文生图模型之SDXL - 知乎之前的文章 文生图模型之Stable Diffusion已经介绍了比较火的文生图模型Stable Diffusion,近期Stability AI又发布了新的升级版本SDXL。目前SDXL的代码、模型以及技术报告已经全部开源:官方代码:https://github.…![]() https://zhuanlan.zhihu.com/p/642496862GitHub - Stability-AI/generative-models: Generative Models by Stability AIGenerative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub.
https://zhuanlan.zhihu.com/p/642496862GitHub - Stability-AI/generative-models: Generative Models by Stability AIGenerative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub. https://github.com/Stability-AI/generative-models训练和模型权重都开源了,看了sdxl,平时在做项目时,觉得模型效果不好就加数据时,其实也不一定是好路子,更好的方式应该是分析数据的利用方式以及其中存在的问题作进一步细化的改进。上述的材料作者分析的非常好,看完之后非常清晰。目前sdxl在stable_diffusion_webui的1.5版本也可以尝试,除此之外在diffusers中已经集成了。
https://github.com/Stability-AI/generative-models训练和模型权重都开源了,看了sdxl,平时在做项目时,觉得模型效果不好就加数据时,其实也不一定是好路子,更好的方式应该是分析数据的利用方式以及其中存在的问题作进一步细化的改进。上述的材料作者分析的非常好,看完之后非常清晰。目前sdxl在stable_diffusion_webui的1.5版本也可以尝试,除此之外在diffusers中已经集成了。
1.introduction
3大改进点:1.sdxl的模型参数量增大为2.3B,采用了2个clip text encoder提取文本特征;2.sdxl采用了额外的条件注入来改善训练中的数据处理问题,采用了多尺度的微调;3.sdxl级联了一个细化模型来提升图像的质量(细化模型也可以单独使用,增强细节)。
2.Improving stable diffusion
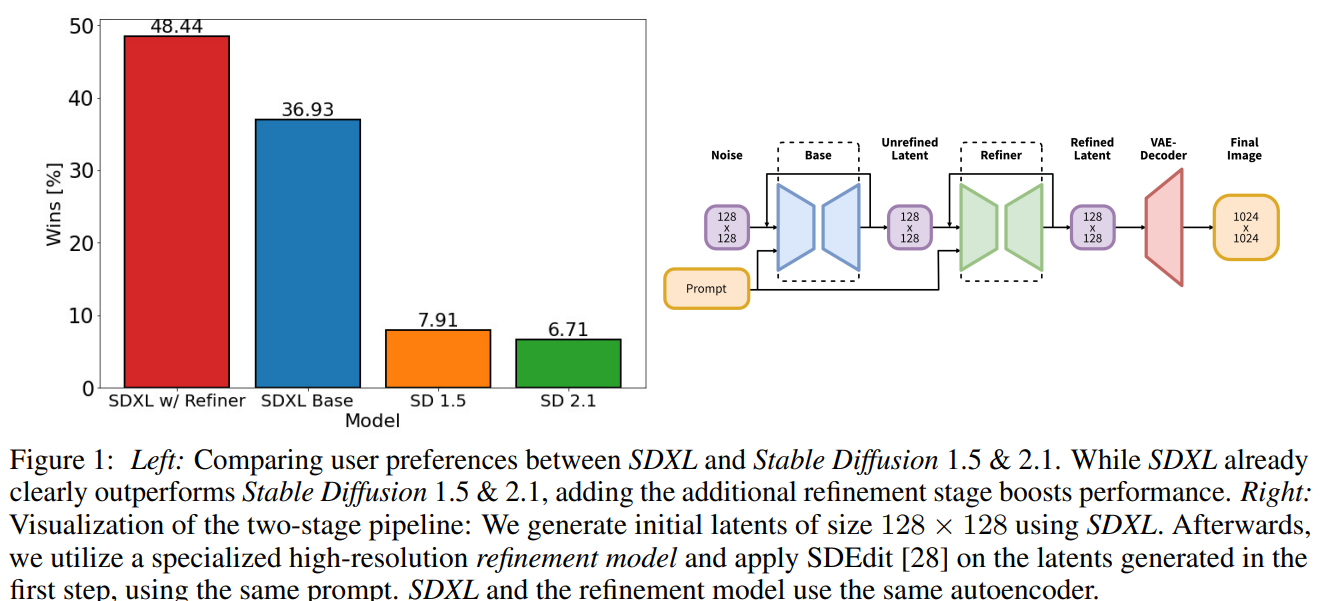
第一张图是人工评分的,sdxl遥遥领先。
2.1 architecture & scale
sdxl采用了更大版本的unet,2.6B相比较之前的版本,大了3倍。



结合上面两张图来解释一下表格中的transformer blocks和channel mult,第一张图是sdxl的unet结构图,第2张是sd中的unet,其中sdxl中第一个stage是普通的downblock2d,而不是采用了crossattndownblock2d,因为sdxl最终是直接生成1024x1024的图,对应的latent为128x128x4,如果第一个stage就是用了attention(包括self-attention),显存和计算量都是很大的,另外sdxl只有3个stage,在表中可以看到sdxl的list有3个值,sd有4个值对应4个模块,3个stage意味着只进行了2次2x下采样,而之前的sd用了4个stage,包含3个2x下采样;sdxl的网络宽度特征通道数相比之前没有变化,3个stage分别是320,640,1280。sdxl主要的参数增加来源于使用了更多的transformer blocks,在sd中每个包括attnetion的block只使用一个transformer block(self-attention->cross-attention->ffn),但在sdxl中的stage 2和stage 3的2个crossattndownblock2d模块中的transformer block分别是2和10,并且中间的midblock2dcrossattn的transformer block也是10,和最后一个stage保持一致,这里对应表中的第2行,sdxl是0,2,10,sd则都是1,第3行1,2,4是320的倍数。
sdxl的另一个变动是text encoder,sd 1.x采用的是text encoder是123m的openai clip vit-l/14,sd 2.x将text encoder升级为354m的openclip vit-h/14(openclip是laion出的),sdxl采用了参数量694m的openclip vit-bigG和openai clip vit-l/14,这里分别提取2个text encoder的倒数第二层特征,其中openclip vit-bigG特征维度是1280,clip vit-l/14的特征维度是768,concat之后是2048维,这是sdxl的context dim。

经过上述调整,sdxl的unet总参数量是2.6b,sdxl的unet变了,但是扩散模型的设置和原来的sd一样,都采用了1000步的ddpm,noise scheduler也保持不变。
2.2 micro-conditioning
sdxl的第2个优化点是采用了额外的条件注入来解决训练过程中的数据处理问题,包括了数据利用效率和图像裁剪问题。
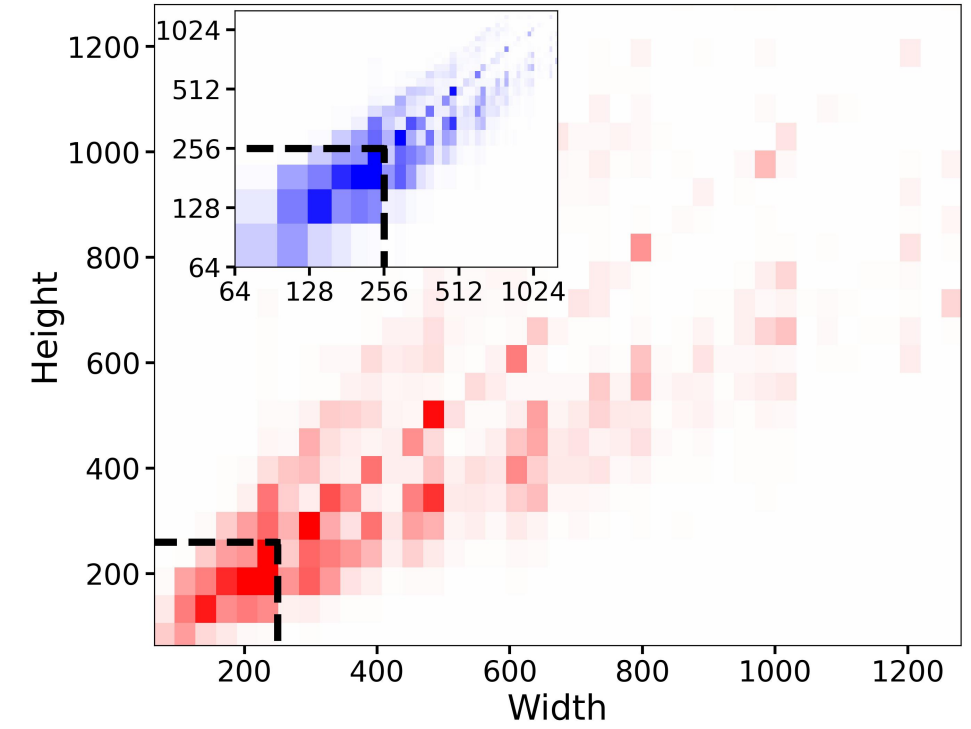
第一个问题,sd的训练往往是现在256x256上预训练,然后再在512x512上继续训练,当使用256x256时就要过滤掉那些宽度和高度小于256的图像,在512x512尺寸训练时也只能使用512x512以上的图像,由于需要过滤数据,这就导致真正训练的数据样本减少了,如上图,过滤掉小于256的图,占比达到了39%。一个直接的解决方法是先对原始数据进行超分,但是超分有时候也会出现问题(一般原始图片不清晰时,我们也对训练数据做图像修复),sdxl将原始尺寸width和height作为条件嵌入unet中,这相当于让模型学到了图像分辨率参数,在训练过程中,可以不过滤数据直接resize图像,在推理时,只需要输入目标分辨率来保证生成的图像质量,图像原始尺寸嵌入和timesteps的嵌入一样,现将width和height用傅里叶特征编码进行编码,然后将特征concat在一起加载time embedding上。下图中当得到512x512模型时,当输入低分辨率时图像比较模糊,高分辨率时图像质量提升。

第二个问题,在训练过程中的图像裁剪问题,目前文生图模型预训练时往往采用固定图像尺寸,需要对原始图像进行预处理,一般是将图像的最短边resize到目标尺寸,然后沿着图像的最长边进行裁剪(random crop或者center crop),但是图像裁剪往往会导致图像出来缺失。

sdxl将训练过程中裁剪的左上顶点坐标作为的条件注入到unet中,通过傅里叶编码加到time embedding上,在推理时只需要将坐标设为0,0就可以得到居中的图像,很好理解,训练时,图像裁剪了的左上角坐标信息,模型学到了,这是不完整的图。

在sdxl训练中,可以将两种条件注入一起使用,只要额外保存原始的width/height以及图像crop时的左上角坐标, sdxl基于这种条件注入在256x256尺寸上训练600000步(bs=2048),然后采用512x512尺寸继续训练200000步,相当于采样了约16亿样本,最后在1024x1024上采用多尺度微调。
2.3 multi-aspect traininng
经过预训练之后,sdxl采用多尺度进行微调,采用了novelAI的方案,将数据集中图像按照不同长宽比划分到不同的buckets,在训练过程中,每个steps可以在不同的bucket中切换,每个batch的数据都是从相同的bucket中采样得到的,此外sdxl也将bucket size即target size作为条件注入到unet中,和之前一样。
2.4 improved autoencoder
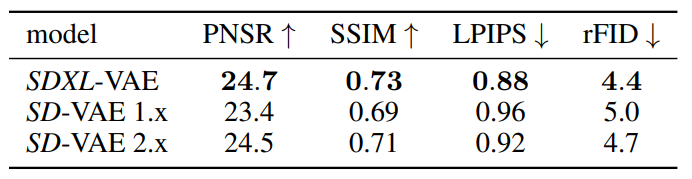
sdxl和sd一样也是基于latent diffusion架构,对于latent diffusion架构,首先要采用一个autoencoder模型来将图像压缩为latent,然后扩散模型用来生成latent,生成的latent可以通过autoencoder的decoder来重建图像,注意不是在pixel空间做的,实在latent空间做的。sdxl的autoencoder采用的kl,并不是vq,基于同样的架构用了更大bs(256vs9)重新训练,下表中的vae模型结构都是相同的,但是sd-vae 2.x只是在sd-vae 1.x基础上微调了decoder部分,encoder部分是相同的,所以两者的latent分布是一致的,可以通用。但是sdxl是重新训练的,它的latent分布发生了变化,不能混用。将latent送入到扩散模型之前,要对latent进行缩放来使得latent的标准差尽量为1,由于权重发生了变化,所以sdxl的缩放系数和sd不同,sd是0.18215,sdxl是0.13025,此外sdxl-vae推理时用float16会溢出,用float32推理,在webui中选择--no-half-vae。
2.5 putting everything together
sdxl还有一个细化阶段,第一个模型胶sdxl base model,第二个模型是refiner model,在base model基础上继续提升图像的细节,refiner model和base model共用相同的vae,只是refiner model只在较低的noise level上训练(前200个timesteps),在推理时只使用refiner model的图生图能力。refiner model和base model在结构上有一定的不同,其UNet的结构如下图所示,refiner model采用4个stage,第一个stage也是采用没有attention的DownBlock2D,网络的特征维度采用384,而base model是320。另外,refiner model的attention模块中transformer block数量均设置为4。refiner model的参数量为2.3B,略小于base model。

另外refiner model的text encoder只使用了OpenCLIP ViT-bigG,也是提取倒数第二层特征以及pooled text embed。与base model一样,refiner model也使用了size and crop conditioning,除此之外还增加了图像的艺术评分aesthetic-score作为条件,处理方式和之前一样。refiner model应该没有采用多尺度微调,所以没有引入target size作为条件(refiner model只是用来图生图,它可以直接适应各种尺度)。

3.future work
人手生成结构还不好;灯光和纹理偏离事实;当生成图像包括多个实体时,属性混淆,属性渗透或者溢出。
single stage:单阶段模型;
text synthesis:使用更好的text encoder,imgen中也说了text encoder很重要;
architecture:使用了一些纯transformer的架构,比如dit,没啥效果;
distillation:减少采样步数;
diffusion model:采用更好的扩散架构