目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 数据增强
- 3. 模型构建
- 1)定义模型结构
- 2)优化损失函数
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目依赖于Keras深度学习模型,旨在对手语进行分类和实时识别。为了实现这一目标,项目结合了OpenCV库的相关算法,用于捕捉手部的位置,从而能够对视频流和图像中的手语进行实时识别。
首先,项目使用OpenCV库中的算法来捕捉视频流或图像中的手部位置。这可以涉及到肤色检测、运动检测或者手势检测等技术,以精确定位手语手势。
接下来,项目利用CNN深度学习模型,对捕捉到的手语进行分类,经过训练,能够将不同的手语手势识别为特定的类别或字符。
在实时识别过程中,视频流或图像中的手语手势会传递给CNN深度学习模型,模型会进行推断并将手势识别为相应的类别。这使得系统能够实时地识别手语手势并将其转化为文本或其他形式的输出。
总的来说,本项目结合了计算机视觉和深度学习技术,为手语识别提供了一个实时的解决方案。这对于听觉障碍者和手语使用者来说是一个有益的工具,可以帮助他们与其他人更轻松地进行交流和理解。
总体设计
本部分包括系统整体结构图和系统流程图。
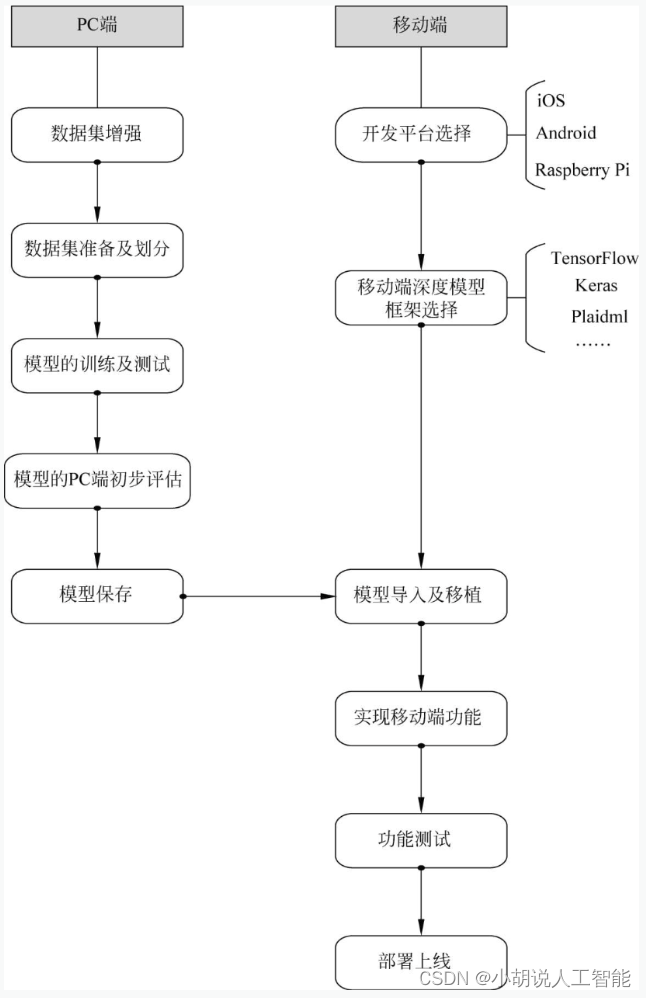
系统整体结构图
系统整体结构如图所示。
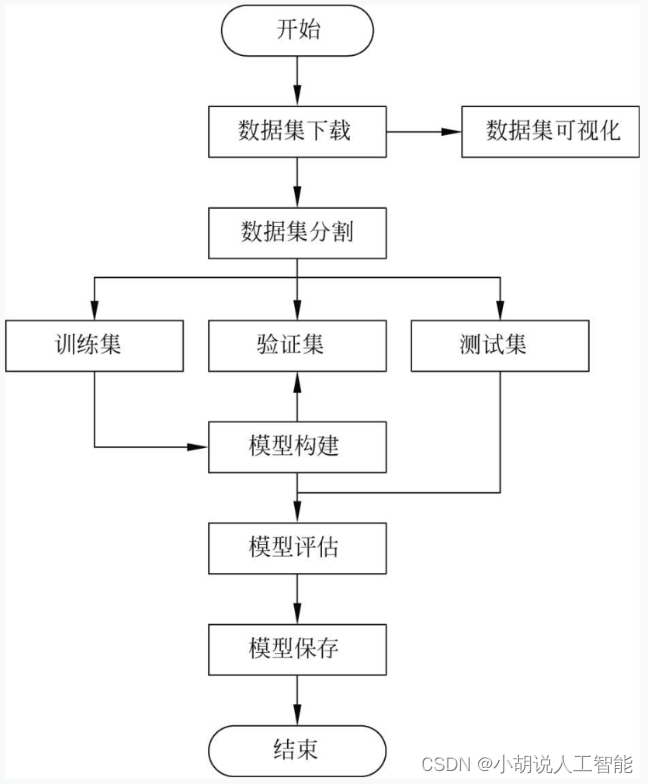
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、TensorFlow环境、 Keras环境和Android环境。
模块实现
本项目包括6个模块:数据预处理、数据增强、模型构建、模型训练及保存、模型评估和模型测试,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
在Kaggle上下载相应的数据集,下载地址为https://www.kaggle.com/ardamavi/sign-language-digits-dataset。加载在本地文件夹中下载的数据集,相关代码如下:
#导入相应包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras import layers
from keras import optimizers
from sklearn.model_selection import train_test_split
import os
#打印文件夹有关信息
print(os.listdir("/Users/chenjiyan/Desktop/信息系统设计项目/Sign-language-digits-dataset"))
#加载数据集
X=np.load("/Users/chenjiyan/Desktop/信息系统设计项目/Sign-language-digits-dataset/X.npy")
y=np.load("/Users/chenjiyan/Desktop/信息系统设计项目/Sign-language-digits-dataset/Y.npy")
print("The dataset loaded...")
#定义数据概览所需函数
#初始数据概览
#代码改自https://www.kaggle.com/serkanpeldek/cnn-practices-on-sign-language-digits
#One-hot标签解码
def decode_OneHotEncoding(label):label_new=list()for target in label:label_new.append(np.argmax(target)) #选择最大元素(即值为1)的索引label=np.array(label_new)return label
#因为原数据集标签标注有误,所以需要纠正数据集错误标签
def correct_mismatches(label): label_map={0:9,1:0,2:7,3:6,4:1,5:8,6:4,7:3,8:2,9:5} #正确标签映射列表label_new=list()for s in label:label_new.append(label_map[s])label_new=np.array(label_new)return label_new
#显示图像类别
def show_image_classes(image, label, n=10):label=decode_OneHotEncoding(label)label=correct_mismatches(label)fig, axarr=plt.subplots(nrows=n, ncols=n, figsize=(18, 18))axarr=axarr.flatten()plt_id=0start_index=0for sign in range(10):sign_indexes=np.where(label==sign)[0]for i in range(n):#逐行打印0~9的手语图片image_index=sign_indexes[i]axarr[plt_id].imshow(image[image_index], cmap='gray') axarr[plt_id].set_xticks([])axarr[plt_id].set_yticks([])axarr[plt_id].set_title("Sign :{}".format(sign))plt_id=plt_id+1plt.suptitle("{} Sample for Each Classes".format(n))plt.show()
number_of_pixels=X.shape[1]*X.shape[2]
number_of_classes=y.shape[1]
print(20*"*", "SUMMARY of the DATASET",20*"*")
print("an image size:{}x{}".format(X.shape[1], X.shape[2])) #获取图片像素大小
print("number of pixels:",number_of_pixels)
print("number of classes:",number_of_classes)
y_decoded=decode_OneHotEncoding(y.copy()) #标签解码
sample_per_class=np.unique(y_decoded, return_counts=True)
print("Number of Samples:{}".format(X.shape[0]))
for sign, number_of_sample in zip(sample_per_class[0], sample_per_class[1]):print(" {} sign has {} samples.".format(sign, number_of_sample))
print(65*"*")
show_image_classes(image=X, label=y.copy())
数据集预览效果如图所示。

2. 数据增强
为方便展示生成图片的效果及对参数进行微调,本项目未使用keras直接训练生成器,而是先生成一个增强过后的数据集,再应用于模型训练。
在数据增强中,首先,定义一个图片生成器;其次,通过生成器的flow()方法迭代进行数据增强。相关代码如下:
from keras.preprocessing.image import ImageDataGenerator
X_loaded = X.reshape(X.shape+(1,))
print("shape of X_loaded:",X_loaded.shape)
#定义图片生成器
datagen = ImageDataGenerator(featurewise_center=False, #使数据集中心化, 按feature执行featurewise_std_normalization=False, #使输入数据的每个样本均值为0rotation_range=20, #设定旋转角度width_shift_range=0.2, height_shift_range=0.2, #设定随机水平及垂直位移的幅度brightness_range=[0.1, 1.3], #亮度调整horizontal_flip=False) #设定不发生水平镜像
#迭代进行数据增强输出
X_added=X_loaded[0]
y_added=y[0]
X_added = X_added.reshape((1,)+X_added.shape) #改变输入维数
print("shape of X_added:",X_added.shape)
i = 0
for batch in datagen.flow(X_loaded,y, batch_size=11, shuffle=True, seed=None): if i==0: print("shape of X in each batch:",batch[0].shape,"\n","shape of y in each batch:",batch[1].shape)X_added=np.vstack((X_added,batch[0])) #添加图片y_added=np.vstack((y_added,batch[1])) #添加标签
i += 1if i%100==0:print("process:",i,"/",X_loaded.shape[0]) #输出处理进度if i >= X_loaded.shape[0]: # 生成器会退出循环,生成数据总量为原来的batch_size倍break
X_added=np.vstack((X_added,X_loaded))
#最后添加原数据,此时生成数据为原来的batch_size+1倍
y_added=np.vstack((y_added,y))
print("shape of X_added:",X_added.shape)
print("shape of y_added:",y_added.shape)
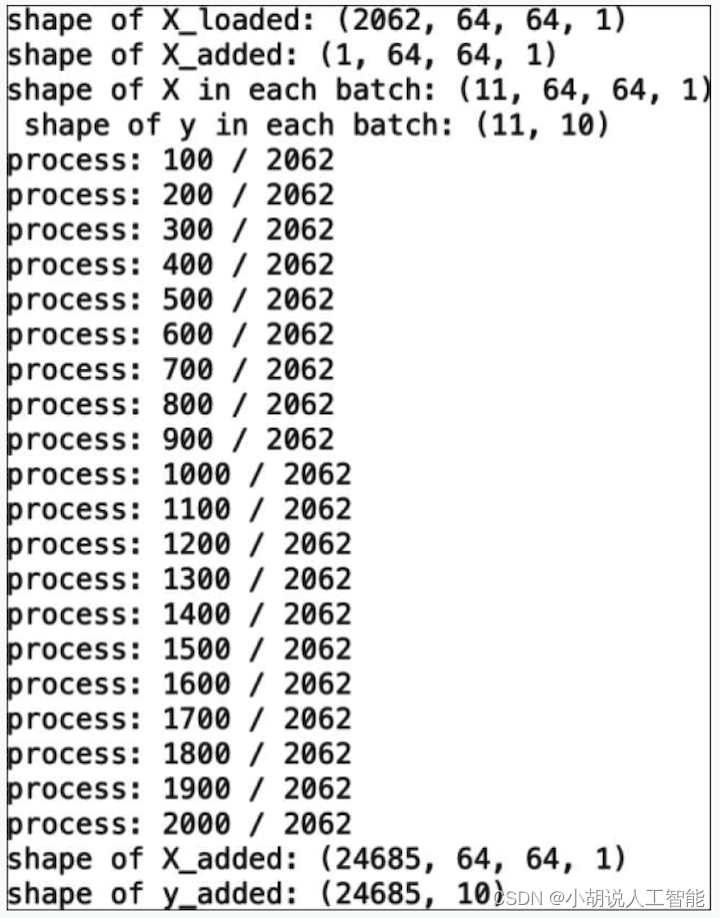
数据增强过程如图所示。
数据预览效果如图所示。

3. 模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
1)定义模型结构
本次使用的卷积神经网络由四个卷积块及后接的全连接层组成,每个卷积块包含一个卷积层,并后接一个最大池化层进行数据的降维处理。为防止梯度消失以及梯度爆炸,进行了数据批量归一化,并设置丢弃正则化。
相关代码如下:
#模型改自https://www.kaggle.com/serkanpeldek/cnn-practices-on-sign-language-digits
def build_conv_model_8():model = Sequential()model.add(layers.Convolution2D(32, (3, 3), activation='relu', input_shape=(64, 64, 1)))model.add(layers.MaxPooling2D((2, 2))) #最大池化层model.add(layers.BatchNormalization()) #批量归一化model.add(layers.Dropout(0.25)) #随机丢弃结点model.add(layers.Convolution2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.BatchNormalization())model.add(layers.Dropout(0.25))model.add(layers.Convolution2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.BatchNormalization())model.add(layers.Dropout(0.25))model.add(layers.Convolution2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.BatchNormalization())model.add(layers.Dropout(0.25))model.add(layers.Flatten())model.add(layers.Dropout(0.5))model.add(layers.Dense(256, activation='relu'))model.add(layers.Dense(10, activation='softmax'))return model
model=build_conv_model_8()
model.summary()
2)优化损失函数
确定模型架构之后进行编译。这是多类别的分类问题,需要使用交叉熵作为损失函数。由于所有标签都带有相似的权重,经常使用精确度作为性能指标。RMSprop是常用的梯度下降方法,本项目将使用该方法优化模型参数。
相关代码如下:
optimizer=optimizers.RMSprop(lr=0.0001) #优化器
model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=['accuracy'])
相关其它博客
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(一)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(三)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(四)
基于Android+OpenCV+CNN+Keras的智能手语数字实时翻译——深度学习算法应用(含Python、ipynb工程源码)+数据集(五)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。