从今年5月起,各行业关于800G光模块的新闻此起彼伏,不断被讨论。华工正源、中际旭创、Coherent等公司纷纷发布公告提交业绩/投资调研会议记录,光迅6月也发布公告解释为何其股票突然大幅增长。到底是发生了什么事情,造成如此大的轰动?
市场背景
原来,这都源于今年5月中旬,NVIDIA发布了面向AI的DGX GH200,结合ChatGPT爆火所带来的广阔AI市场,这一系列连锁反应,点燃了AI算力时代。据source photonics提供的数据得知,一个AI/ML集群就需要180支800G光模块,1:1收敛比,则还需要320支800G光模块。而ChatGPT运行所需要的800G光模块更是高达10万支。为推动行业发展,谷歌、Meta、微软等各大互联网巨头纷纷加入AI市场,800G光模块订单纷至沓来。
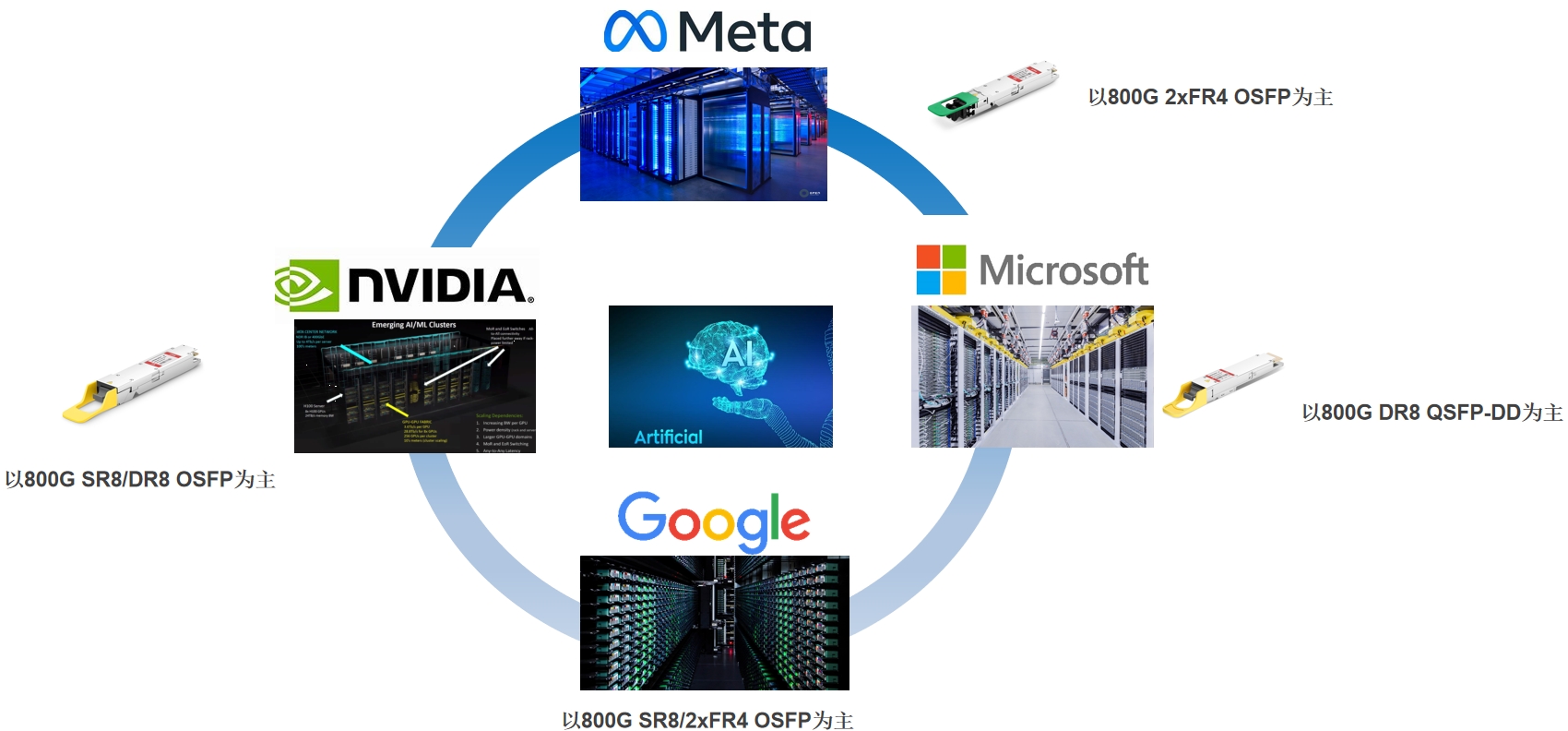
目前的800G光模块,主要就是旭创和Finisar为主的,多模光模块数量大,单模数量小。今年年初需求量在300万支左右,预计今年后半年,需求量会翻倍,到2024年时,800G光模块市场需求量会达到千万级别。
这只是一个行业预估,一方面,大家的产能还在初期的阶段,早两三年,各家的800G Demo就已经在演示了,今年OFC更多的是200G EML的内容,800G光模块产业化,第一步是8x100G,未来是4x200G,再接下去就是8x200G的1.6T光模块。
光模块应用
AI应用网络架构
H100最新架构试算:8个节点(单服务器),NVLink下需要18对、36个osfp,也就是36个800G一个POD集群需要36x32=1152个800G光模块。若需要InfiniBand网络,则是传统叶脊双层架构,需要800G或2x400G ( NDR),数量关系与普通集群差异不大,依据不同规模可另外计算。
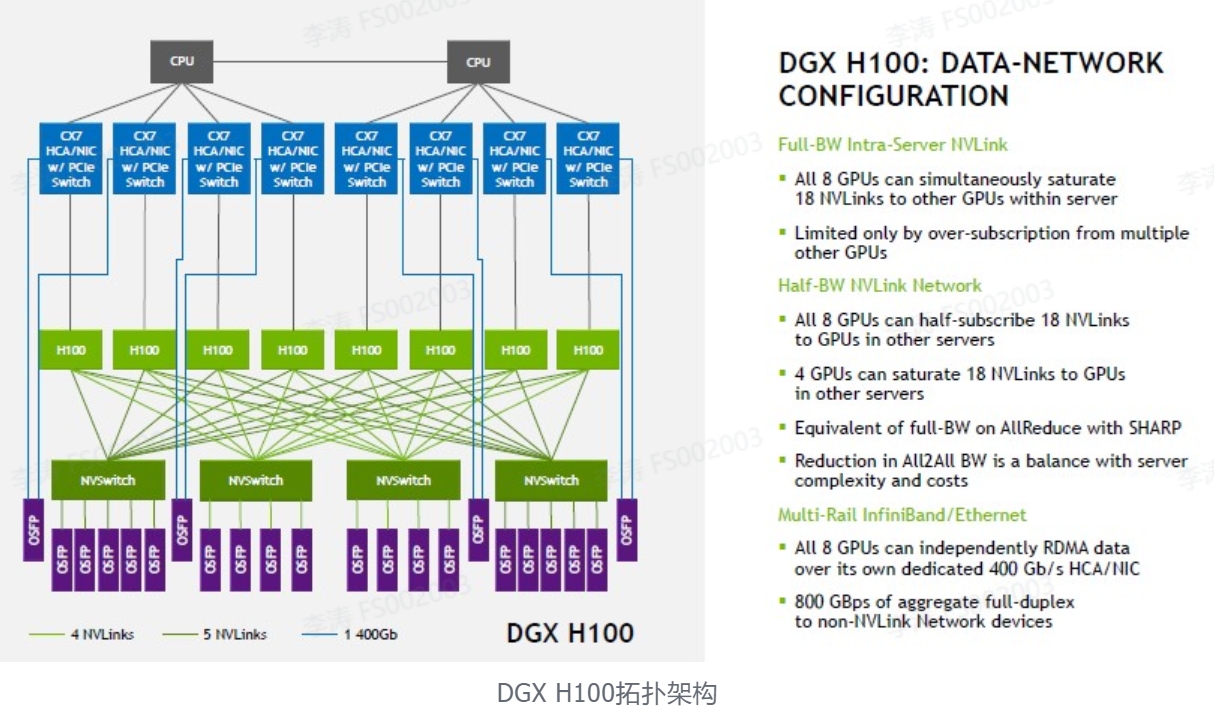
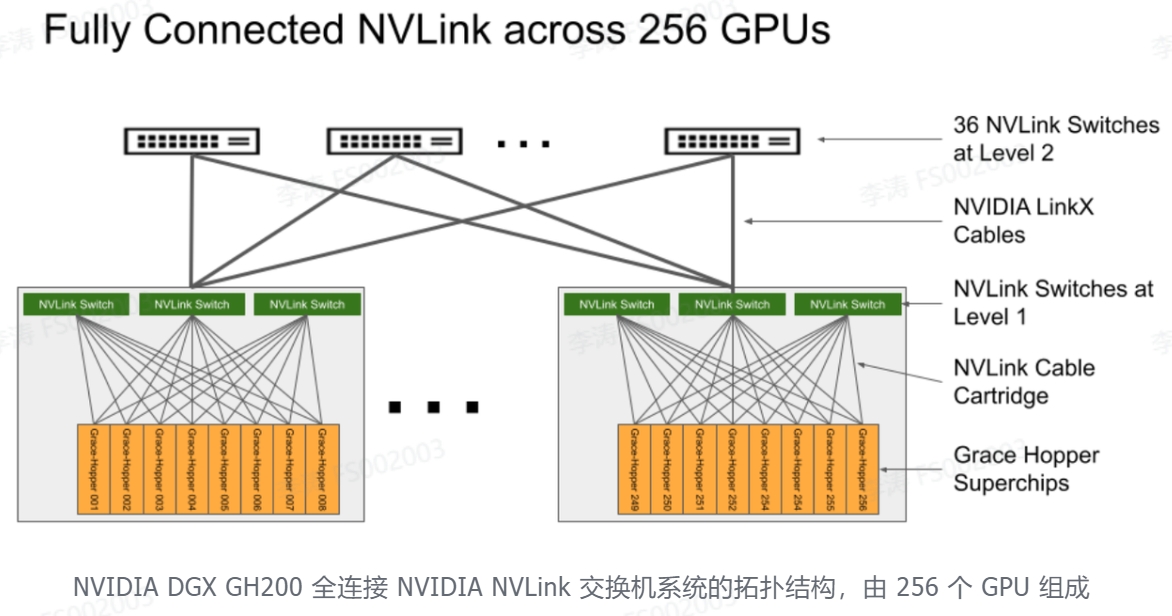
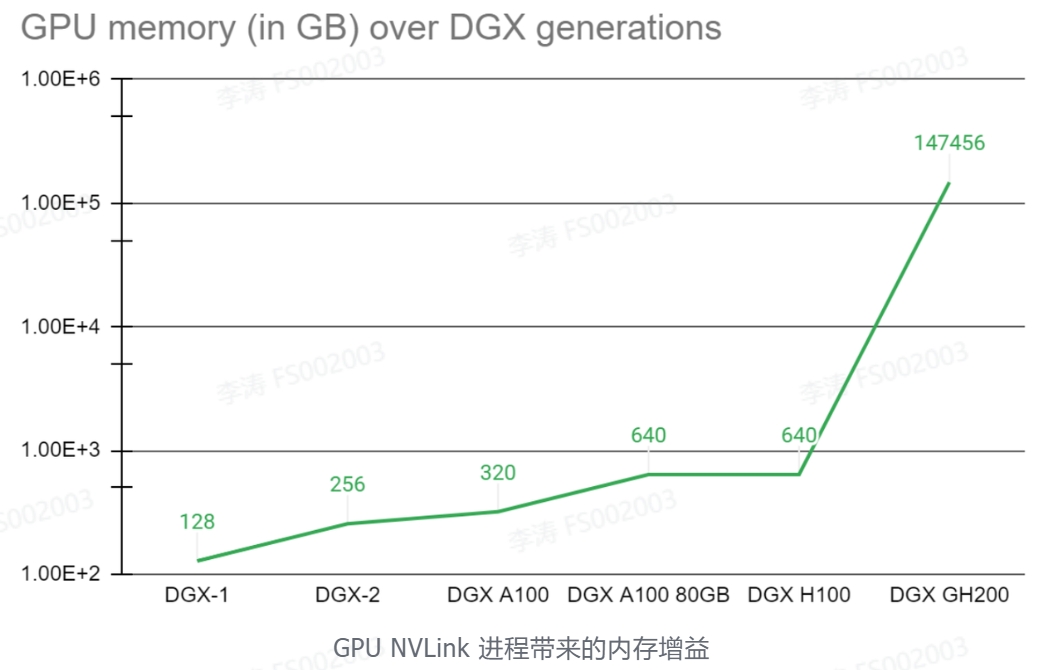
在应用场景上DGX GH200与DGX H100无异,可参考DGX H100应用。但在算力上,DGX GH200却提升了数倍,甚至数百倍。NVIDIA Grace Hopper Superchip 与 NVLink 交换系统,在 NVIDIA DGX GH200 系统中集成多达 256 GPU 。在 DGX GH200 系统中, GPU 共享内存编程模型可以通过 NVLink 高速访问 144 TB 的内存。与单个相比NVIDIA DGX A100 320 GB 系统, NVIDIA DGX GH200 通过 NVLink 为 GPU 共享内存编程模型提供了近 500 倍的内存,形成了一个巨大的数据中心大小的 GPU。NVIDIA DGX GH200 是第一台突破 NVLink 上 GPU 可访问内存 100 TB 障碍的超级计算机。
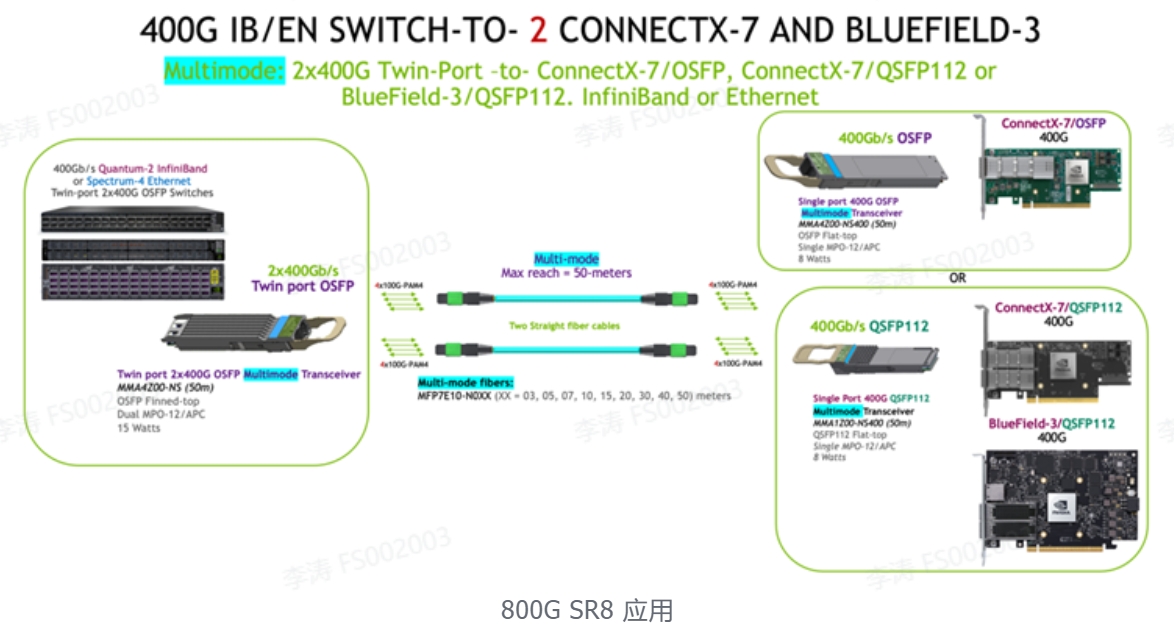
800G产品应用场景
光模块应用场景
1. 800Gb/s 交换机到交换机或到两台 400Gb/s 交换机
可以使用两个双端口 OSFP 光模块和两根直通多模光纤跳线以800G (2x400G) 将两台基于 OSFP 的交换机链接在一起(50米)。此外,两根光缆可以路由到两个不同的交换机,形成两条 400Gb/s 链路。然后可以将额外的双端口OSFP端口路由到更多交换机。

2. 800Gb/s 交换机到2x 400G ConnectX-7 和/或 BlueField-3
使用两根光纤跳线的双端口 OSFP 光模块最多可支持两个适配器和/或 DPU 组合。两条 4 通道光纤跳线中的每一条都可以连接到 OSFP 或 QSFP112 封装的 400G 光模块,最长可达 50 米。单端口 OSFP 和 QSFP112 封装的光电性能和光接口相同,功耗为 8 W。
-仅 ConnectX-7/OSFP 支持单端口 OSFP。
-QSFP112封装光模块可用于ConnectX-7/QSFP112和/或BlueField-3/QSFP112 DPU。
使用 OSFP 或 QSFP112 的 ConnectX-7 和 BlueField-3 的任意组合可同时与双端口 OSFP 光模块链接使用。
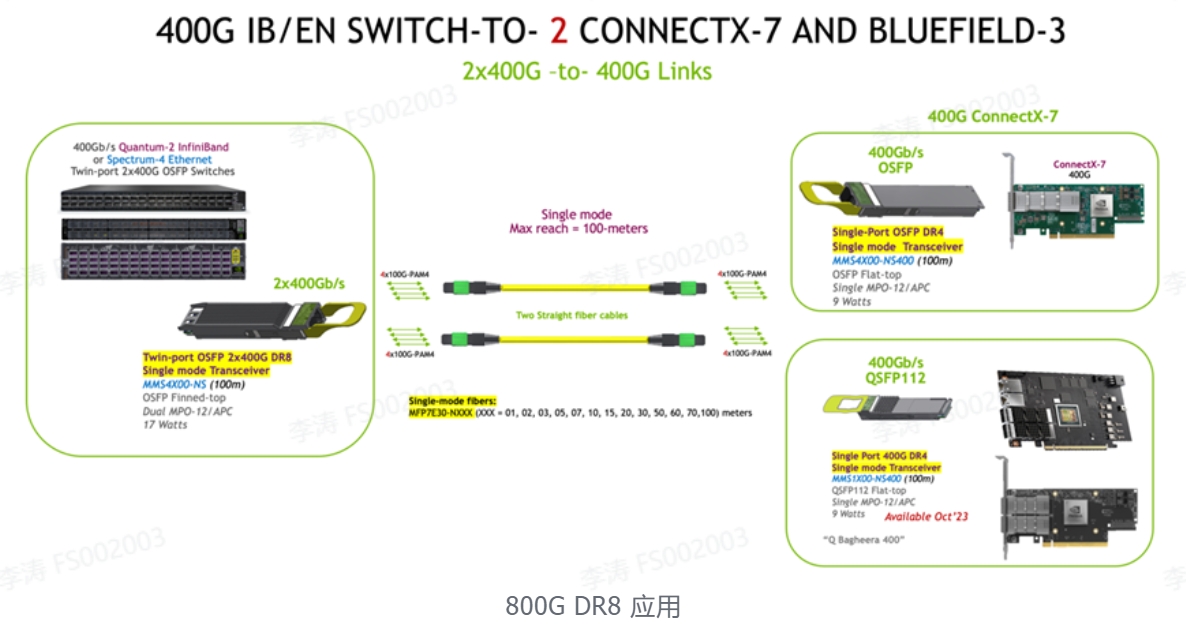
3. 800Gb/s 交换机到4x 200G ConnectX-7 和/或 BlueField-3
使用两根 1:2 分支光纤跳线的双端口 OSFP 光模块最多可支持四个适配器和/或 DPU 组合。两根 4 通道 1:2 分支光纤跳线中的每根都可以连接到 OSFP 或 QSFP112 封装的 400G 光模块,传输距离长达 50 米。单端口 OSFP 和 QSFP112 封装的光学性能和光接口相同。在 400G 光模块中仅激活其中的两个通道,从而实现 200G 应用,并能将 400G 光模块的功耗从 8 W降低到 5.5 W。双端口 OSFP 功耗保持在 15 W。
-仅 ConnectX-7/OSFP 支持单端口 OSFP。
-QSFP112 封装光模块可用于 ConnectX-7/QSFP112 和/或 BlueField-3/QSFP112 DPU。
-ConnectX-7 和 BlueField-3 网卡的任意组合可同时与双端口OSFP 光模块 链接使用。
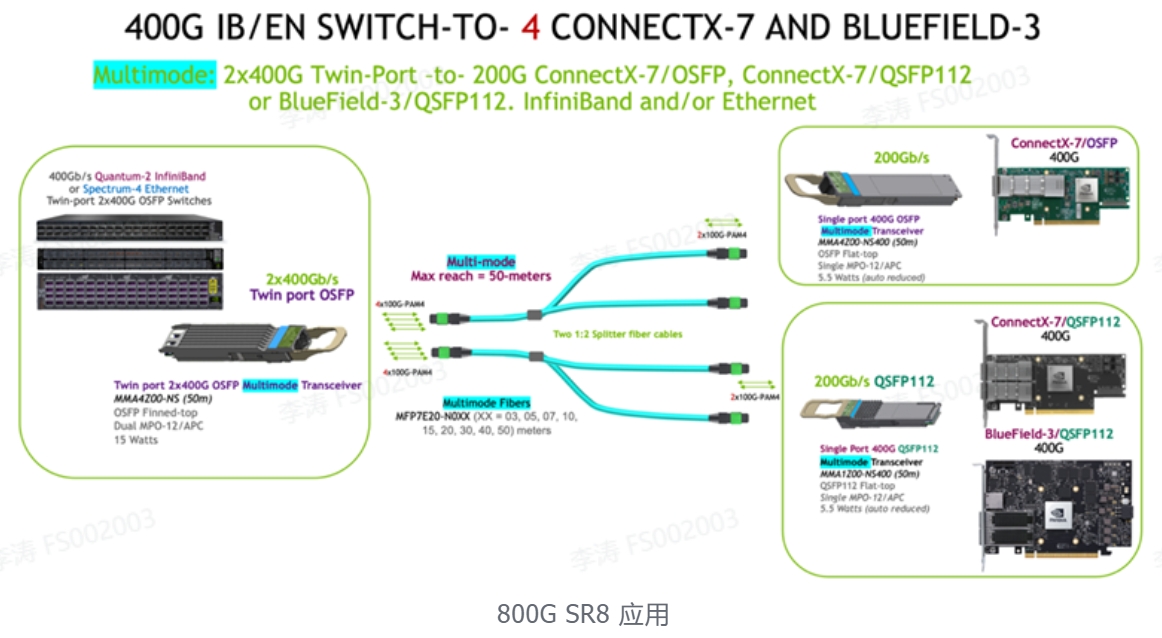
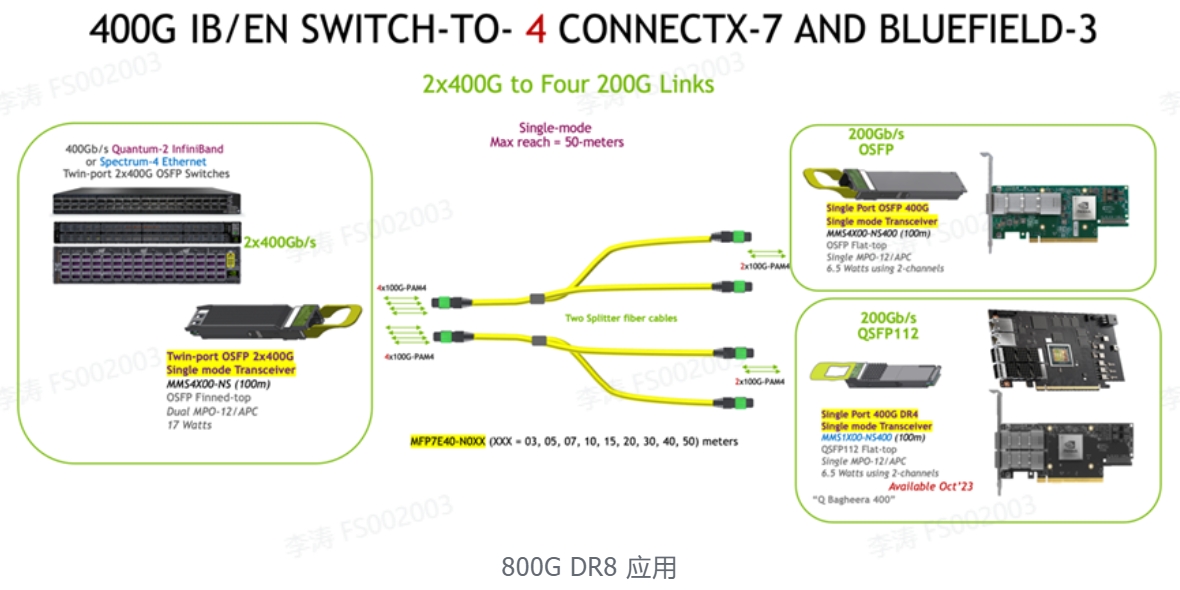
4. 800Gb/s 交换机到 DGX H100 GPU 系统
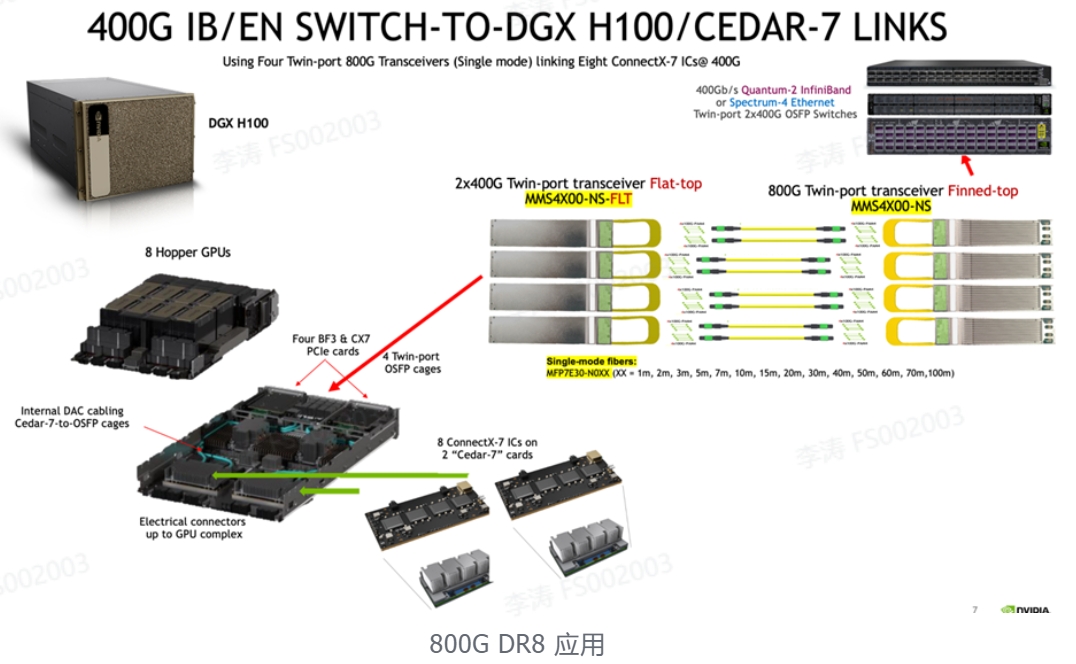
DGX-H100 在顶部机箱部分包含 8 个“Hopper”H100 GPU,在底部服务器部分包含两个 CPU、存储以及 InfiniBand 和/或以太网网络设备。其中包含八个 400Gb/s ConnectX-7 IC,安装在两个称为“Cedar-7”板卡的夹层板上,用于 GPU 到 GPU InfiniBand 或以太网网络。板卡 I/O 在内部路由至四个 800G 双端口 OSFP 机箱,内置散热器安装于前面板上的机箱顶部。这需要在 DGX H100 中使用flat-top transceivers、ACC 和 DAC 线缆。由于交换机中的气流入口减少,400G IB/EN 交换机需要使用finned-top 2x400G 光模块进行额外冷却。
Cedar-7 到交换机的链路可以是单模或多模光纤跳线 或 ACC 有源铜缆,并且采用 InfiniBand 或以太网。
每个双端口 2x400G 光模块提供两条从 DGX 到 Quantum-2 或 Spectrum-4 交换机的 400G ConnectX-7 链路。与 DGX A100 相比,这减少了 ConnectX-7 板卡冗余、复杂性和光模块数量,DGX A100 使用 8 个独立的 HCA 和 8 个光模块或 AOC 线缆以及两个用于 InfiniBand 或以太网存储的附加 ConnectX-6。
此外,对于存储、集群和管理的传统网络,DGX-H100 还支持多达四个 ConnectX-7 和/或两个 BlueField-3 DPU 在 InfiniBand 和/或以太网中用于存储 I/O,以及支持使用 OSFP 或 QSFP112 光模块的 400G 或 200G 设备进行的额外网络。这些 PCIe 卡槽位于OSFP GPU机箱的两侧,并使用单独的电缆和/或光模块。

线缆应用场景
1. 800Gb/s 交换机到交换机或到 DGX H100 GPU 系统
MCP4Y10 的主要用途是将两个双端口、基于 OSFP 的 Quantum-2 InfiniBand 或 Spectrum-4 以太网交换机相互链接在一起,最长可达 2 米,两端均为finned-top连接器。OSFP flat top(在部件号中指定为 -FLT)电缆端可用于液冷交换机和 DGX H100 系统,其中 flat top 用于 DGX H100,flat top 连接器用于 InfiniBand 或以太网交换机 。0.5m 至 2m 采用细 30AWG 线规,方便弯曲。

2. 800Gb/s 交换机到2x和4x 400G ConnectX-7 / QSFP112
单端口 QSFP112 与 ConnectX-7/QSFP112 网络适配器和 BlueField-3/QSFP112 DPU 配合使用。
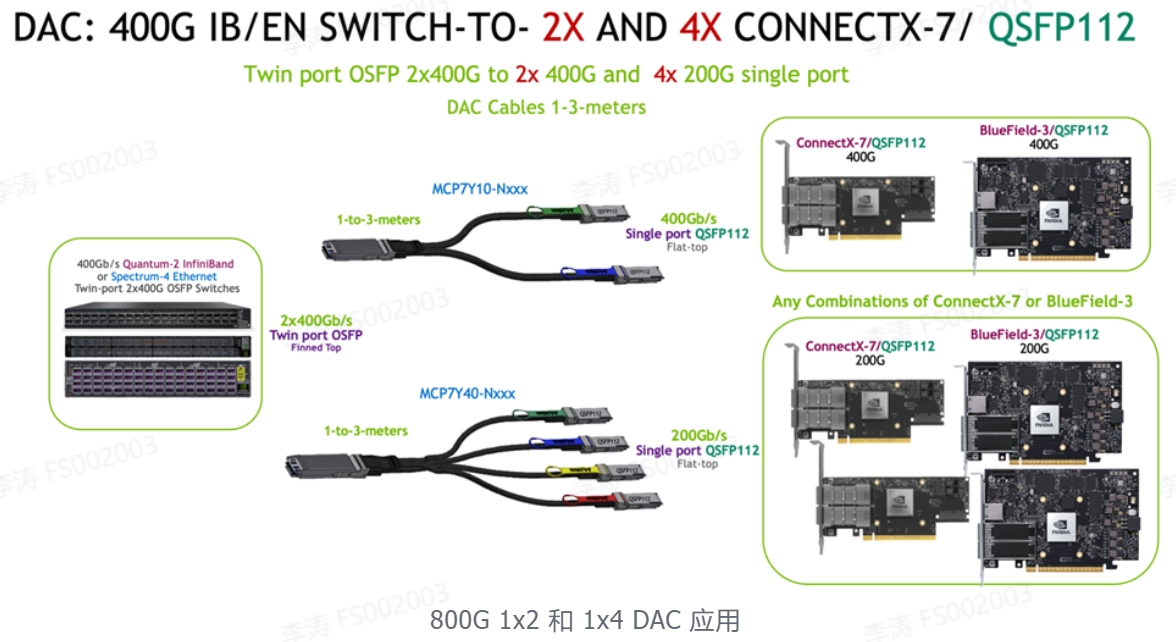
3. 800Gb/s 交换机到2x和4x 400G ConnectX-7 / OSFP
单端口 OSFP 仅与 ConnectX-7/OSFP 网络适配器一起使用。
BlueField-3/QSFP112 DPU 和 ConnectX-7/QSFP112 适配器需要 MCA7J65 和 MCA7J75 上的 QSFP112 端。

演进路线
800G DR8 OSFP 演进路线
路线一:EML路线
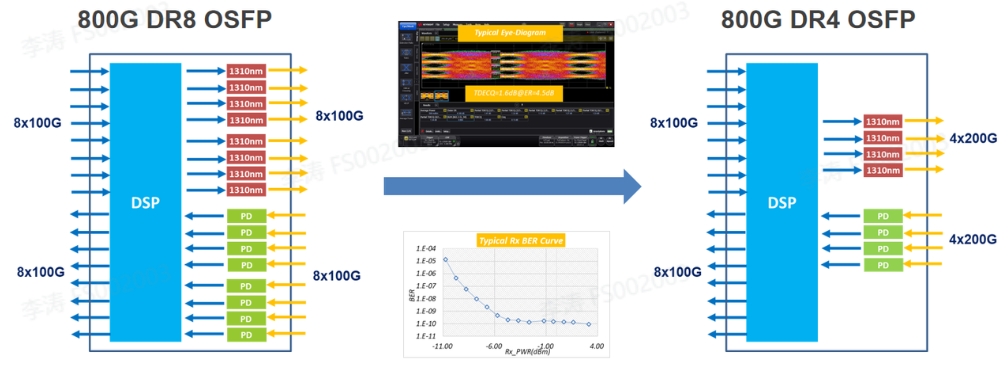
800G DR8 OSFP光模块采用8颗100G EML激光器,激光器数量多,成本高,是目前技术最成熟的一个方案。未来有望实现800G DR4 OSFP,激光器数量减半,成本降低,长期有望接近400G光模块的价格。
路线二:硅光路线
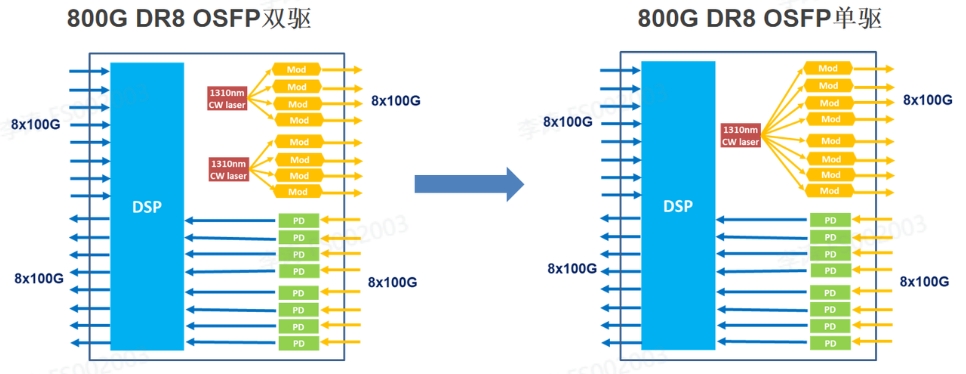
800G硅光目前多采用双激光器驱动方案,复用了当前400G DR4方案。成本上要更低于EML方案。未来会发展为单激光器驱动方案,采用薄膜铌酸锂调制器降低光路损耗,可实现单颗CW激光器驱动8路光信号,目前还处于样品阶段,量产时间未定。硅光单激光器方案预计在2025年可实现量产,届时,800G DR8硅光模块在成本上会进一步降低,但目前主流还是双激光器硅光方案。

800G 2xFR4 OSFP 演进路线
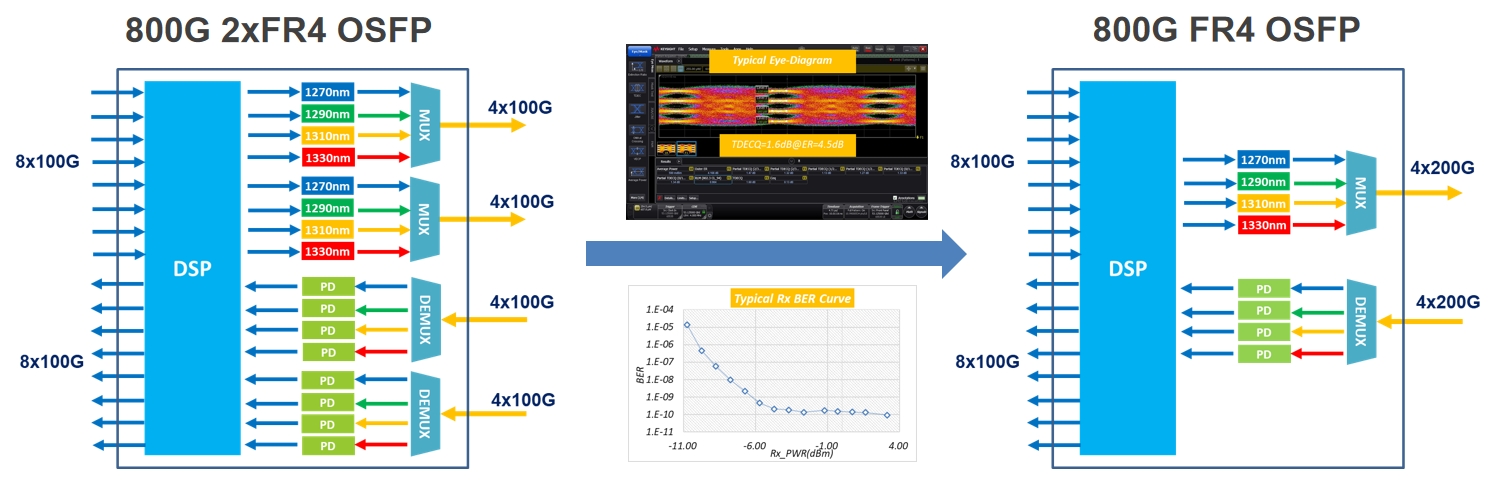
800G 2xFR4采用2套4波CWDM波长的100G EML激光器,每套包含4个激光器,未来会发展为FR4采用4颗CWDM波长200G EML激光器。因为800G FR4需要4个波长CWDM激光器,硅光方案将同样需要采用4个波长的CWDM激光器,因此硅光方案不具备成本优势,主流为EML方案,暂时没有厂商研究硅光方案。
800G SR8 OSFP 演进路线

800G SR8采用8颗VCSEL激光器,传输距离为50m(OM3),由于距离端,应用场景较400G SR8受到更多限制。通过10G、25G、50G、100G SR光模块的传输距离对比,我们可以看到VCSEL激光器单通速率越高,它的传输距离几乎是对半减少的。随着光模块单通道速率越来越高,VCSEL进入到了瓶颈期。预计到1.6T光模块时代时,若1.6T光模块采用VCSEL激光器,距离还会进一步缩短,对于客户选择来说,1.6T的线缆方案在成本上会是一个更优选,所以预计未来VCSEL激光器会退出1.6T光模块市场。
从CPO到LPO
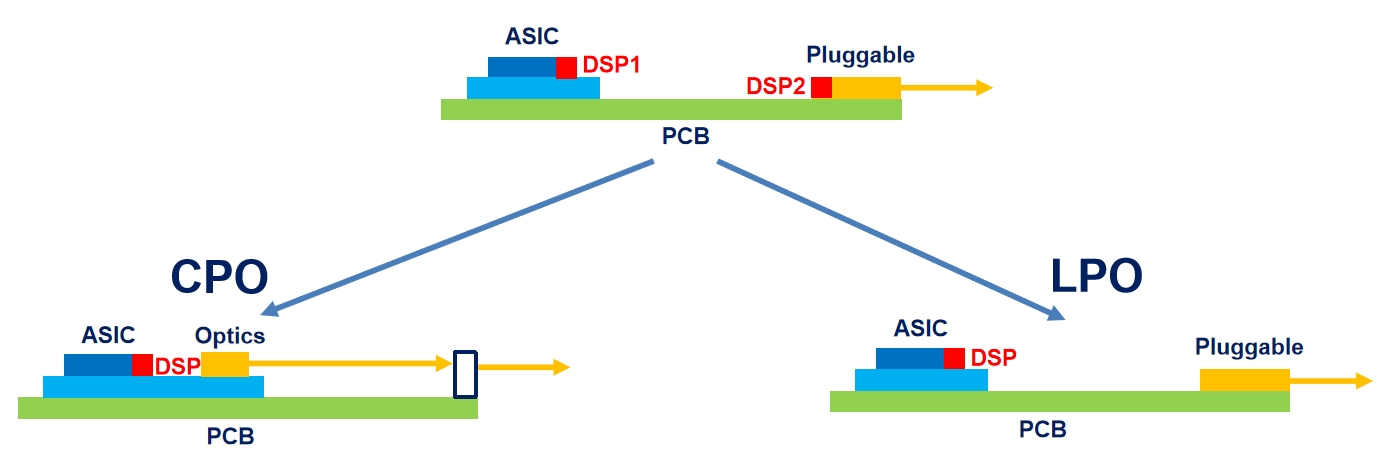
CPO
相较于传统方案,通过上图可以看到,CPO方案减少了一颗DSP芯片,在功耗和成本上进一步降低。同时,CPO方案采用了光电共封装的形式,直接将交换芯片(实现光电转换功能的)封装到了光模块上,减少了交换机到光模块的电信号损耗,从而降低了时延和整体功耗。
由于光电共封装的原因,问题也因此产生了,由于要把交换机芯片封装到光模块上,那么这个封装由光模块还是交换机厂商来封装就成了问题,同时,如果坏了一个光电芯片组,怎么维修,谁来维修等,在技术上存在很多问题。因此,真正大规模量产应用至少3年以后,甚至可能长期在一个概念的状态。
LPO
作为传统方案的替代方案,LPO方案一经推出就收获了广泛关注。LPO方案采用LPO线性直驱的技术把DSP替换掉,使用高线性度、具备EQ功能的TIA和DRIVER芯片,功耗大幅降低。但是延迟提升,系统误码率和传输距离有所牺牲。因此,LPO暂时用于特定领域(短距离),但未来可能会用于500m以内,满足数据中心最大的需求。
LPO技术高度依赖交换机芯片性能的开放和提升,如T51.2T的Tomahawk 5在信号恢复方面的功能提升。整体上来讲,LPO作为光模块的一个封装形式,是可插拔光模块向下演进的技术路线,相较于CPO方案更容易实现、确定性更强。
总结
1.EML激光器方案将是800G光模块未来两年的主流方案,EML需求将会大幅增加。
2.硅光方案相比EML方案更具成本优势,但批量生产还面临一些挑战,长期可靠性还需要进一步验证。
3.下一代4X200G的800G光模块将会带来更大的成本优势,长期成本有望接近400G光模块。
4.LPO光模块具有功耗和成本优势,给用户带来价值,但面临诸多技术挑战,还需要一段时间进行沉淀。
飞速(FS)800G光模块产品规划
为更好的顺应行业发展趋势、满足用户增长的需求,飞速(FS)致力于在800G光模块领域长期发展,为此定制800G光模块产品未来规划。当前已有QSFP-DD光模块、OSFP光模块、QSFP-DD高速线缆、OSFP高速线缆等相关系列产品在售,后续也将通过研发及技术引入,进一步提升产品性能,扩展产品类型,构建完整的产品体系。
在产品规划和管理中,飞速(FS)将充分听取客户反馈并结合市场需求,持续进行研发和测试,为客户提供高性能、低功耗的800G光模块解决方案,推动数据通信技术的进一步发展。