文章目录
- 1. 简介
- 2. 策略迭代算法
- 2.1 策略评估
- Example1
- 2.2 策略提升
- 2.3 策略迭代算法
- Example2:Jack's Car Rental
- 3. 价值迭代算法
- Example1
- 4. 价值迭代VS.策略迭代
- 总结
- DP扩展
- 代码
- 悬崖漫步(Cliff Walking)
- 冰湖(Frozen Lake)
- 参考
1. 简介
动态规划(Dynamic Programming)是程序设计算法中非常重要的内容,能够高效解决一些经典问题,例如背包问题和最短路径规划。动态规划的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。
动态规划是一种非常通用的解决问题的方法,适用于具有以下两个特性的问题:
- 最优子结构Optimal substructure:最优解可以被分解为子问题。
- 最优性原理适用Principle of optimality:重叠子问题:子问题经常重复出现。解决方案可以被缓存和重复使用。
- 马尔可夫决策过程符合这两个属性。
- 贝尔曼方程提供了递归分解。
- 价值函数存储和重用解决方案。
基于动态规划的强化学习算法主要有两种:一是策略迭代(policy iteration),二是价值迭代(value iteration)。其中,策略迭代由两部分组成:策略评估(policy evaluation)和策略提升(policy improvement)。具体来说,
- 策略迭代中的策略评估使用贝尔曼期望方程来得到一个策略的状态价值函数,这是一个动态规划的过程;
- 而价值迭代直接使用贝尔曼最优方程来进行动态规划,得到最终的最优状态价值。
基于动态规划的这两种强化学习算法要求事先知道环境的状态转移函数和奖励函数,也就是需要知道整个马尔可夫决策过程,即白盒环境。
但是,现实中的白盒环境很少,我们无法动态规划算法其运用到很多实际场景中。另外,策略迭代和价值迭代通常只适用于有限马尔可夫决策过程,即状态空间和动作空间是离散且有限的。
2. 策略迭代算法
2.1 策略评估
策略迭代是策略评估和策略提升不断循环交替,直至最后得到最优策略的过程。策略评估这一过程用来计算一个策略的状态价值函数。 V π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a V π ( s ′ ) ) V_\pi(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\left(\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^aV_\pi(s^{\prime})\right) Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
这是上一讲中介绍的贝尔曼期望方程,只要 γ < 1 \gamma<1 γ<1或者能够保证在策略 π \pi π下能得到最终状态,那么就可以保证 V π V_\pi Vπ的存在性与唯一性。同时可以从中知道当回报函数 R s a \mathcal{R}_s^a Rsa和状态转移函数 P s s ′ a \mathcal{P}_{ss^{\prime}}^a Pss′a已知时,就可以通过下一个状态 s ′ s' s′的价值来计算当前状态的价值。更一般地说,考虑所有可能的状态,我们可以使用上一轮的状态价值函数来计算当前轮次的状态价值函数。 V k + 1 ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a V k ( s ′ ) ) V_{k+1}(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\left(\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^aV_{k}(s^{\prime})\right) Vk+1(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVk(s′))
我们可以选定任意初始近似值 V 0 V_0 V0(除了终点外),后继的近似值 V 1 , V 2 , … , V k V_1,V_2,\dots,V_k V1,V2,…,Vk可以依据上式贝尔曼方程得到。根据贝尔曼期望方程,可以得知是 V k = V π V_k=V_\pi Vk=Vπ以上更新公式的一个不动点(fixed point)。事实上,可以证明当 k → ∞ k\to\infty k→∞时,序列 V k {V_k} Vk会收敛到 V π {V_\pi} Vπ,所以可以据此来计算得到一个策略的状态价值函数。可以看到,由于需要不断做贝尔曼期望方程迭代,策略评估其实会耗费很大的计算代价。在实际的实现过程中,如果某一轮 max s ∈ S [ V k + 1 ( s ) − V k ( s ) ] \max_{s\in\mathcal S}[V_{k+1}(s)-V_{k}(s) ] maxs∈S[Vk+1(s)−Vk(s)]的值非常小,可以提前结束策略评估。这样做可以提升效率,并且得到的价值也非常接近真实的价值。
此部分伪代码如下所示:

Example1

- 非折扣MDP 𝛾 = 1
- 非终止状态:1, 2, …,14
- 两个终止状态(灰色方格)
- 如果动作指向所有方格以外,则这一步不动
- 奖励均为-1,直到到达终止状态
- 智能体的策略为均匀随机策略 π ( n ∣ ⋅ ) = π ( e ∣ ⋅ ) = π ( s ∣ ⋅ ) = π ( w ∣ ⋅ ) = 0.25 \pi(n|\cdot)=\pi(e|\cdot)=\pi(s|\cdot)=\pi(w|\cdot)=0.25 π(n∣⋅)=π(e∣⋅)=π(s∣⋅)=π(w∣⋅)=0.25

左列是随机策略(所有操作等可能性)的状态值函数近似的序列。右列是与值函数估计相对应的贪婪策略序列(箭头显示所有达到最大值的动作,并且显示的数字保留了两位有效数字)。随着迭代逐渐收敛,不过可以注意到,当 k = 3 k=3 k=3之时,其实已经达到了最优策略。
2.2 策略提升
使用策略评估计算得到当前策略的状态价值函数之后,我们可以据此来改进该策略。假设此时对于策略 π \pi π,我们已经知道其价值,也就是知道了在策略下从每一个状态出发最终得到的期望回报 V π V_\pi Vπ。我们要如何改变策略来获得在状态 s s s下更高的期望回报呢?假设智能体在状态 s s s下采取动作 a a a,之后的动作依旧遵循策略 π \pi π,此时得到的期望回报其实就是动作价值 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。如果我们有 Q π ( s , a ) > V π Q_\pi(s,a)>V_\pi Qπ(s,a)>Vπ,则说明在状态 s s s下采取动作 a a a会比原来的策略 π ( a ∣ s ) \pi(a|s) π(a∣s)得到更高的期望回报。以上假设只是针对一个状态,现在假设存在一个确定性策略,在任意一个状态下,都满足 Q π ( s , π ′ ( s ) ) ≥ V π ( s ) Q_\pi(s,\pi'(s)) \geq V_\pi(s) Qπ(s,π′(s))≥Vπ(s)
于是在任意状态 s s s下,我们有 V π ′ ( s ) ≥ V π ( s ) V_\pi'(s)\geq V_\pi(s) Vπ′(s)≥Vπ(s)这便是策略提升定理(policy improvement theorem)。于是我们可以直接贪心地在每一个状态选择动作价值最大的动作,也就是 π ′ ( s ) = arg max a Q π ( s , a ) = arg max a { r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V π ( s ′ ) } \pi^{\prime}(s)=\arg\max_aQ^\pi(s,a)=\arg\max_a\{r(s,a)+\gamma\sum_{s^{\prime}}P(s^{\prime}|s,a)V^\pi(s^{\prime})\} π′(s)=argamaxQπ(s,a)=argamax{r(s,a)+γs′∑P(s′∣s,a)Vπ(s′)}
策略提升定理的证明: v π ( s ) ≤ q π ( s , π ′ ( s ) ) = E [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s , A t = π ′ ( s ) ] = E π ′ [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] ≤ E π ′ [ R t + 1 + γ q π ( S t + 1 , π ′ ( S t + 1 ) ) ∣ S t = s ] = E π ′ [ R t + 1 + γ E [ R t + 2 + γ v π ( S t + 2 ) ∣ S t + 1 , A t + 1 = π ′ ( S t + 1 ) ] ∣ S t = s ] = E π ′ [ R t + 1 + γ R t + 2 + γ 2 v π ( S t + 2 ) ∣ S t = s ] ≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 v π ( S t + 3 ) ∣ S t = s ] ≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + ⋯ ∣ S t = s ] = v π ′ ( s ) . \begin{aligned} v_{\pi}(s)& \leq q_{\pi}(s,\pi^{\prime}(s)) \\ &=\mathbb{E}[R_{t+1}+\gamma v_{\pi}(S_{t+1})\mid S_{t}=s,A_{t}=\pi^{\prime}(s)] \\ &=\mathbb{E}_{\pi^{\prime}}[R_{t+1}+\gamma v_{\pi}(S_{t+1})\mid S_{t}=s] \\ &\leq\mathbb{E}_{\pi'}[R_{t+1}+\gamma q_{\pi}(S_{t+1},\pi'(S_{t+1}))\mid S_{t}=s] \\ &=\mathbb{E}_{\pi'}[R_{t+1}+\gamma\mathbb{E}[R_{t+2}+\gamma v_{\pi}(S_{t+2})|S_{t+1},A_{t+1}=\pi'(S_{t+1})]|S_{t}=s] \\ &=\mathbb{E}_{\pi'}\big[R_{t+1}+\gamma R_{t+2}+\gamma^{2}v_{\pi}(S_{t+2})\big|S_{t}=s\big] \\ &\leq\mathbb{E}_{\pi'}\big[R_{t+1}+\gamma R_{t+2}+\gamma^{2}R_{t+3}+\gamma^{3}v_{\pi}(S_{t+3})\big|S_{t}=s\big] \\ &\leq\mathbb{E}_{\pi^{\prime}}\big[R_{t+1}+\gamma R_{t+2}+\gamma^{2}R_{t+3}+\gamma^{3}R_{t+4}+\cdots\big|S_{t}=s\big] \\ &=v_{\pi^{\prime}}(s). \end{aligned} vπ(s)≤qπ(s,π′(s))=E[Rt+1+γvπ(St+1)∣St=s,At=π′(s)]=Eπ′[Rt+1+γvπ(St+1)∣St=s]≤Eπ′[Rt+1+γqπ(St+1,π′(St+1))∣St=s]=Eπ′[Rt+1+γE[Rt+2+γvπ(St+2)∣St+1,At+1=π′(St+1)]∣St=s]=Eπ′[Rt+1+γRt+2+γ2vπ(St+2) St=s]≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3vπ(St+3) St=s]≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+⋯ St=s]=vπ′(s).
2.3 策略迭代算法
总体来说,策略迭代算法的过程如下:对当前的策略进行策略评估,得到其状态价值函数 V π V_\pi Vπ,然后根据该状态价值函数进行策略提升以得到一个更好的新策略 π ′ \pi' π′,接着继续评估新策略、提升策略……直至最后收敛到最优策略.
结合策略评估和策略提升,我们得到以下策略迭代算法:

Example2:Jack’s Car Rental
问题描述:Jack管理着一家全国租车公司的两个地点。每天,一些客户会到达每个位置租车。如果Jack有车可用,他就会把它租出去,并从全国公司得到10美元的报酬。如果他在那个地点没有车,那么生意就丢了。车在归还后的第二天就可以出租了。为了帮助确保在需要的地方有车可用,Jack可以在一夜之间将车在两个地点之间移动,每辆车移动的成本为2美元。我们假设在每个地点请求和归还的汽车数量是泊松随机变量,这意味着数量为 n n n的概率是 λ n n ! e − λ \frac{\lambda^n}{n!}e^{-\lambda} n!λne−λ,其中是 λ \lambda λ期望数量。假设第一个和第二个地点的期望租车请求 λ \lambda λ是3和4,期望归还数量 λ \lambda λ是3和2。为了稍微简化问题,我们假设每个地点最多只能有20辆车(任何额外的车都会归还给全国公司,不考虑超出的部分),并且一夜之间从一个地点到另一个地点最多只能移动5辆车。我们把折扣率定为 γ = 0.9 \gamma=0.9 γ=0.9,并将其表述为一个持续的有限MDP,其中时间步是天,状态是每天结束时每个地点的汽车数量,动作是在一夜之间在两个地点之间移动的汽车的净数量。下图显示了从从不移动任何汽车的策略开始的策略迭代找到的策略序列。

Jack租车问题:通过策略迭代找到的策略序列和最终的状态值函数。前五个图表显示,对于一天结束时每个位置的汽车数量,从第一个位置转移到第二个位置的汽车数量(负数表示从第二个位置转移到第一个位置)。每个后续策略都比前一个策略有严格的改进,最后一个策略是最优的。
3. 价值迭代算法
从策略迭代代码运行(详见代码悬崖漫步部分)结果中我们能发现,策略迭代中的策略评估需要进行很多轮才能收敛得到某一策略的状态函数,这需要很大的计算量,尤其是在状态和动作空间比较大的情况下。我们是否必须要完全等到策略评估完成后再进行策略提升呢?试想一下,可能出现这样的情况:虽然状态价值函数还没有收敛,但是不论接下来怎么更新状态价值,策略提升得到的都是同一个策略。如果只在策略评估中进行一轮价值更新,然后直接根据更新后的价值进行策略提升,这样是否可以呢?答案是肯定的,这其实就是本节将要讲解的价值迭代算法,它可以被认为是一种策略评估只进行了一轮更新的策略迭代算法。需要注意的是,价值迭代中不存在显式的策略,我们只维护一个状态价值函数。
确切来说,价值迭代可以看成一种动态规划过程,它利用的是贝尔曼最优方程:
V ∗ ( s ) = max a ∈ A { R s a + γ ∑ s ′ ∈ S P s s ′ a V ∗ ( s ′ ) } V_*(s)=\max_{a\in\mathcal{A}}\{\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^aV_*(s^{\prime})\} V∗(s)=a∈Amax{Rsa+γs′∈S∑Pss′aV∗(s′)}
将其写成迭代更新的方式为
V k + 1 ( s ) = max a ∈ A { R s a + γ ∑ s ′ ∈ S P s s ′ a V k ( s ′ ) } V_{k+1}(s)=\max_{a\in\mathcal{A}}\{\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^aV_{k}(s^{\prime})\} Vk+1(s)=a∈Amax{Rsa+γs′∈S∑Pss′aVk(s′)}
价值迭代便是按照以上更新方式进行的。等到 V k + 1 V_{k+1} Vk+1和 V k V_k Vk相同时,它就是贝尔曼最优方程的不动点,此时对应着最优状态价值函数 V ∗ V_* V∗。然后我们利用 π ( s ) = arg max a ∈ A { R s a + γ ∑ s ′ ∈ S P s s ′ a V k + 1 ( s ′ ) } \pi(s)=\arg\max_{a\in\mathcal{A}}\{\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^aV_{k+1}(s^{\prime})\} π(s)=argmaxa∈A{Rsa+γ∑s′∈SPss′aVk+1(s′)},从中恢复出最优策略即可。
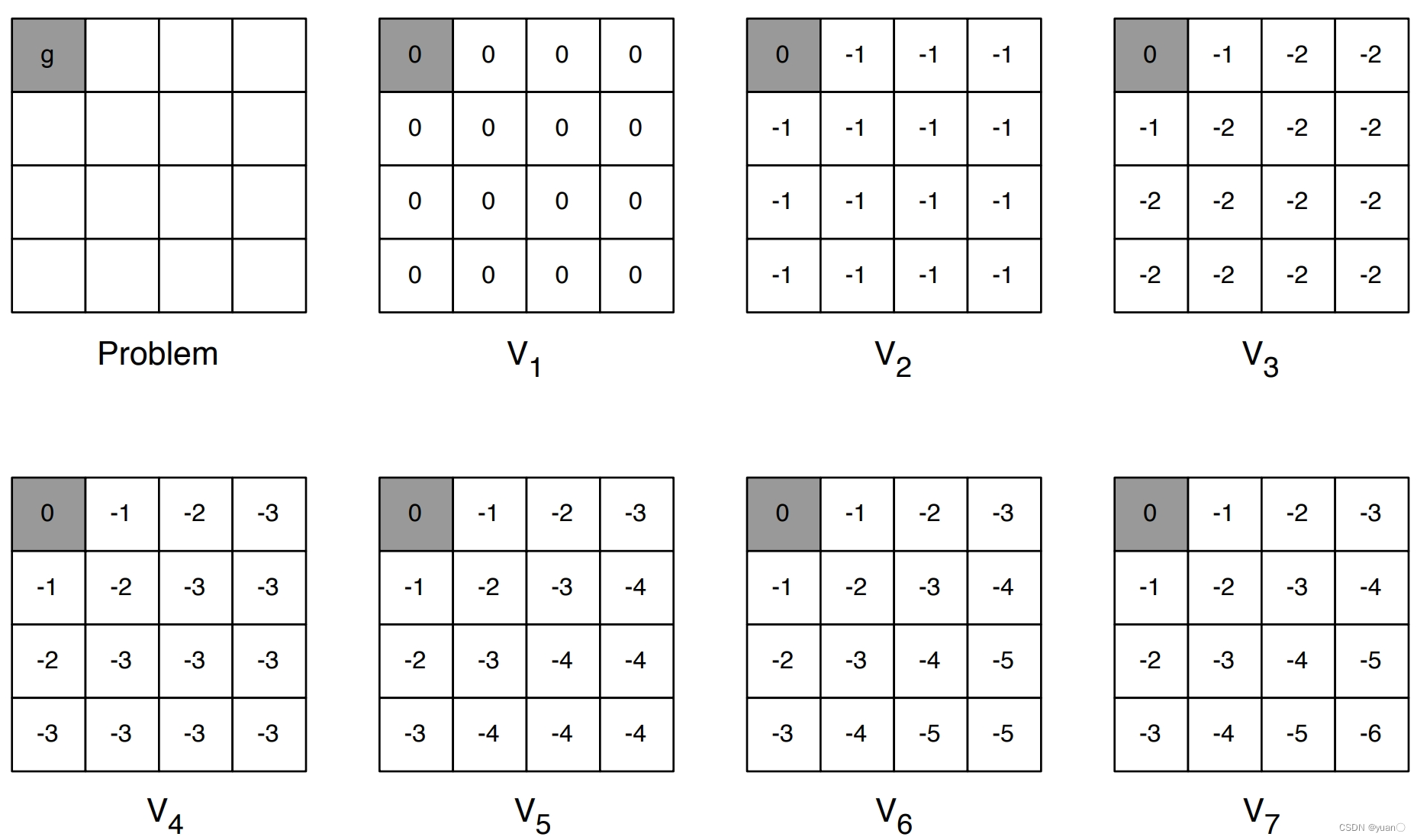
Example1
最短路径的寻找。 V 1 V_1 V1为价值函数的初始化。 V 2 = m a x a ∈ A { − 1 + γ ⋅ 0 } , V 3 = … V_2=max_{a\in\mathcal A}\{-1+\gamma\cdot0\},V_3=\dots V2=maxa∈A{−1+γ⋅0},V3=…
4. 价值迭代VS.策略迭代
- 价值迭代是贪心更新法
- 策略迭代中,用Bellman等式更新价值函数计算代价很大
- 对于空间较小的MDP,策略迭代通常很快收敛
- 对于空间较大的MDP,价值迭代更实用(效率更高)
- 如果没有状态转移循环,最好使用价值迭代
总结
- Dynamic Programming 要求事先知道环境的状态转移函数和奖励函数,也就是需要知道整个马尔可夫决策过程,即白盒环境。
- 可以用于预测Prediction的任务之中:
- 输入: M D P ⟨ S , A , P , R , γ ⟩ MDP\langle S,A,P,R,\gamma\rangle MDP⟨S,A,P,R,γ⟩和策略 π \pi π或 M R P ⟨ S , P π , R π , γ ⟩ MRP\langle S,P_\pi,R_\pi,\gamma\rangle MRP⟨S,Pπ,Rπ,γ⟩
- 输出:价值函数 V π V_\pi Vπ
- 可以用于控制Control的任务之中:
- 输入: M D P ⟨ S , A , P , R , γ ⟩ MDP\langle S,A,P,R,\gamma\rangle MDP⟨S,A,P,R,γ⟩
- 输出:最优价值函数 V ∗ V_* V∗,最优策略 π ∗ \pi_* π∗
| Problem | Bellman Equation | Algorithm |
|---|---|---|
| Prediction | 贝尔曼期望等式 | 迭代的策略评估 |
| Control | 贝尔曼期望等式+策略提升 | 策略迭代 |
| Control | 贝尔曼最优等式 | 价值迭代 |
DP扩展
到目前为止描述的DP方法使用了同步备份(synchronous DP),即所有状态都是并行备份的。异步DP(Asynchronous DP)则以任意顺序逐个备份状态。对于每个选定的状态,应用适当的备份。可以显著减少计算量。如果所有状态继续被选择,则可以保证收敛。
- 三类异步DP的idea:
- In-place dynamic programming
- Prioritised sweeping
- Real-time dynamic programming
同步DP会对价值函数存储两份的备份
- f o r for for a l l all all s s s i n in in S \mathcal S S:
- V n e w ( s ) ← max a ∈ A ( R s a + γ ∑ s ′ ∈ S P s ′ a V o l d ( s ′ ) ) \textcolor{red}{V_{new}(s)}\leftarrow\max_{a\in\mathcal{A}}\left(\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{\mathbf{s}^{\prime}}^a\textcolor{red}{V_{old}(s^{\prime})}\right) Vnew(s)←maxa∈A(Rsa+γ∑s′∈SPs′aVold(s′))
- V o l d ← V n e w \color{red}{V_{old}}\leftarrow\color{red}{V_{new}} Vold←Vnew
In-place价值迭代只存储一份
- f o r for for a l l all all s s s i n in in S \mathcal S S:
- v ( s ) ← max a ∈ A ( R s a + γ ∑ s ′ ∈ S P s s ′ a v ( s ′ ) ) \textcolor{red}{v(s)}\leftarrow\max_{a\in\mathcal{A}}\left(\mathcal{R}_s^a+\gamma\sum_{s^{\prime}\in\mathcal{S}}\mathcal{P}_{ss^{\prime}}^a\textcolor{red}{v(s^{\prime})}\right) v(s)←maxa∈A(Rsa+γ∑s′∈SPss′av(s′))
代码
悬崖漫步(Cliff Walking)
悬崖漫步是一个非常经典的强化学习环境,它要求一个智能体从起点出发,避开悬崖行走,最终到达目标位置。如图所示,有一个 4×12 的网格世界,每一个网格表示一个状态。智能体的起点是左下角的状态,目标是右下角的状态,智能体在每一个状态都可以采取 4 种动作:上、下、左、右。如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,智能体掉入悬崖或到达目标状态都会结束动作并回到起点,也就是说掉入悬崖或者达到目标状态是终止状态。智能体每走一步的奖励是 −1,掉入悬崖的奖励是 −100。
代码中示例:


策略迭代
import copy
class CliffWalkingEnv:""" 悬崖漫步环境"""def __init__(self, ncol=12, nrow=4):# 定义网格世界的列self.ncol = ncol# 定义网格世界的行self.nrow = nrow# 转移矩阵P[state][action] = [(prob, next_state, reward, done)]包含下一个状态和奖励self.P = self.CreateP()def CreateP(self):# 初始化P = [[() for j in range(4)] for i in range(self.nrow * self.ncol)]# 4种动作, change[0]:上,change[1]:下, change[2]:左, change[3]:右。坐标系原点(0,0)# 定义在左上角change = [[0, -1], [0, 1], [-1, 0], [1, 0]]for i in range(self.nrow):for j in range(self.ncol):for a in range(4):# 位置在悬崖或者目标状态,因为无法继续交互,任何动作奖励都为0# 最后一行除了第一列和最后一列,都是悬崖if i == self.nrow - 1 and j > 0:P[i * self.ncol + j][a] = [1, i * self.ncol + j, 0, True]continue# 其他位置next_x = min(self.ncol - 1, max(0, j + change[a][0]))next_y = min(self.nrow - 1, max(0, i + change[a][1]))next_state = next_y * self.ncol + next_xreward = -1done = False# 下一个位置在悬崖或者终点if next_y == self.nrow - 1 and next_x > 0:done = Trueif next_x != self.ncol - 1: # 下一个位置在悬崖reward = -100P[i * self.ncol + j][a] = (1, next_state, reward, done)return Pclass PolicyIteration:""" 策略迭代算法 """def __init__(self, env, theta, gamma):self.env = env# 策略评估收敛阈值self.theta = theta# 折扣因子self.gamma = gamma# 初始化随机策略self.policy = [[0.25, 0.25, 0.25, 0.25] for i in range(self.env.nrow * self.env.ncol)]# 初始化价值函数self.v = [0] * self.env.ncol * self.env.nrowdef PolicyEvaluation(self):count = 0Delta_v = 100while Delta_v >= self.theta:Delta_v = 0new_v = [0] * self.env.ncol * self.env.nrowfor s in range(self.env.ncol * self.env.nrow):# 用动作价值函数来替换公式后面的一部分,计算状态s下的所有Q(s,a)价值Qsa_list = []for a in range(4):Qsa = 0prob, next_state, reward, done = self.env.P[s][a]Qsa = prob * (reward + self.gamma * self.v[next_state] * (1 - done))Qsa_list.append(Qsa * self.policy[s][a])new_v[s] = sum(Qsa_list)Delta_v = max(Delta_v, abs(self.v[s] - new_v[s]))self.v = new_vcount += 1print("策略评估进行%d轮后完成" % count)def PolicyImprovement(self):for s in range(self.env.nrow * self.env.ncol):Qsa_list = []for a in range(4):Qsa = 0prob, next_state, reward, done = self.env.P[s][a]Qsa = prob * (reward + self.gamma * self.v[next_state] * (1 - done))Qsa_list.append(Qsa)MaxQ = max(Qsa_list)# 计算有几个动作得到了最大的Q值CountQ = Qsa_list.count(MaxQ)# 让这些动作均分概率self.policy[s] = [1 / CountQ if Q == MaxQ else 0.0 for Q in Qsa_list]print("策略提升完成")return self.policydef policy_iteration(self): # 策略迭代while 1:self.PolicyEvaluation()# 将列表进行深拷贝,方便接下来进行比较old_policy = copy.deepcopy(self.policy)new_policy = self.PolicyImprovement()if old_policy == new_policy: breakdef print_agent(agent, action_meaning, disaster=[], end=[]):print("状态价值:")for i in range(agent.env.nrow):for j in range(agent.env.ncol):# 为了输出美观,保持输出6个字符print('%6.6s' % ('%.3f' % agent.v[i * agent.env.ncol + j]), end=' ')print()print("策略:")for i in range(agent.env.nrow):for j in range(agent.env.ncol):# 一些特殊的状态,例如悬崖漫步中的悬崖if (i * agent.env.ncol + j) in disaster:print('****', end=' ')elif (i * agent.env.ncol + j) in end: # 目标状态print('EEEE', end=' ')else:a = agent.policy[i * agent.env.ncol + j]pi_str = ''for k in range(len(action_meaning)):pi_str += action_meaning[k] if a[k] > 0 else 'o'print(pi_str, end=' ')print()def test01():env = CliffWalkingEnv()action_meaning = ['^', 'v', '<', '>']theta = 0.001gamma = 0.9agent = PolicyIteration(env, theta, gamma)agent.policy_iteration()print_agent(agent, action_meaning, list(range(37, 47)), [47])if __name__ == "__main__":test01()
输出结果:
策略评估进行60轮后完成
策略提升完成
策略评估进行72轮后完成
策略提升完成
策略评估进行44轮后完成
策略提升完成
策略评估进行12轮后完成
策略提升完成
策略评估进行1轮后完成
策略提升完成
状态价值:
-7.712 -7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
价值迭代:
class ValueIteration():def __init__(self, env, gamma, theta):self.env = envself.gamma = gammaself.theta = theta# 用于存储价值迭代后的策略self.policy = [None for i in range(self.env.nrow * self.env.ncol)]self.v = [0] * self.env.ncol * self.env.nrowdef Valueiteration(self):count = 0Delta_v = 100while Delta_v >= self.theta:Delta_v = 0new_v = [0] * self.env.ncol * self.env.nrowfor s in range(self.env.ncol * self.env.nrow):# 用动作价值函数来替换公式后面的一部分,计算状态s下的所有Q(s,a)价值Qsa_list = []for a in range(4):Qsa = 0prob, next_state, reward, done = self.env.P[s][a]Qsa = prob * (reward + self.gamma * self.v[next_state] * (1 - done))Qsa_list.append(Qsa)new_v[s] = max(Qsa_list)Delta_v = max(Delta_v, abs(self.v[s] - new_v[s]))self.v = new_vcount += 1print("价值迭代进行%d轮后完成" % count)self.PolicyOutput()def PolicyOutput(self):for s in range(self.env.nrow * self.env.ncol):Qsa_list = []for a in range(4):Qsa = 0prob, next_state, reward, done = self.env.P[s][a]Qsa = prob * (reward + self.gamma * self.v[next_state] * (1 - done))Qsa_list.append(Qsa)MaxQ = max(Qsa_list)# 计算有几个动作得到了最大的Q值CountQ = Qsa_list.count(MaxQ)# 让这些动作均分概率self.policy[s] = [1 / CountQ if Q == MaxQ else 0.0 for Q in Qsa_list]def test02():env = CliffWalkingEnv()action_meaning = ['^', 'v', '<', '>']theta = 0.001gamma = 0.9agent = ValueIteration(env, gamma, theta)agent.Valueiteration()print_agent(agent, action_meaning, list(range(37, 47)), [47])
输出结果: 可以看到迭代轮数明显减少
价值迭代进行15轮后完成
状态价值:
-7.712 -7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo **** **** **** **** **** **** **** **** **** **** EEEE
冰湖(Frozen Lake)
冰湖是 OpenAI Gym 库中的一个环境。OpenAI Gym 库中包含了很多有名的环境,例如 Atari 和MuJoCo,并且支持我们定制自己的环境。在之后的章节中,我们还会使用到更多来自 OpenAI Gym 库的环境。如图所示,冰湖环境和悬崖漫步环境相似,也是一个网格世界,大小为 4 × 4 4\times 4 4×4。每一个方格是一个状态,智能体起点状态 S S S在左上角,目标状态 G G G在右下角,中间还有若干冰洞 H H H。在每一个状态都可以采取上、下、左、右 4 个动作。由于智能体在冰面行走,因此每次行走都有一定的概率滑行到附近的其它状态,并且到达冰洞或目标状态时行走会提前结束。每一步行走的奖励是0,到达目标的奖励是 1。 Open AI GYMhttps://www.gymlibrary.dev/environments/toy_text/frozen_lake/

先创建 OpenAI Gym 中的 FrozenLake-v1 环境,并简单查看环境信息,然后找出冰洞和目标状态。
import gymenv = gym.make("FrozenLake-v1", render_mode="human") # 创建环境
env = env.unwrapped # 解封装才能访问状态转移矩阵P
env.reset()
# env.render() # 环境渲染,通常是弹窗显示或打印出可视化的环境holes = set()
ends = set()
for s in env.P:for a in env.P[s]:for s_ in env.P[s][a]:if s_[2] == 1.0: # 获得奖励为1,代表是目标ends.add(s_[1])if s_[3] == True:holes.add(s_[1])
holes = holes - ends
print("冰洞的索引:", holes)
print("目标的索引:", ends)for a in env.P[14]: # 查看目标左边一格的状态转移信息print(env.P[14][a])

冰洞的索引: {11, 12, 5, 7}
目标的索引: {15}
[(0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 13, 0.0, False), (0.3333333333333333, 14, 0.0, False)]
[(0.3333333333333333, 13, 0.0, False), (0.3333333333333333, 14, 0.0, False), (0.3333333333333333, 15, 1.0, True)]
[(0.3333333333333333, 14, 0.0, False), (0.3333333333333333, 15, 1.0, True), (0.3333333333333333, 10, 0.0, False)]
[(0.3333333333333333, 15, 1.0, True), (0.3333333333333333, 10, 0.0, False), (0.3333333333333333, 13, 0.0, False)]
PS1:关于env.render()以及相关的问题,可以参考github上的issuehttps://github.com/openai/gym/issues/3108
PS2:根据第 15 个状态(即目标左边一格,数组下标索引为 14)的信息,我们可以看到每个动作都会等概率“滑行”到 3 种可能的结果,这一点和悬崖漫步环境是不一样的。
策略迭代输出结果:
策略评估进行25轮后完成
策略提升完成
策略评估进行58轮后完成
策略提升完成
状态价值:0.069 0.061 0.074 0.056 0.092 0.000 0.112 0.000 0.145 0.247 0.300 0.000 0.000 0.380 0.639 0.000
策略:
<ooo ooo^ <ooo ooo^
<ooo **** <o>o ****
ooo^ ovoo <ooo ****
**** oo>o ovoo EEEE
价值迭代输出结果:
价值迭代进行61轮后完成
状态价值:0.069 0.061 0.074 0.056 0.092 0.000 0.112 0.000 0.145 0.247 0.300 0.000 0.000 0.380 0.639 0.000
策略:
<ooo ooo^ <ooo ooo^
<ooo **** <o>o ****
ooo^ ovoo <ooo ****
**** oo>o ovoo EEEE
参考
[1] 伯禹AI
[2] https://www.deepmind.com/learning-resources/introduction-to-reinforcement-learning-with-david-silver
[3] 动手学强化学习
[4] Reinforcement Learning