是通过对网络发起请求;如果state=200,就是有效,否则就是无效;
而上千万次的发起请求,如果通过多线程去做,势必会增加服务器的压力;
因此,只能通过异步去验证IP是否有效:
async def check_ip(session, proxy):"""...略去其它注释,同时函数的docstring也要更新..."""proxy_url = f"http://{proxy['ip']}:{proxy['port']}"try:async with session.get(url="http://httpbin.org/ip", timeout=1.5, proxy=proxy_url) as response:# 返回原始代理信息和有效性状态return proxy, response.status == 200except (aiohttp.ClientError, asyncio.TimeoutError):# 返回原始代理信息和无效状态return proxy, Falseasync def check_ip_main(proxies):"""检查IP有效性并返回所有有效的IP列表"""async with aiohttp.ClientSession() as session:tasks = [asyncio.create_task(check_ip(session, proxy)) for proxy in proxies]valid_proxies = [] # 初始化一个空列表来存放有效的代理for task in asyncio.as_completed(tasks):proxy, is_valid = await task # 这里我们期望 check_ip 也返回对应的 proxy 信息if is_valid:#当返回来是True的时候,他就会加入到valid_proxies里面;valid_proxies.append(proxy)return valid_proxies通过这两个方法:
首先:
一页url假设有100个ip,我们获取他之后,他就是成这样的格式:[{ip:122.250.32.1,port:5212},{///}...]
所以,我们将它添加到异步列表里,再进行单个检查,返回true\false 就可以定义他的有效性了!
最后,将得到的有效ip添加到redis里即可;
这里是本章+上章的全部代码:
import logging
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
from db.redis_task import temp_for_ippoollogger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)#请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}# 异步获取URL的函数
async def fetch_url(session, url):try:async with session.get(url, timeout=3,headers=headers) as response:return await response.text()except aiohttp.ClientError as e:logger.exception("爬取相关url出错: %s", url)async def parse_html(html):'''解析代码,如果标题包含'89免费代理',如果包含"快代理"--->就是快代理:param html::return:'''soup = BeautifulSoup(html, 'html.parser')title = soup.find('title')if '89免费代理' in title.getText():table = soup.find('table', class_='layui-table')tbody = table.find('tbody')proxy_list = []rows = tbody.find_all('tr')for row in rows:proxy = {}cells = row.find_all('td')proxy["ip"] = cells[0].text.strip()proxy["port"] = cells[1].text.strip()proxy_list.append(proxy)return proxy_listasync def check_ip(session, proxy):"""...略去其它注释,同时函数的docstring也要更新..."""proxy_url = f"http://{proxy['ip']}:{proxy['port']}"try:async with session.get(url="http://httpbin.org/ip", timeout=1.5, proxy=proxy_url) as response:# 返回原始代理信息和有效性状态return proxy, response.status == 200except (aiohttp.ClientError, asyncio.TimeoutError):# 返回原始代理信息和无效状态return proxy, Falseasync def check_ip_main(proxies):"""检查IP有效性并返回所有有效的IP列表"""async with aiohttp.ClientSession() as session:tasks = [asyncio.create_task(check_ip(session, proxy)) for proxy in proxies]valid_proxies = [] # 初始化一个空列表来存放有效的代理for task in asyncio.as_completed(tasks):proxy, is_valid = await task # 这里我们期望 check_ip 也返回对应的 proxy 信息if is_valid:#当返回来是True的时候,他就会加入到valid_proxies里面;valid_proxies.append(proxy)return valid_proxies# 异步操作,在其中打开会话和调用fetch任务
async def main(urls):async with aiohttp.ClientSession() as session:tasks = [fetch_url(session, url) for url in urls]for future in asyncio.as_completed(tasks):html = await futureif html:proxys = await parse_html(html)# 适当等待chek_ip_main 协程proxys_list= await check_ip_main(proxys)print(proxys_list)# URL 列表
urls = ["https://www.89ip.cn/index_{}.html".format(i+1) for i in range(25)]# 运行协程
stat =time.time()
asyncio.run(main(urls))
end =time.time()print(f'一共用了{(end-stat)}秒')我做的效果图: