- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第P2周:彩色识别
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 包引用
- 硬件设备
- 数据准备
- 数据集下载与加载
- 数据集预览
- 数据集准备
- 模型设计
- 模型训练
- 超参数设置
- helper函数
- 正式训练
- 结果呈现
- 总结与心得体会
上周使用Pytorch构建卷积神经网络,实现了MNIST手写数字的识别,这周的目标是CIFAR10中复杂的彩色图像分类。
环境
- 系统:Linux
- 语言: Python 3.8.10
- 深度学习框架:PyTorch 2.0.0+cu118
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transformsimport numpy as np
import matplotlib.pyplot as plt
from torchinfo import summary # 方便像tensorflow一样打印模型
硬件设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
数据集下载与加载
train_dataset = datasets.CIFAR10(root='data', train=True, download=True, transform=transforms.ToTensor()) # 不要忘记这个transform
test_dataset = datasets.CIFAR10(root='data', train=False, download=True, transform=transforms.ToTensor())
数据集预览
image, label = train_dataset[0]
print(image.shape)
plt.figure(figsize=(20,4))
for i in range(20):image, label = train_dataset[i]plt.subplot(2, 10, i+1)plt.imshow(image.numpy().transpose(1,2,0)plt.axis('off')plt.title(label) # 加载的数据集没有对应的名称,暂时展示它们的id

数据集准备
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
class Model(nn.Module):def __init__(self, num_classes):super().__init__()# 3x3的卷积无padding每次宽高-2# 2x2的最大池化,每次宽高缩短为原来的一半# 32x32 -> conv1 -> 30x30 -> maxpool -> 15x15self.conv1 = nn.Conv2d(3, 64, kernel_size=3)# 15x15 -> conv2 -> 13x13 -> maxpool -> 6x6self.conv2 = nn.Conv2d(64, 64, kernel_size=3)# 6x6 -> conv3 -> 4x4 -> maxpool -> 2x2self.conv3 = nn.Conv2d(64, 128, kernel_size=3)self.maxpool = nn.MaxPool2d(2),self.flatten = nn.Flatten(),self.fc1 = nn.Linear(2*2*128, 256)self.fc2 = nn.Linear(256, num_classes)def forward(self, x):x = F.relu(self.conv1(x))x = self.maxpool(x)x = F.relu(self.conv2(x))x = self.maxpool(x)x = F.relu(self.conv3(x))x = self.maxpool(x)x = self.flatten(x)x = F.relu(self.fc1(x))x = self.fc2(x)return xmodel = Model(10).to(device)
summary(model, input_size=(1, 3, 32, 32))
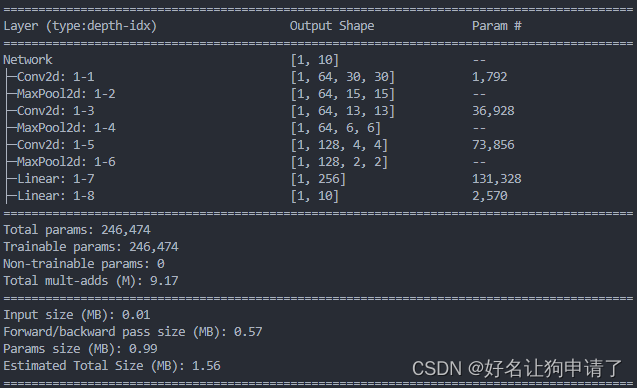
模型训练
超参数设置
learning_rate = 1e-2
epochs = 10
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
helper函数
def train(train_loader, model, loss_fn, optimizer):size = len(train_loader.dataset)num_batches = len(train_loader)train_loss, train_acc = 0, 0for x, y in train_loader:x, y = x.to(device), y.to(device)preds = model(x)loss = loss_fn(preds, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (preds.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= sizereturn train_loss, train_accdef test(test_loader, model, loss_fn):size = len(test_loader.dataset)num_batches = len(test_loader)test_loss, test_acc = 0, 0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)preds = model(x)loss = loss_fn(preds, y)test_loss += loss.item()test_acc += (preds.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizereturn test_loss, test_accdef fit(train_loader, test_loader, model, loss_fn, optimizer, epochs):train_loss, train_acc = [], []test_loss, test_acc = [], []for epoch in range(epochs):model.train()epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)model.eval()epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)return train_loss, train_acc, test_loss, test_acc
正式训练
train_loss, train_acc, test_loss, test_acc = fit(train_loader, test_loader, model, loss_fn, optimizer, 20)
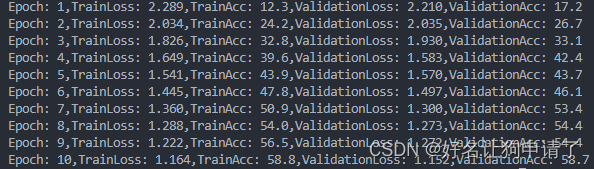
结果呈现
series = range(len(train_loss))
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(series, train_loss, label='train loss')
plt.plot(series, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(1,2,2)
plt.plot(series, train_acc, label='train accuracy')
plt.plot(series, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
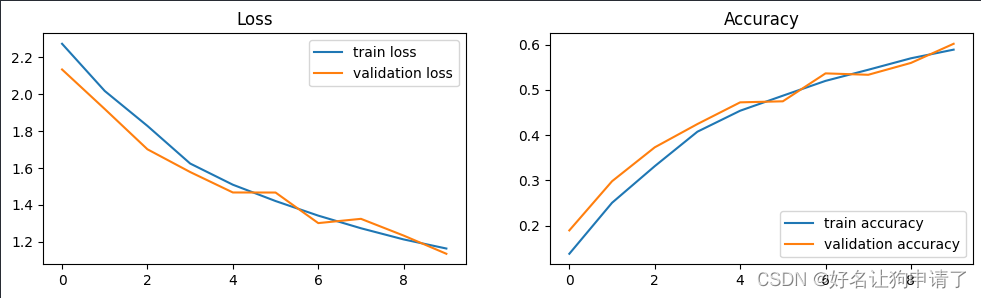
从结果图可以发现,模型应该还没收敛,将epoch设置为30,重新跑一遍模型。

可以看出20个epoch后,训练集上的正确率持续增长,在验证集上的正确率几乎就不再增长了,符合过拟合的特征。需要对模型进行改进才能提升正确率了。
总结与心得体会
通过本周的学习,掌握了使用pytorch编写一个完整深度学习的过程,包括环境的配置、数据的准备、模型定义与训练、结果分析呈现等步骤,并且掌握了通过pytorch的API组建一个简单的卷积神经网络的过程。