目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据爬取及处理
- 2. 模型训练及保存
- 1)协同过滤
- 2)矩阵分解
- 3)LDA主题模型
- 3. 接口实现
- 1)流行电影推荐
- 2)相邻用户推荐
- 3)相似内容推荐
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
前段时间,博主分享过关于一篇使用协同过滤算法进行智能电影推荐系统的博文《基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集》,有读者反映该项目有点复杂,于是我决定再给大家分享个使用机器学习算法简单实现电影推荐的项目。
本项目基于Movielens数据集,采用协同过滤、矩阵分解以及建立LDA主题模型等机器学习算法,旨在设计和训练一个合适的智能电影推荐模型。最终的目标是根据电影的相似性以及用户的历史行为,生成一个个性化的电影推荐列表,从而实现网站为用户提供精准电影推荐的功能。
首先,项目收集了Movielens数据集,其中包含了大量用户对电影的评分和评论。这个数据集提供了有关用户和电影之间互动的信息,是推荐系统的核心数据。
然后,项目使用协同过滤算法,这可以是基于用户的协同过滤(User-Based Collaborative Filtering)或基于item的协同过滤(Item-Based Collaborative Filtering)。这些算法分析用户之间的相似性或电影之间的相似性,以提供个性化推荐。
此外,矩阵分解技术也被应用,用于分解用户-电影交互矩阵,以发现潜在的用户和电影特征。这些特征可以用于更准确地进行推荐。
另外,项目还使用了LDA主题模型,以理解电影的主题和用户的兴趣。这有助于更深入地理解电影和用户之间的关联。
最终,根据电影的相似性和用户的历史行为,系统生成了一个个性化的电影推荐列表。这个列表可以根据用户的兴趣和偏好提供电影推荐,从而提高用户体验。
总结来说,这个项目结合了协同过滤、矩阵分解和主题建模等技术,以实现一个个性化电影推荐系统。这种系统有助于提高用户在网站上的互动和满意度,同时也有助于电影网站提供更精准的内容推荐。
总体设计
本部分包括系统整体结构图和系统流程图。
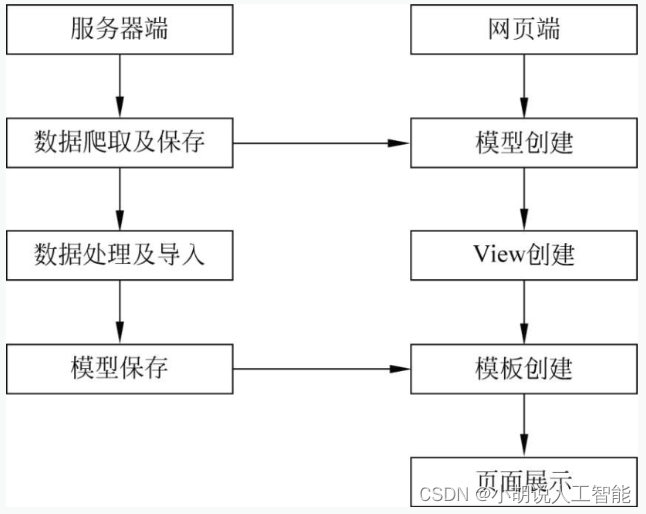
系统整体结构图
系统整体结构如图所示。
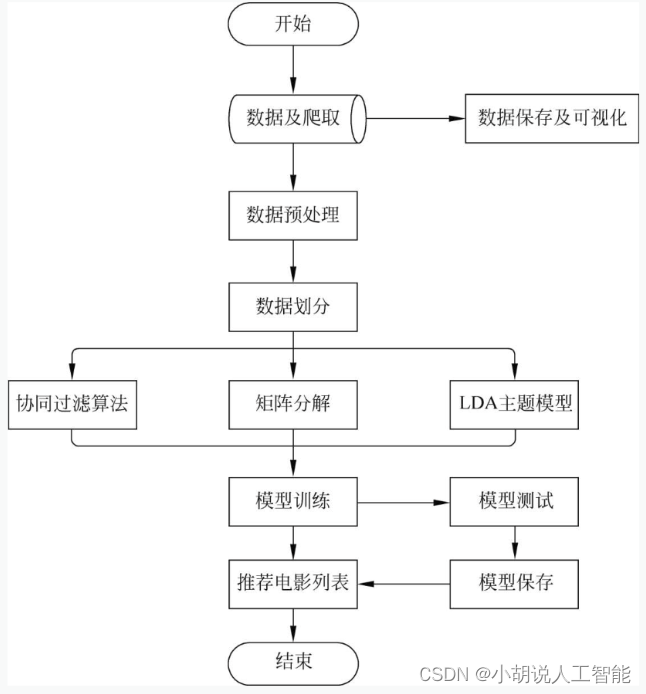
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、Pycharm 环境及数据库环境。
详见博客。
模块实现
本项目包括5个模块:数据爬取及处理、模型训练及保存、接口实现、收集数据、界面设计。下面分别介绍各模块的功能及相关代码。
1. 数据爬取及处理
详见博客。
2. 模型训练及保存
输入命令构建模型并训练:
python -m Builder.item_similarity_calculator
python -m Builder.matrix_factorization_calculator
python -m Builder.lda_model_calculator
以上三行命令分别代表基于协同过滤、矩阵分解、LDA主题模型。
1)协同过滤
相关代码如下:
import os
from tqdm import tqdm
from datetime import datetime
import pandas as pd
import psycopg2
from scipy.sparse import coo_matrix, csr_matrix
import numpy as npos.environ.setdefault("DJANGO_SETTINGS_MODULE", "Recs.settings")
import django
django.setup()from Analytics.models import Rating
from Recs import settingsclass ItemSimilarityMatrixBuilder(object):def __init__(self, min_overlap=15, min_sim=0.2):# 同时对 item1 和 item2 有过评分的最小用户数self.min_overlap = min_overlap# 最小相似度self.min_sim = min_simself.db = settings.DATABASES['default']['ENGINE']# ratings 评分数据,save 是否保存到数据库,默认保存def build(self, ratings, save=True):print("Calculating similarities ... using {} ratings".format(len(ratings))start_time = datetime.now()print("Creating ratings matrix")ratings['rating'] = ratings['rating'].astype(float)# 计算每个 user_id 的平均评分,并做归一化处理ratings['avg'] = ratings.groupby('user_id')['rating'].transform(lambda x: normalize(x))# 把 user_id,movie_id 转为 pandas 的类别,以便去重ratings['avg'] = ratings['avg'].astype(float)ratings['user_id'] = ratings['user_id'].astype('category')ratings['movie_id'] = ratings['movie_id'].astype('category')# 构建稀疏评分矩阵,没有评分的数据全部用 0 填充coo = coo_matrix((ratings['avg'].astype(float),(ratings['movie_id'].cat.codes.copy(),ratings['user_id'].cat.codes.copy()))# 计算两个 item 间的重叠个数,同时对 item1 和 item2 有过评分的用户数print("Calculating overlaps between the items")overlap_matrix = coo.astype(bool).astype(int).dot(coo.transpose().astype(bool).astype(int))# 重叠部分大于 min_overlap 的 item 数量number_of_overlaps = (overlap_matrix > self.min_overlap).count_nonzero()print("Overlap matrix leaves {} out of {} with {}".format(number_of_overlaps, overlap_matrix.count_nonzero(), self.min_overlap))print("Rating matrix (size {}x{}) finished, in {} seconds".format(coo.shape[0], coo.shape[1], datetime.now() - start_time))sparsity_level = 1 - (ratings.shape[0] / (coo.shape[0] * coo.shape[1]))print("Sparsity level is {}".format(sparsity_level))start_time = datetime.now()# 初始化一个为 0 的相似度矩阵print("Calculating similarity between the items")cor = self.calculating_similarity(coo)# cor = cosine_similarity(coo, dense_output=False)# print(type(cor))# print(cor)# 相似度大于最小相似度的元素,进行对应位置相乘cor = cor.multiply(cor > self.min_sim)# 相似度大于最小重叠度的元素,进行对应位置相乘cor = cor.multiply(overlap_matrix > self.min_overlap)print(cor)movies = dict(enumerate(ratings['movie_id'].cat.categories))print('Correlation is finished, done in {} seconds'.format(datetime.now() - start_time))if save:start_time = datetime.now()print('save starting')if self.db == 'django.db.backends.postgresql':self.save_similarity(cor, movies)print('save finished, done in {} seconds'.format(datetime.now() - start_time))return cor, movies# 计算相似度优化算法,从 SKlearn 得到启发def calculating_similarity(self, coo):# 稀疏矩阵转 Numpy 数组data_array = coo.toarray()data_array = check_array(data_array)# 爱因斯坦求和约定,即对两个矩阵按元素位置对应相乘,按行求和norms = np.einsum('ij,ij->i', data_array, data_array)np.sqrt(norms, norms)norms[norms == 0.0] = 1.0data_array /= norms[:, np.newaxis]# 运算之后把 numpy 的多维数组或矩阵转为 scipy 的稀疏矩阵进行计算,否则汇报内存溢出array_sparse = csr_matrix(data_array)sim_matrix = array_sparse @ array_sparse.transpose()return sim_matrixdef save_similarity(self, sim_matrix, index, created=datetime.now()):# 设置开始时间start_time = datetime.now(print('truncating table in {} seconds'.format(datetime.now() - start_time))sims = []no_saved = 0start_time = datetime.now()print('instantiation of coo_matrix in {} seconds'.format(datetime.now() - start_time))# 计算相似度矩阵coo = coo_matrix(sim_matrix)csr = coo.tocsr()query="insert into similarity (created,source,target,similarity) values %s;"conn = self.get_connect()cur = conn.cursor()cur.execute('truncate table similarity')print('{} similarities to save'.format(coo.count_nonzero()))# 初始化相似度矩阵xs, ys = coo.nonzero()for x, y in tqdm(zip(xs, ys), leave=True):if x == y:continuesim = csr[x, y]# 寻找相似度最高的用户if sim < self.min_sim:continueif (len(sims)) == 500000:psycopg2.extras.execute_values(cur, query, sims)sims = []print("{} saved in {}".format(no_saved, datetime.now() - start_time))# 创建相似度矩阵new_similarity = (str(created), index[x], index[y], sim)no_saved += 1sims.append(new_similarity)psycopg2.extras.execute_values(cur, query, sims, template=None, page_size=1000)conn.commit()print('{} Similarity items saved, done in {} seconds'.format(no_saved, datetime.now() - start_time))@staticmethod# 获取用户名和密码def get_connect():if settings.DATABASES['default']['ENGINE'] == 'django.db.backends.postgresql':dbUsername = settings.DATABASES['default']['USER']dbPassword = settings.DATABASES['default']['PASSWORD']dbName = settings.DATABASES['default']['NAME']# 用户名和密码校验conn_str = "dbname={} user={} password={}".format(dbName, dbUsername, dbPassword)conn = psycopg2.connect(conn_str)return conn# 检查数据类型def check_array(array, dtype="numeric", order=None):array_orig = arraydtype_numeric = isinstance(dtype, str) and dtype == "numeric"dtype_orig = getattr(array, "dtype", None)if dtype_numeric:if dtype_orig is not None and dtype_orig.kind == "O":# 如果输入为一个对象,转换为浮点型dtype = np.float64else:dtype = Noneif np.may_share_memory(array, array_orig):array = np.array(array, dtype=dtype, order=order)return array# 归一化def normalize(x):x = x.astype(float)x_sum = x.sum() # 计算 value 的和x_num = x.astype(bool).sum() # 计算大于 0 的元素x_mean = 0if x_num > 0:x_mean = x_sum / x_num # 计算均值if x_num == 1 or x.std() == 0:return 0.0return (x - x_mean) / (x.max() - x.min())# 加载评分数据def load_all_ratings(min_ratings=1):# 提取相关列的数据columns = ['user_id', 'movie_id', 'rating', 'type']ratings_data = Rating.objects.filter(user_id__range=(0, 30000)).values(*columns)ratings = pd.DataFrame.from_records(ratings_data, columns=columns)# 通过 user_id 分类,统计每个 user_id 评分过的 item 数量user_count = ratings[['user_id', 'movie_id']].groupby('user_id').count()user_count = user_count.reset_index()# 取出评分 item 数量超过 min_ratings 的所有 user_iduser_ids = user_count[user_count['movie_id'] > min_ratings]['user_id']# 取出 user_ids 的评分数据记录ratings = ratings[ratings['user_id'].isin(user_ids)]# 将评分数据转换成 float 类型ratings['rating'] = ratings['rating'].astype(float)return ratingsdef main():print("Calculation of item similarity")all_ratings = load_all_ratings()ItemSimilarityMatrixBuilder().build(all_ratings)if __name__ == '__main__':main()2)矩阵分解
相关代码如下:
#导入需要的包
import numpy as np
import pandas as pd
import os
import psycopg2
from tqdm import tqdm
from datetime import datetime
from scipy.sparse import coo_matrix
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "Recs.settings")
import django
django.setup()
#导入评分数据
from Analytics.models import Rating
from Recs import settings
class MatrixFactorization(object):
#创建评分矩阵def __init__(self, min_sim=0.1):self.min_sim = min_simself.db = settings.DATABASES['default']['ENGINE']def train(self, c_ui, factors = 50, regularization = 0.01, iterations=15):print("calculating Matrix ... using {} ratings".format(len(c_ui)))start_time = datetime.now()print("Creating ratings matrix")c_ui['rating'] = (c_ui['rating'] - c_ui['rating'].min()) / (c_ui['rating'].max() - c_ui['rating'].min())c_ui['rating'] = c_ui['rating'].astype(float)#计算每个user_id的平均评分,并做归一化处理#c_ui['avg'] = c_ui.groupby('user_id')['rating'].transform(lambda x: normalize(x))#把user_id, movie_id转为pandas的类别,以便去重#c_ui['avg'] = c_ui['avg'].astype(float)c_ui['user_id'] = c_ui['user_id'].astype('category')c_ui['movie_id'] = c_ui['movie_id'].astype('category')#构建稀疏评分矩阵,没有评分的数据全部用0填充coo = coo_matrix((c_ui['rating'].astype(float),(c_ui['movie_id'].cat.codes.copy(),c_ui['user_id'].cat.codes.copy())))users, items = coo.shapeprint("Ratings matrix finished,in{} seconds".format(datetime.now() - start_time))start_time = datetime.now()print("Calculating ALS....")#随机初始化两个隐语义矩阵X,YX = np.random.rand(users, factors) * 0.01Y = np.random.rand(items, factors) * 0.01cui, ciu = coo.tocsr(), coo.T.tocsr()for iteration in range(iterations):self.least_squares_cg(cui=cui,X=X,Y=Y, regularization=regularization,)self.least_squares_cg(cui=ciu,X=Y,Y=X, regularization=regularization,)print("Rating matrix (size {}x{}) finished, in {} seconds".format(coo.shape[0], coo.shape[1], datetime.now() - start_time))#用户的相似度计算sim = np.dot(X, Y.T)movies_ = dict(enumerate(c_ui['movie_id'].cat.categories))users_ = dict(enumerate(c_ui['user_id'].cat.categories))self.save_similarity(sim_matrix=sim, movies=movies_, users=users_)#print(sim)#self.rmse(coo, sim)return X, Y#ALS算法/共轭梯度法#创建三元组 def least_squares_cg(self, cui, X, Y, regularization, cg_steps=3):#用户因子users, factors = X.shapeYtY = Y.T.dot(Y) + regularization * np.eye(factors)for u in range(users):#基于用户历史x = X[u]#计算残差r = (YtCuPu - (YtCuY.dot(Xu),并不计算 YtCuYr = -YtY.dot(x)for i, confidence in self.nonzeros(cui, u):r += (confidence - (confidence - 1) * Y[i].dot(x)) * Y[i]p = r.copy()rsold = r.dot(r)for it in range(cg_steps): #计算 Ap = YtCuYp -并非实际计算YtCuYAp = YtY.dot(p)for i, confidence in self.nonzeros(cui, u):Ap += (confidence - 1) * Y[i].dot(p) * Y[i]#更新CG标准alpha = rsold / p.dot(Ap)x += alpha * pr -= alpha * Aprsnew = r.dot(r)p = r + (rsnew / rsold) * prsold = rsnewX[u] = x#返回CSR矩阵非零元素的索引和值def nonzeros(self, m, row):""" returns the non zeroes of a row in csr_matrix """for index in range(m.indptr[row], m.indptr[row + 1]):yield m.indices[index], m.data[index]def rmse(self, coo, sim):#取出评分大于0的数据start_time = datetime.now()print('instantiation of coo_matrix in {} seconds'.format(datetime.now() - start_time))csr = coo.tocsr()print('Calculating rmse....')#计算最小均方误差mse = 0.0xs, ys = coo.nonzero()number = len(coo.data)for x, y in tqdm(zip(xs, ys), leave=True):y_r = csr[x, y]if y_r > 0:y_hat = sim[x][y]square_error = (y_r - y_hat) ** 2mse += square_errorprint('RMSE {}'.format((mse / number) ** 0.5))@staticmethod#用户连接登录def get_connect():if settings.DATABASES['default']['ENGINE']=='django.db.backends.postgresql':#获取用户名和密码dbUsername = settings.DATABASES['default']['USER']dbPassword = settings.DATABASES['default']['PASSWORD']dbName = settings.DATABASES['default']['NAME']#用户名和密码校验conn_str = "dbname={} user={} password={}".format(dbName,dbUsername,dbPassword)conn = psycopg2.connect(conn_str)return conn#用户相似度的计算和保存def save_similarity(self, sim_matrix, movies, users, created=datetime.now()):start_time = datetime.now()print('truncating table in {} seconds'.format(datetime.now() - start_time))sims = []no_saved = 0start_time = datetime.now()print('instantiation of coo_matrix in {} seconds'.format(datetime.now() - start_time))query = "insert into similarity_mf (created, user_id, movie_id, similarity) values %s;"conn = self.get_connect()cur = conn.cursor()cur.execute('truncate table similarity_mf')print('{} similarities to save'.format(len(sim_matrix)))#用户相似度匹配row, column = sim_matrix.shapefor i in tqdm(range(row)):for j in range(column):sim = sim_matrix[i][j]if sim < self.min_sim:continueif (len(sims)) == 500000:psycopg2.extras.execute_values(cur, query, sims)sims = []print("{} saved in {}".format(no_saved,datetime.now() - start_time)) #用户评分相似度矩阵创建new_similarity = (str(created), users[j], movies[i], sim)no_saved += 1sims.append(new_similarity)psycopg2.extras.execute_values(cur, query, sims, template=None, page_size=1000)conn.commit()print('{} Similarity items saved, done in {} seconds'.format(no_saved, datetime.now() - start_time))
#获取评分数据
def load_all_ratings(min_ratings=1):columns=['user_id','movie_id','rating', 'type', 'rating_timestamp']ratings_data = Rating.objects.all().values(*columns)ratings = pd.DataFrame.from_records(ratings_data, columns=columns)user_count=ratings[['user_id', 'movie_id']].groupby('user_id').count()user_count = user_count.reset_index()user_ids=user_count[user_count['movie_id']>min_ratings]['user_id']#获取评分高的相应用户名ratings = ratings[ratings['user_id'].isin(user_ids)]ratings['rating'] = ratings['rating'].astype(float)return ratingsif __name__ == '__main__':all_ratings = load_all_ratings()model = MatrixFactorization(min_sim=0.1)X, Y = model.train(c_ui=all_ratings, factors=50, regularization=0.01, iterations=1)
3)LDA主题模型
相关代码如下:
#导入需要的包
import os
from tqdm import tqdm
import psycopg2
from datetime import datetime
from scipy.sparse import coo_matrix
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "Recs.settings")
import django
from Recs import settings
import numpy as np
django.setup()
from nltk.tokenize import RegexpTokenizer
from stop_words import get_stop_words
from gensim import corpora, models, similarities
from Recommender.models import MovieDecriptions, LdaSimilarity
#建立主题模型
class LdaModel(object):def __init__(self, min_sim=0.1):self.min_sim = min_sim;self.db = settings.DATABASES['default']['ENGINE']def train(self, data=None, docs=None):
#数据准备if data is None:data, docs = load_data()NUM_TOPICS = 10self.build_lda_model(data, docs, NUM_TOPICS)def build_lda_model(self, data, docs, n_topics=5):texts = []# 英文分词tokenizer = RegexpTokenizer(r'\w+')for d in tqdm(data):raw = d.lower()tokens = tokenizer.tokenize(raw)# 去除停用词stop_tokens = self.remove_stopwords(tokens)stemmed_tokens = stop_tokenstexts.append(stemmed_tokens)# 构建词典dictionary = corpora.Dictionary(texts)# 生成语料库corpus = [dictionary.doc2bow(text) for text in texts]lda_model = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=n_topics)index = similarities.MatrixSimilarity(corpus)self.save_similarities_with_postgresql(index, docs)return dictionary, texts, lda_model@staticmethoddef remove_stopwords(tokenized_data):#去除停用词en_stop = get_stop_words('en')stop_tokens = [token for token in tokenized_data if token not in en_stop]return stop_tokens
#保留相似度
def save_similarities_with_postgresql(self, index, docs, created=datetime.now()):start_time = datetime.now()print(f'truncating table in {datetime.now() - start_time} seconds')sims = []no_saved = 0start_time = datetime.now()#创建稀疏矩阵coo = coo_matrix(index)csr = coo.tocsr()print(f'instantiation of coo_matrix in {datetime.now() - start_time} seconds')query = "insert into lda_similarity (created, source, target, similarity) values %s;"conn = self.get_conn()cur = conn.cursor()#cur.execute('drop table lda_similarity')#cur.execute('ALTER TABLE lda_similarity ADD COLUMN similarity decimal(8, 7) NOT NULL')cur.execute('truncate table lda_similarity')print(f'{coo.count_nonzero()} similarities to save')
#相似度对比xs, ys = coo.nonzero()for x, y in zip(xs, ys):if x == y:continuesim = float(csr[x, y])x_id = str(docs[x].movie_id)y_id = str(docs[y].movie_id)#取出评分sim数量超过min_sim的所有simif sim < self.min_sim:continueif len(sims) == 100000:psycopg2.extras.execute_values(cur, query, sims)sims = []print(f"{no_saved} saved in {datetime.now() - start_time}")new_similarity = (str(created), x_id, y_id, sim)no_saved += 1sims.append(new_similarity)psycopg2.extras.execute_values(cur, query, sims, template=None, page_size=1000)conn.commit()print('{} Similarity items saved, done in {} seconds'.format(no_saved, datetime.now() - start_time))#获取用户名和密码@staticmethoddef get_conn():dbUsername = settings.DATABASES['default']['USER']dbPassword = settings.DATABASES['default']['PASSWORD']dbName = settings.DATABASES['default']['NAME']
#用户名和密码校验conn_str = "dbname={} user={} password={}".format(dbName,dbUsername,dbPassword)conn = psycopg2.connect(conn_str)return conn
#获取电影数据
def load_data():docs = list(MovieDecriptions.objects.all())data = ["{}, {}, {}".format(d.title, d.genres, d.description) for d in docs]if len(data) == 0:print("No descriptions were found, run populate_sample_of_descriptions")return data, docs
if __name__ == '__main__':print("Calculating lda model...")data, docs = load_data()lda = LdaModel()lda.train(data, docs)
3. 接口实现
在定义模型架构和训练保存后,电影推荐系统接口实现如下。
1)流行电影推荐
相关代码如下:
#导入需要的包
from decimal import Decimal
from Collector.models import Log
from django.db.models import Count
from django.db.models import Q
from django.db.models import Avg
from Recsmodel.baseModel import baseModel
#流行度推荐
class Popularity(baseModel):def predict_score(self, user_id, item_id):return Nonedef recommend_items(self, user_id, num=6):return None@staticmethod
#推荐六部流行度最高的电影def recommend_items_from_log(num=6):items = Log.objects.values('content_id')items = items.filter(event='like').annotate(Count("user_id"))sorted_items = sorted(items, key=lambda item: -float(item['user_id__count']))return sorted_items[:num]
2)相邻用户推荐
相关代码如下:
#导入需要的包
from Recsmodel.baseModel import baseModel
from Analytics.models import Rating
from django.db.models import Q
import time
from decimal import Decimal
from Recommender.models import Similarity
class NeighborhoodRecs(baseModel):def __init__(self, neighborhood_size=10, min_sim=0.1):#最近邻个数,最小相似度,最大候选集个数self.neighborhood_size = neighborhood_sizeself.min_sim = min_simself.max_candidates = 100def recommend_items(self, user_id, num=6):#取出用户有过的评分信息active_user_items = Rating.objects.filter(user_id=user_id).order_by('-rating')[0: self.max_candidates]#print(user_id, active_user_items.values())return self.recommend_item_by_ratings(active_user_items.values(), num)#推荐def recommend_item_by_ratings(self, active_user_items, num=6):#如果没有评过分的则返回空if len(active_user_items) == 0:return {}#标记时间start = time.time()movie_ids = {movie['movie_id']: movie['rating'] for movie in active_user_items}#用户平均评分user_mean = sum(movie_ids.values()) / len(movie_ids)candidate_items = Similarity.objects.filter(Q(source__in=movie_ids.keys())& ~Q(target__in=movie_ids.keys())& Q(similarity__gt=self.min_sim))#print(candidate_items)candidate_items = candidate_items.order_by('-similarity')[:self.max_candidates]recs = dict()for candidate in candidate_items:target = candidate.targetpre = 0sim_sum = 0rated_items = [i for i in candidate_items if i.target == target][:self.neighborhood_size]#print(rated_items)if len(rated_items) > 0:for sim_item in rated_items:r = Decimal(movie_ids[sim_item.source] - user_mean)pre += sim_item.similarity * rsim_sum += sim_item.similarity
#取出相似度最高的所有itemif sim_sum > 0:recs[target] = {'prediction': Decimal(user_mean) + pre / sim_sum,'sim_items': [r.source for r in rated_items]}#对筛选出来的item进行分类sorted_items = sorted(recs.items(), key=lambda item: -float(item[1]['prediction']))[:num]return sorted_items#评分预测
def predict_score(self, user_id, item_id):user_items = Rating.objects.filter(user_id=user_id)
user_items = user_items.exclude(movie_id=item_id).order_by('-rating')[:100]movie_ids = {movie.movie_id: movie.rating for movie in user_items}return self.predict_score_by_ratings(item_id, movie_ids)def predict_score_by_ratings(self, item_id, movie_ids):top = Decimal(0.0)bottom = Decimal(0.0)ids = movie_ids.keys()mc = self.max_candidates
#候选电影名单
candidate_items = (Similarity.objects.filter(source__in= ids).exclude(source=item_id).filter(target=item_id))
candidate_items = candidate_items.distinct().order_by('-similarity')[:mc]if len(candidate_items) == 0:return 0for sim_item in candidate_items:r = movie_ids[sim_item.source]top += sim_item.similarity * rbottom += sim_item.similarityreturn Decimal(top/bottom)
3)相似内容推荐
相关代码如下:
#导入需要的包
from decimal import Decimal
from django.db.models import Q
from Analytics.models import Rating
from Recommender.models import MovieDecriptions,LdaSimilarity
from Recsmodel.baseModel import baseModel
#建立基本推荐模型
class ContentBasedRecs(baseModel):def __init__(self, min_sim= 0.1):self.min_sim = min_simself.max_candidates = 100
#基于用户内容的协同过滤def recommend_items(self, user_id, num=6):
active_user_items = Rating.objects.filter(user_id=user_id).order_by('-rating')[:100]
return self.recommend_items_by_ratings(user_id, active_user_items.values(), num)def recommend_items_by_ratings(self,user_id,active_user_items,num=6):if len(active_user_items) == 0:return {}movie_ids = {movie['movie_id']: movie['rating'] for movie in active_user_items}user_mean = sum(movie_ids.values()) / len(movie_ids)
#计算用户内容的相似度sims =LdaSimilarity.objects.filter(Q(source__in=movie_ids.keys())&~Q(target__in=movie_ids.keys())&Q(similarity__gt=self.min_sim))print(active_user_items)sims = sims.order_by('-similarity')[:self.max_candidates]recs = dict()targets = set(s.target for s in sims if not s.target == '')for target in targets:pre = 0sim_sum = 0rated_items = [i for i in sims if i.target == target]if len(rated_items) > 0:for sim_item in rated_items:r = Decimal(movie_ids[sim_item.source] - user_mean)pre += sim_item.similarity * rsim_sum += sim_item.similarityif sim_sum > 0:recs[target] = {'prediction': Decimal(user_mean) + pre / sim_sum,'sim_items': [r.source for r in rated_items]}return sorted(recs.items(), key=lambda item: -float(item[1]['prediction']))[:num]def predict_score(self, user_id, item_id):return None
相关其它博客
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(一)
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(二)
基于LDA主题+协同过滤+矩阵分解算法的智能电影推荐系统——机器学习算法应用(含python、JavaScript工程源码)+MovieLens数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。