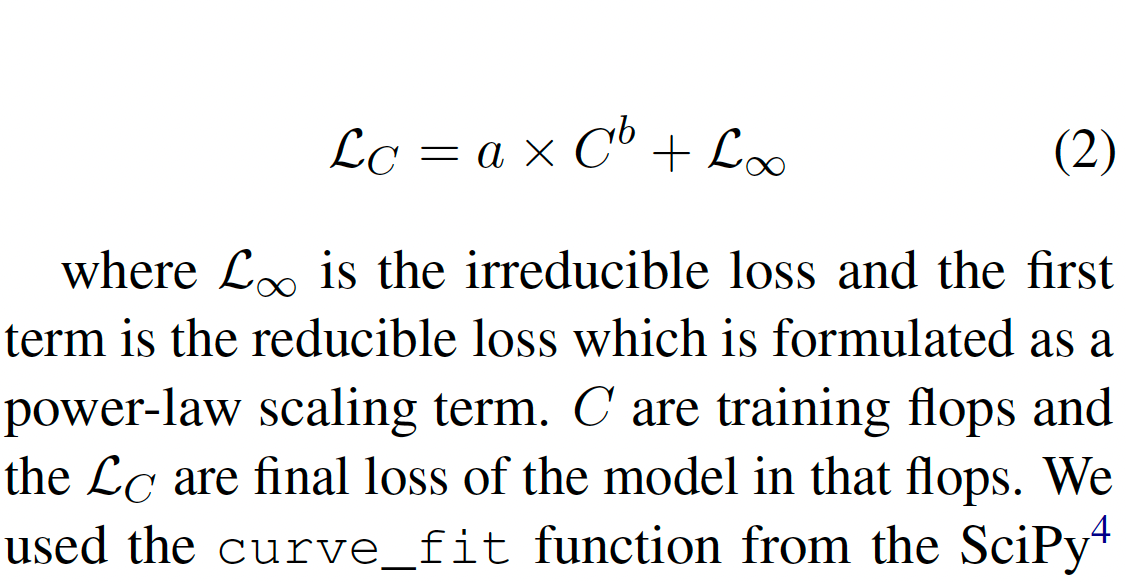QWen
Tokenizer
- 选择byte pair encoding (BPE)作为分词方法
- vacabulary在中文上做了增强,验证增加vocabulary的规模不会为下游任务带来负面影响
Model
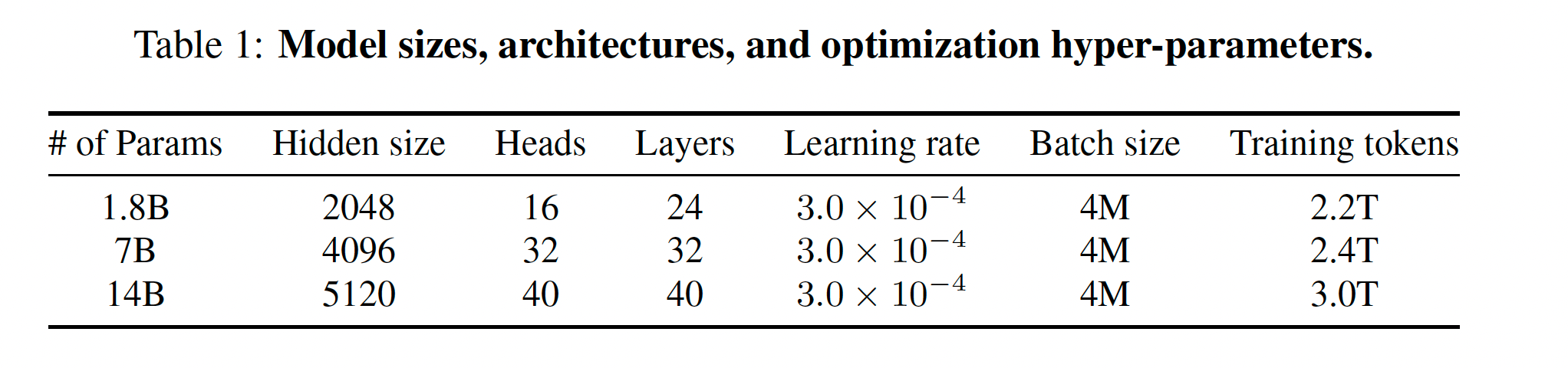
- Positional embedding:选择RoPE,反向更新时选择FP32的精度而不是FP16或BP16,以提高模型精度
- Bias:在多数layer中去除了bias,但是在注意力的QKV的layer中,加入了bias,提高模型外推能力
- RMSNorm: 取代了Pre-Norm
- Activation function:选择了SwiGLU作为激活函数,把FFN的维度从4倍的hidden size降到了8/3倍
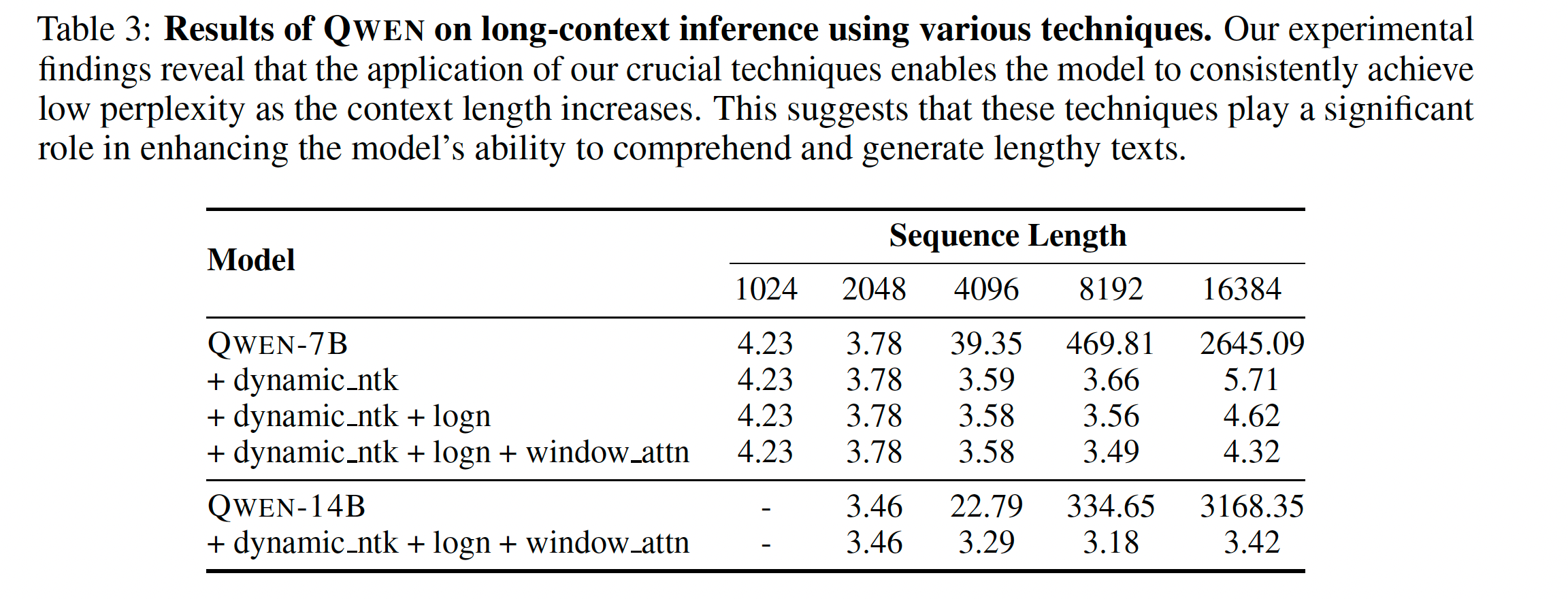
context length
context length受限于Transformer的架构,上下文长度增加会带来巨大的计算量和内存占用
扩展上下文长度主要有两个关键技术去解决:
- NTK-aware interpolation
- dynamic NTK-aware interpolation,每个chunk的scale不一样
两个注意力机制:
- LogN-Scaling, q和v乘以一个系数,context length和training length的长度关系,来保持注意力的稳定
- window attention,把注意力严格限制在窗口内,防止context length过长
观察到的结论:低层级的layer对context length的扩展更加敏感,相对于高层级
训练细节
Train阶段
- context length设置为2048
- flash attention 加速
- bf16混合精度训练
SFT阶段
sft也会将next token predict作为训练任务
在system 和user input上算loss
RL阶段
four models: the policy model, valuemodel, reference model, and reward mod
- we pause the policy model’s updates and focus solely on updating the value model for 50 steps. This approach ensures
that the value model can adapt to different reward models effectively.
BaiChuan
tokenizer
tokenizer需要平衡两个因素:
- 为了高效推理,需要一个高的压缩率
- 大小合适的词表
- 使用byte-pair encoding (BPE),但是没有对输入文本就行任何的归一化,也没有像百川1那样加入dummy prefix
- split numbers into individual digits
- 为了解决代码数据中的空格问题,加入了空格作为token
- maximum token length被设置为32,去解释中文的长短语
model

-
7B用的RoPE,13B用的ALiBi,但是最近的实验证明,位置编码方式的选取并不会显著影响模型的性能,分开用是为了后续的研究和百川1进行对比
-
激活函数用的SwiGLU,从4倍 hidden size减小到8/3 倍。而且四舍五入到128的倍数
-
注意力层的优化,用的xformer结合ALiBi的位置编码,来减小内存占用
-
RMSNorm,更高效的计算输入变量的方差
-
bf16训练,比fp16有更好的动态范围。但是bf16的低精度也导致了一些问题:
- RoPE and ALibi 会出现int溢出(超过256),所以位置编码采用全精度
-
NormHead:为了训练稳定和改善模型性能,对output的embediing(称之为head)就行归一化。两个优点:
- 1)保证训练的稳定性。发现了head的分布不稳定,在训练期间稀少的token的embedding会变得很小,会使得训练中断
- 2)NormHead减轻了在计算logits时L2距离的干扰。语义信息主要通过嵌入的余弦相似度进行编码,而不是L2距离。由于当前的线性分类器通过点积计算logits,它是L2距离和余弦相似度的混合。
-
加入max-z loss 去归一化logits。
在训练过程中,我们发现语言模型(LLMs)的logits可能会变得非常大。然而,softmax函数对于绝对logit值是不敏感的,因为它只依赖于它们的相对值。问题出现在推理过程中,常见的实现直接将重复惩罚应用于logits上。这种收缩非常大的logits的过程可以显着改变softmax后的概率,使模型对重复惩罚超参数的选择变得敏感。
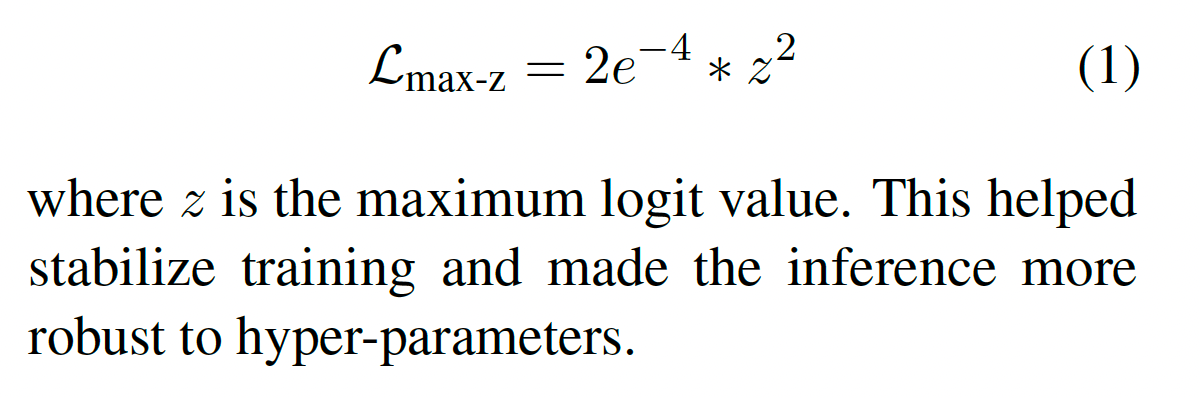
-
Scaling low:百川2的缩放规律
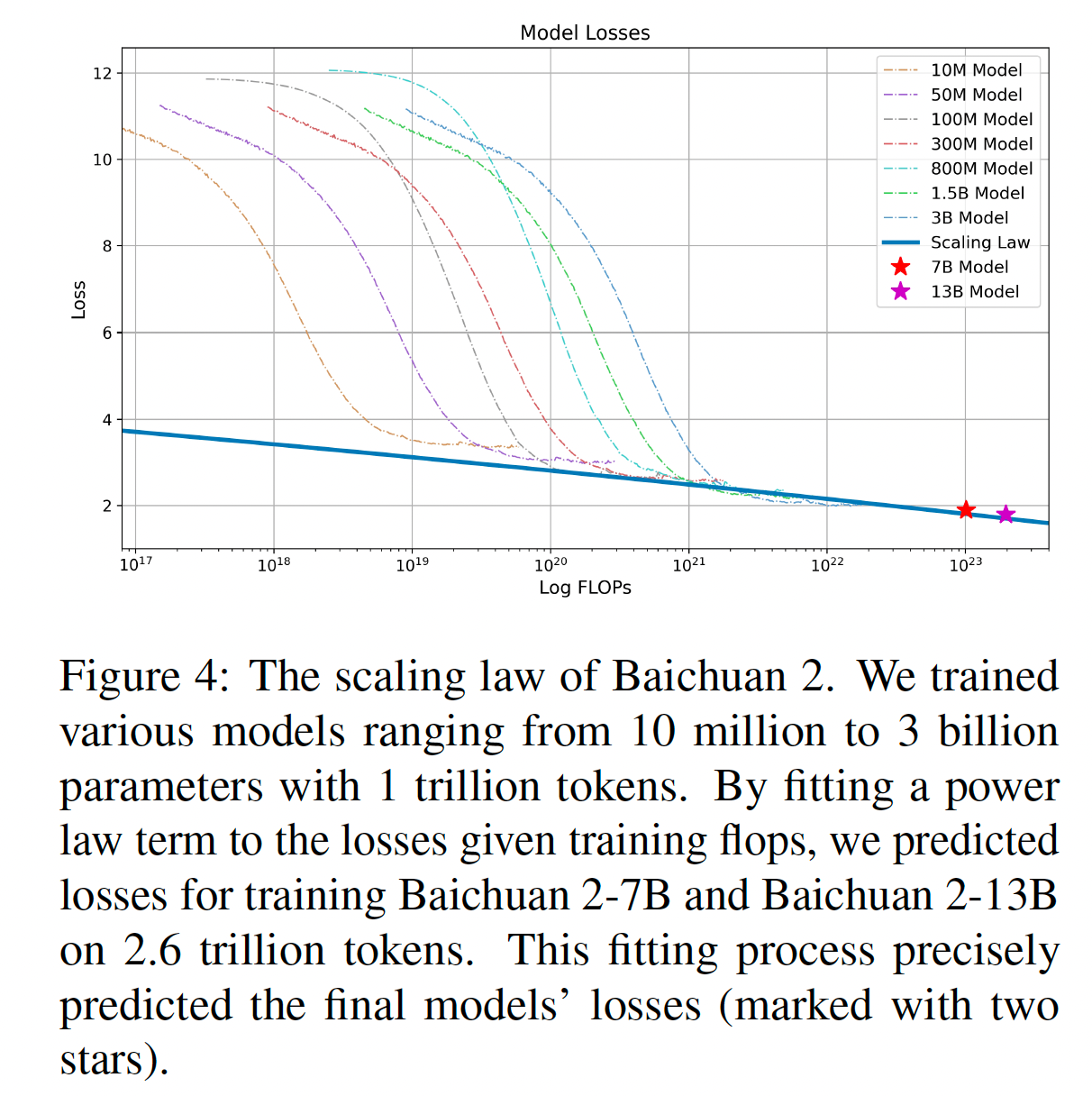
我们训练了从1千万到30亿参数的各种模型,使用1万亿个标记进行训练。通过将功耗训练损失拟合到一个幂律项,我们预测了在使用2.6万亿个标记进行训练时,百川2-7B和百川2-13B的训练损失。这个拟合过程准确地预测了最终模型的训练损失(用两颗星标记)。