一、概述
linux内存管理核心是伙伴系统,slab,slub,slob是基于伙伴系统之上提供api,用于内核内存分配释放管理,适用于小内存(小于1页)分配与释放,当然大于1页,也是可以的.小于一页的,我们也可以直接用伙伴系统api申请内存和释放,但伙伴系统最小单位是页,如果我们只需要100byte,伙伴系统申请内存最小1页(一般情况1页是4k, 具体看系统PAGE_SHIFT定义),显然就很浪费
二、slab核心部分
如下图,表示从伙伴系统分配来的一块连续内存,slab会将这块内存,划分为:保留,slab,kmem_bufctl_t,实际分配使用的memory。这四个部分。
图一 :

四个部分,分别说明:
保留:碎片部分,slab无法分配使用,作为保留不用,同时还可以预防边界,内存“踩踏”
slab:struct slab结构实体,用于管理如上图,一块内存(大方框)
struct slab定义在mm/slab.c
struct slab {union {struct {struct list_head list;//链接到struct kmem_cache中slabs_partial,slabs_full,slabs_free三者之一unsigned long colouroff;//保留区域和slab区域内存空间大小void *s_mem; //整个虚线格子区域内存起始地址unsigned int inuse; //被分配使用小内存块数量,即虚线格子数量kmem_bufctl_t free;//始终为空闲小内存块索引,即虚线格子索引unsigned short nodeid;//多核cpu,cpu id};struct slab_rcu __slab_cover_slab_rcu;};
};
kmem_bufctl_t:从定义 kmem_bufctl_t
typedef unsigned int kmem_bufctl_t;
看得出这部分内存空间,是存放无符号整型数据,其中虚线部分格子,每个格子表示实际分配使用的小内存块,总共有多少个这样的格子,那么kmem_bufctl_t这部分内存空间,就存放着多少个无符号整数,这些无符号整数所需要的空间大小,就是“kmem_bufctl_t”这部分内存空间大小。每个kmem_bufctl_t都存放着一个虚线格子编号,虚线格子,从上往下顺序编号,起始编号从0开始,最后一个存放BUFCTL_END表示结束。很关键一点,每个无符号整数表示下一个空闲小内存块编号。
#define BUFCTL_END (((kmem_bufctl_t)(~0U))-0)
实际分配使用的memory:slab每次分配,都是分配一小块内存(一个虚线格子)返回给申请者。那么这样的虚线格子,每一个格子表示多大空间的内存?总共有多少虚线格子(小内存块总数)?
首先,很重要的,slab一次分配内存空间大小,是2的幂次方byte,从2的0次方起始,依次:2的1次方,2的2次方,2的3次方,…2的n次方,n的最大值由宏KMALLOC_MAX_ORDER定义。如申请10个byte,实际申请到16个byte(2的4次方)。
如上图,大矩形,表示从伙伴系统分配到一块内存空间,其中内存空间size由函数calculate_slab_order()计算得出,此函数基本过程,可精简(仅为理解处理逻辑,不做实际编译运行)为如下一段代码:
size_t slab_size;
int nr_objs;
size_t mgmt_size;
size_t left_over;
size_t buffer_size;
unsigned long gfporder;
for (gfporder = 0; gfporder <= KMALLOC_MAX_ORDER; gfporder++)
{slab_size = PAGE_SIZE << gfporder;nr_objs = (slab_size - sizeof(struct slab)) /(buffer_size + sizeof(kmem_bufctl_t));mgmt_size = sizeof(struct slab)+nr_objs*sizeof(kmem_bufctl_t);left_over = slab_size - nr_objs*buffer_size - mgmt_size;if (left_over * 8 <= (PAGE_SIZE << gfporder))break;
}
其中buffer_size,是上面提到,2的n次方个byte,即上图中一个虚线格子内存空间大小
nr_objs表示上图虚线格子总数,
图中kmem_bufctl_t,表示nr_objs*sizeof(kmem_bufctl_t)内存空间
图中slab,表示sizeof(struct slab)内存空间
left_over表示碎片部分,无法分配使用内存空间
基本思路,首先用1页的空间,按照如上代码,计算得到nr_objs,mgmt_size,left_over,如果8倍碎片(left_over * 8)小于等于从伙伴系统分配到内存空间大小(PAGE_SIZE << gfporder),则结束。可以看出,上图大方框内存空间大小,是这样计算过程:首先1页(即4k),如果不满足,再用2页试探,3页试探,…n页试探,直到满足8倍碎片内存空间小于等于伙伴系统分配内存空间。n的最大值KMALLOC_MAX_ORDER。
kmem_bufctl_t与虚线格子关系:
如下代码,是对图中kmem_bufctl_t部分初始化:
static inline void *index_to_obj(struct kmem_cache *cache, struct slab *slab,unsigned int idx)
{return slab->s_mem + cache->size * idx;
}static inline kmem_bufctl_t *slab_bufctl(struct slab *slabp)
{return (kmem_bufctl_t *) (slabp + 1);
}static void cache_init_objs(struct kmem_cache *cachep,struct slab *slabp)
{int i;for (i = 0; i < cachep->num; i++) {void *objp = index_to_obj(cachep, slabp, i);...slab_bufctl(slabp)[i] = i + 1;}slab_bufctl(slabp)[i - 1] = BUFCTL_END;
}
slabp表示图中slab区域内存起始地址
slab->s_mem虚线格子整个区域内存起始地址
cache->size一个虚线格子内存空间的大小
此时slabp->free = 0
分配内存时,通过kmem_bufctl_t区域的值,获取一个虚线格子内存起始地址objp:
static void *slab_get_obj(struct kmem_cache *cachep, struct slab *slabp,int nodeid)
{void *objp = index_to_obj(cachep, slabp, slabp->free);kmem_bufctl_t next;slabp->inuse++;next = slab_bufctl(slabp)[slabp->free];...slabp->free = next;return objp;//一个空闲虚线格子内存地址
}
释放内存时,对kmem_bufctl_t区域修改:
static inline unsigned int obj_to_index(const struct kmem_cache *cache,const struct slab *slab, void *obj)
{u32 offset = (obj - slab->s_mem);return reciprocal_divide(offset, cache->reciprocal_buffer_size);
}
static void slab_put_obj(struct kmem_cache *cachep, struct slab *slabp,void *objp, int nodeid)
{unsigned int objnr = obj_to_index(cachep, slabp, objp);...slab_bufctl(slabp)[objnr] = slabp->free;slabp->free = objnr;slabp->inuse--;
}
objp表示被释放内存,起始地址
reciprocal_divide(offset, cache->reciprocal_buffer_size)可看作offset除以cache->size
由此可知,是通过kmem_bufctl_t区域管理着,虚线格子区域内存分配和释放,slabp->free始终为空闲小内存块(虚线格子)索引。
小内存块索引编号,存储在kmem_bufctl_t区域,这些索引编号会形成一条有序的空闲链,slabp->free为链的顶端。
上面代码中出现struct kmem_cache,这个用于管理多个像上图中大方框的内存,即管理多个slab内存。下面,将从kmem_cache初始化,slab内存分配,slab释放三个方面描述。
三、kmem_cache初始化
首先看下struc kmem_cache:
定义在include/linux/slab_def.h
struct kmem_cache {
/* 1) Cache tunables. Protected by cache_chain_mutex */unsigned int batchcount;unsigned int limit;unsigned int shared;unsigned int size;u32 reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */unsigned int flags; /* constant flags */unsigned int num; /* # of objs per slab *//* 3) cache_grow/shrink *//* order of pgs per slab (2^n) */unsigned int gfporder;/* force GFP flags, e.g. GFP_DMA */gfp_t allocflags;size_t colour; /* cache colouring range */unsigned int colour_off; /* colour offset */struct kmem_cache *slabp_cache;unsigned int slab_size;/* constructor func */void (*ctor)(void *obj);/* 4) cache creation/removal */const char *name;struct list_head list;int refcount;int object_size;int align;/* 5) statistics */
#ifdef CONFIG_DEBUG_SLABunsigned long num_active;unsigned long num_allocations;unsigned long high_mark;unsigned long grown;unsigned long reaped;unsigned long errors;unsigned long max_freeable;unsigned long node_allocs;unsigned long node_frees;unsigned long node_overflow;atomic_t allochit;atomic_t allocmiss;atomic_t freehit;atomic_t freemiss;/** If debugging is enabled, then the allocator can add additional* fields and/or padding to every object. size contains the total* object size including these internal fields, the following two* variables contain the offset to the user object and its size.*/int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEMstruct memcg_cache_params *memcg_params;
#endif/* 6) per-cpu/per-node data, touched during every alloc/free *//** We put array[] at the end of kmem_cache, because we want to size* this array to nr_cpu_ids slots instead of NR_CPUS* (see kmem_cache_init())* We still use [NR_CPUS] and not [1] or [0] because cache_cache* is statically defined, so we reserve the max number of cpus.** We also need to guarantee that the list is able to accomodate a* pointer for each node since "nodelists" uses the remainder of* available pointers.*/struct kmem_cache_node **node;struct array_cache *array[NR_CPUS + MAX_NUMNODES];/** Do not add fields after array[]*/
};初始化函数调用过程:
start_kernel() —>mm_init()—>kmem_cache_init()
kmem_cache_init()函数定义在mm/slab.c中
kmem_cache初始化完,形成的结构图,仅个人理解方式:
图二 :

和slub很接近,但图中多了“slab”,这里的“slab”表示就是《slab核心部分》一节描述:保留,slab,kmem_bufctl_t这三部分;
图中标注的“slab”,其实是内存管理的开销,而slub没有这样额外的开销。当系统slab内存块数量很多时,这种额外开销,也是不容忽视的。如大型服务器,基本用的都是slub。
图中左边kmem_cache方框初始化:
在mm/slab_common.c定义有:
LIST_HEAD(slab_caches);//图中左边,链表头部
struct kmem_cache *kmem_cache;
在mm/slab.c定义函数kmem_cache_init(), 主要初始化kmem_cache:
#define BOOT_CPUCACHE_ENTRIES 1
static struct kmem_cache kmem_cache_boot = {.batchcount = 1,.limit = BOOT_CPUCACHE_ENTRIES,.shared = 1,.size = sizeof(struct kmem_cache),.name = "kmem_cache",
};void __init kmem_cache_init(void)
{int i;kmem_cache = &kmem_cache_boot;setup_node_pointer(kmem_cache);if (num_possible_nodes() == 1)use_alien_caches = 0;for (i = 0; i < NUM_INIT_LISTS; i++)kmem_cache_node_init(&init_kmem_cache_node[i]);set_up_node(kmem_cache, CACHE_CACHE);/** Fragmentation resistance on low memory - only use bigger* page orders on machines with more than 32MB of memory if* not overridden on the command line.*/if (!slab_max_order_set && totalram_pages > (32 << 20) >> PAGE_SHIFT)slab_max_order = SLAB_MAX_ORDER_HI;/* Bootstrap is tricky, because several objects are allocated* from caches that do not exist yet:* 1) initialize the kmem_cache cache: it contains the struct* kmem_cache structures of all caches, except kmem_cache itself:* kmem_cache is statically allocated.* Initially an __init data area is used for the head array and the* kmem_cache_node structures, it's replaced with a kmalloc allocated* array at the end of the bootstrap.* 2) Create the first kmalloc cache.* The struct kmem_cache for the new cache is allocated normally.* An __init data area is used for the head array.* 3) Create the remaining kmalloc caches, with minimally sized* head arrays.* 4) Replace the __init data head arrays for kmem_cache and the first* kmalloc cache with kmalloc allocated arrays.* 5) Replace the __init data for kmem_cache_node for kmem_cache and* the other cache's with kmalloc allocated memory.* 6) Resize the head arrays of the kmalloc caches to their final sizes.*//* 1) create the kmem_cache *//** struct kmem_cache size depends on nr_node_ids & nr_cpu_ids*/create_boot_cache(kmem_cache, "kmem_cache",offsetof(struct kmem_cache, array[nr_cpu_ids]) +nr_node_ids * sizeof(struct kmem_cache_node *),SLAB_HWCACHE_ALIGN);list_add(&kmem_cache->list, &slab_caches);/* 2+3) create the kmalloc caches *//** Initialize the caches that provide memory for the array cache and the* kmem_cache_node structures first. Without this, further allocations will* bug.*/kmalloc_caches[INDEX_AC] = create_kmalloc_cache("kmalloc-ac",kmalloc_size(INDEX_AC), ARCH_KMALLOC_FLAGS);if (INDEX_AC != INDEX_NODE)kmalloc_caches[INDEX_NODE] =create_kmalloc_cache("kmalloc-node",kmalloc_size(INDEX_NODE), ARCH_KMALLOC_FLAGS);slab_early_init = 0;/* 4) Replace the bootstrap head arrays */{struct array_cache *ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);memcpy(ptr, cpu_cache_get(kmem_cache),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);kmem_cache->array[smp_processor_id()] = ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);BUG_ON(cpu_cache_get(kmalloc_caches[INDEX_AC])!= &initarray_generic.cache);memcpy(ptr, cpu_cache_get(kmalloc_caches[INDEX_AC]),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);kmalloc_caches[INDEX_AC]->array[smp_processor_id()] = ptr;}/* 5) Replace the bootstrap kmem_cache_node */{int nid;for_each_online_node(nid) {init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);init_list(kmalloc_caches[INDEX_AC],&init_kmem_cache_node[SIZE_AC + nid], nid);if (INDEX_AC != INDEX_NODE) {init_list(kmalloc_caches[INDEX_NODE],&init_kmem_cache_node[SIZE_NODE + nid], nid);}}}create_kmalloc_caches(ARCH_KMALLOC_FLAGS);
}图二中,方框“kmem_cache”初始化:
create_boot_cache(kmem_cache, “kmem_cache”,
offsetof(struct kmem_cache, array[nr_cpu_ids]) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
create_boot_cache()函数为《slab核心部分》主要实现函数,
create_boot_cache()还会调用setup_cpu_cache()对struct kmem_cache中array,node初始化,其作用在下面《slab分配和释放》中描述
而“kmem_cache”用来管理结构struct kmem_cache实体所需内存空间分配和释放,如图中memory0中s0, s1, s2, s3, … , sn表示struct kmem_cache实体,memory0可以看作《slab核心部分》图中的大方框,s0,s1,s2,…,sn就是memory0中的虚线格子。memory1,memory2,…,memoryN中同样存在这样“虚线格子”。注意,memory0,memory1,memory2,…,memoryN方框大小不代表实际内存空间的大小。
图中“kmem_cache”用来管理memory0中小内存块(空间大小为sizeof(struct kmem_cache))分配和释放
s1也是一个sturt kmem_cache实体,内存空间大小为sizeof(struct kmem_cache),可以看出,s1是用来管理memory1中小内存块分配和释放,小内存块size为kmalloc_size(INDEX_NODE)。
其他类似。
当向伙伴系统申请一块memory0,被分配完时(memory0里面虚线格子分配使用完),会再次向伙伴系统申请一块内存。
将“kmem_cache”加入到链表中:
list_add(&kmem_cache->list, &slab_caches);
kmalloc_caches定义:
struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];
slab分配内存大小,分阶级的,分别是:2的0次方byte,2的1次方byte, 2的2次方byte,2的3次方byte,… 2的KMALLOC_SHIFT_HIGH + 1次方byte。申请内存空间时,查找到更接近申请所需空间分配。大致可理解:申请5byte,实际分配8byte空间; 申请20byte,实际分配32byte空间。具体在create_kmalloc_caches()函数中会涉及到。
kmalloc_caches[0]用来管理多个内存空间大小为1byte(2的0次方个byte)内存块。
kmalloc_caches[1]用来管理多个内存空间大小为2byte(2的1次方个byte)内存块。
kmalloc_caches[2]用来管理多个内存空间大小为4byte(2的2次方个byte)内存块。
kmalloc_caches[3]用来管理多个内存空间大小为8byte(2的3次方个byte)内存块。
…
kmalloc_caches[8]用来管理多个内存空间大小为256byte(2的8次方个byte)内存块。
kmalloc_caches[9]用来管理多个内存空间大小为512byte(2的9次方个byte)内存块。
kmalloc_caches[10]用来管理多个内存空间大小为1024byte(2的10次方个byte)内存块。
…
依此类推。
当然实际中,部分不存在,像1byte, 2byte, 4byte…内存块是不存在的,在create_kmalloc_caches()函数中会体现出来。
因此,slab无法分配大于2的KMALLOC_SHIFT_HIGH + 1次方byte内存空间,超过将直接调用伙伴系统api分配内存。
kmalloc_caches[INDEX_AC] = create_kmalloc_cache(“kmalloc-ac”,
kmalloc_size(INDEX_AC), ARCH_KMALLOC_FLAGS);
INDEX_AC定义:
#define INDEX_AC kmalloc_index(sizeof(struct arraycache_init))
kmalloc_index()在一定条件满足情况,函数计算并返回2的幂指数
/** Figure out which kmalloc slab an allocation of a certain size* belongs to.* 0 = zero alloc* 1 = 65 .. 96 bytes* 2 = 120 .. 192 bytes* n = 2^(n-1) .. 2^n -1*/
static __always_inline int kmalloc_index(size_t size)
{if (!size)return 0;if (size <= KMALLOC_MIN_SIZE)return KMALLOC_SHIFT_LOW;if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)return 1;if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)return 2;if (size <= 8) return 3;if (size <= 16) return 4;if (size <= 32) return 5;if (size <= 64) return 6;if (size <= 128) return 7;if (size <= 256) return 8;if (size <= 512) return 9;if (size <= 1024) return 10;if (size <= 2 * 1024) return 11;if (size <= 4 * 1024) return 12;if (size <= 8 * 1024) return 13;if (size <= 16 * 1024) return 14;if (size <= 32 * 1024) return 15;if (size <= 64 * 1024) return 16;if (size <= 128 * 1024) return 17;if (size <= 256 * 1024) return 18;if (size <= 512 * 1024) return 19;if (size <= 1024 * 1024) return 20;if (size <= 2 * 1024 * 1024) return 21;if (size <= 4 * 1024 * 1024) return 22;if (size <= 8 * 1024 * 1024) return 23;if (size <= 16 * 1024 * 1024) return 24;if (size <= 32 * 1024 * 1024) return 25;if (size <= 64 * 1024 * 1024) return 26;BUG();/* Will never be reached. Needed because the compiler may complain */return -1;
}
kmalloc_size(INDEX_AC)计算小内存块的size,即《slab核心部分》图中一个虚线格子的空间
create_kmalloc_cache()初始化kmalloc_cache主要函数:
struct kmem_cache *__init create_kmalloc_cache(const char *name, size_t size,unsigned long flags)
{struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);if (!s)panic("Out of memory when creating slab %s\n", name);create_boot_cache(s, name, size, flags);list_add(&s->list, &slab_caches);s->refcount = 1;return s;
}
从memory0中分配一块内存(内存空间sizeof(struct kmem_cache)), 如图中的s0,s1,s2…
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
从kmalloc_caches[INDEX_AC]中分配一小块内存:
ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);
以下,将静态内存,替换为动态:
kmem_cache->array[smp_processor_id()] = ptr;
kmalloc_caches[INDEX_AC]->array[smp_processor_id()] = ptr;
init_list(kmem_cache, &init_kmem_cache_node[CACHE_CACHE + nid], nid);
…
四 、slab分配和释放:
slab分配内存流程,如下:
图三

图中为了方便描述,用A1, A2, A3, A4, A5, A6, A7, A8, A9, A10, A11, A12对处理过程编号。
常用分配函数:
定义在include/linux/slab.h:
/*** kzalloc - allocate memory. The memory is set to zero.* @size: how many bytes of memory are required.* @flags: the type of memory to allocate (see kmalloc).*/
static inline void *kzalloc(size_t size, gfp_t flags)
{return kmalloc(size, flags | __GFP_ZERO);
}/*** kcalloc - allocate memory for an array. The memory is set to zero.* @n: number of elements.* @size: element size.* @flags: the type of memory to allocate (see kmalloc).*/
static inline void *kcalloc(size_t n, size_t size, gfp_t flags)
{return kmalloc_array(n, size, flags | __GFP_ZERO);
}
定义在include/linux/slab_def.h中:
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{struct kmem_cache *cachep;void *ret;if (__builtin_constant_p(size)) {//当size为常量时,为真,编译时确定//当size为变量时,为假,编译时确定int i;if (!size)return ZERO_SIZE_PTR;if (WARN_ON_ONCE(size > KMALLOC_MAX_SIZE))return NULL;i = kmalloc_index(size);#ifdef CONFIG_ZONE_DMAif (flags & GFP_DMA)cachep = kmalloc_dma_caches[i];else
#endifcachep = kmalloc_caches[i];//图三A2动作ret = kmem_cache_alloc_trace(cachep, flags, size);return ret;}return __kmalloc(size, flags);//size为变量时,
}
slab_def.h会被包含在slab.h文件中。
其中kzalloc()直接调用kmalloc(), 加入标志__GFP_ZERO,带这个标志,伙伴系统会将分配的内存清零,一般用的是硬件技术清零,比软件写零速度快。
kcalloc(size_t n, size_t size, gfp_t flags)分配n个空间大小为size的内存,虽然没有调用kmalloc(), 但都会在图三A2处走到一起
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,unsigned long caller)
{struct kmem_cache *cachep;....cachep = kmalloc_slab(size, flags);//图三A2动作...
}
图三A3动作主要函数slab_alloc(),
从A2到A3有多条路:
第一条:kmalloc() --> kmem_cache_alloc_trace() --> slab_alloc()
第二条:kmalloc() --> __kmalloc() --> __do_kmalloc() --> slab_alloc()
第三条:kcalloc() --> __kmalloc() --> __do_kmalloc() --> slab_alloc()
第四条:kzmalloc --> kmalloc() … (第一,二条路)
函数slab_alloc()进入到A3,还需要一些过程:
slab_alloc() --> __do_cache_alloc() --> __do_cache_alloc() --> ____cache_alloc()
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{void *objp;struct array_cache *ac;bool force_refill = false;check_irq_off();ac = cpu_cache_get(cachep);if (likely(ac->avail)) {ac->touched = 1;objp = ac_get_obj(cachep, ac, flags, false);//图三A3动作/** Allow for the possibility all avail objects are not allowed* by the current flags*/if (objp) {//图三A5STATS_INC_ALLOCHIT(cachep);goto out;//跳入,图三中A4}force_refill = true;}STATS_INC_ALLOCMISS(cachep);objp = cache_alloc_refill(cachep, flags, force_refill);//这个函数调用,将会进入图三中A6/** the 'ac' may be updated by cache_alloc_refill(),* and kmemleak_erase() requires its correct value.*/ac = cpu_cache_get(cachep);out://图三A4/** To avoid a false negative, if an object that is in one of the* per-CPU caches is leaked, we need to make sure kmemleak doesn't* treat the array pointers as a reference to the object.*/if (objp)kmemleak_erase(&ac->entry[ac->avail]);return objp;
}
函数cache_alloc_refill()定义:
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags,bool force_refill)
{int batchcount;struct kmem_cache_node *n;struct array_cache *ac;int node;check_irq_off();node = numa_mem_id();if (unlikely(force_refill))goto force_grow;
retry://这里同样算是,图三中A3ac = cpu_cache_get(cachep);batchcount = ac->batchcount;if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {/** If there was little recent activity on this cache, then* perform only a partial refill. Otherwise we could generate* refill bouncing.*/batchcount = BATCHREFILL_LIMIT;}n = cachep->node[node];BUG_ON(ac->avail > 0 || !n);spin_lock(&n->list_lock);/* See if we can refill from the shared array */if (n->shared && transfer_objects(ac, n->shared, batchcount)) {n->shared->touched = 1;goto alloc_done;}while (batchcount > 0) {struct list_head *entry;struct slab *slabp;/* Get slab alloc is to come from. */entry = n->slabs_partial.next;//图三A6if (entry == &n->slabs_partial) {//图三A7n->free_touched = 1;entry = n->slabs_free.next;//图三A9if (entry == &n->slabs_free)//图三A11goto must_grow;//跳转到A12}slabp = list_entry(entry, struct slab, list); ---------------------------check_slabp(cachep, slabp); |check_spinlock_acquired(cachep); ||/* |* The slab was either on partial or free list so |* there must be at least one object available for |* allocation. |*/ |BUG_ON(slabp->inuse >= cachep->num); ||while (slabp->inuse < cachep->num && batchcount--) { |STATS_INC_ALLOCED(cachep); |STATS_INC_ACTIVE(cachep); |STATS_SET_HIGH(cachep); |这部分,是图三中A8, A10处理ac_put_obj(cachep, ac, slab_get_obj(cachep, slabp,node)); |} |check_slabp(cachep, slabp); ||/* move slabp to correct slabp list: */ |list_del(&slabp->list); |if (slabp->free == BUFCTL_END) |list_add(&slabp->list, &n->slabs_full); |else |list_add(&slabp->list, &n->slabs_partial); |} ------------------------------------must_grow:n->free_objects -= ac->avail;
alloc_done:spin_unlock(&n->list_lock);if (unlikely(!ac->avail)) {int x;
force_grow:x = cache_grow(cachep, flags | GFP_THISNODE, node, NULL);//图三中A12,主要函数调用/* cache_grow can reenable interrupts, then ac could change. */ac = cpu_cache_get(cachep);node = numa_mem_id();/* no objects in sight? abort */if (!x && (ac->avail == 0 || force_refill))return NULL;if (!ac->avail) /* objects refilled by interrupt? */goto retry;}ac->touched = 1;return ac_get_obj(cachep, ac, flags, force_refill);
}slab释放:
slab释放内存处理流程:
图四:
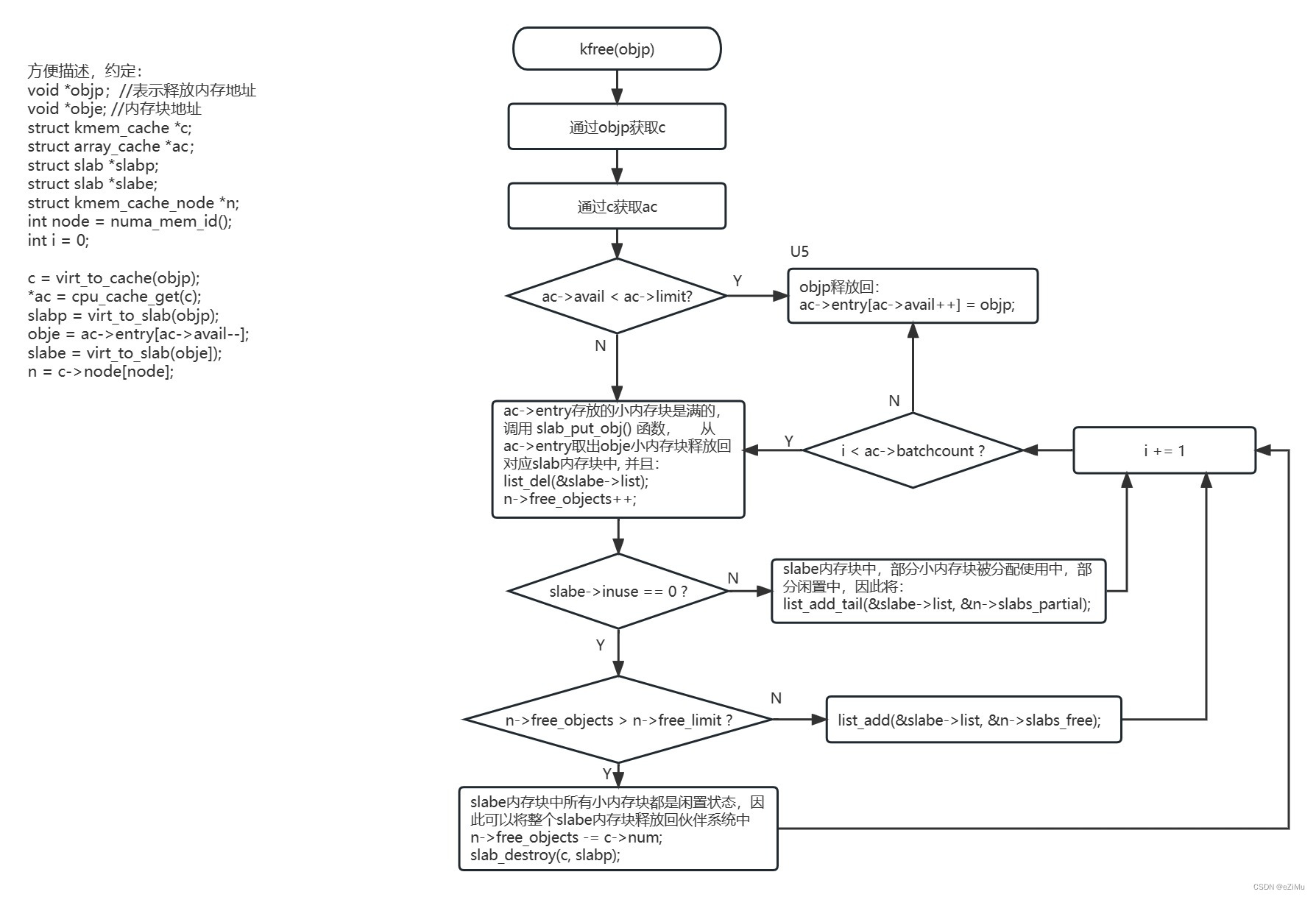
kfree()函数定义在mm/slab.c
void kfree(const void *objp)
objp释放小内存块,起始地址