计算能力换算
理论峰值 = GPU芯片数量GPU Boost主频核心数量*单个时钟周期内能处理的浮点计算次数
只不过在GPU里单精度和双精度的浮点计算能力需要分开计算,以最新的Tesla P100为例:
双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop
TFLOPS
FLOPS是Floating-point Operations Per Second的缩写,代表每秒所执行的浮点运算次数。现在衡量计算能力的标准是TFLOPS(每秒万亿次浮点运算)
NVIDIA显卡算力表:https://developer.nvidia.com/cuda-gpus#compute
但是现在衡量计算速度的标准是TFLOPS**(每秒万亿次浮点运算),注意GPU它是浮点运算。
重点就是关注它的flops是怎么计算的。
GPU设备的单精度计算能力的理论峰值计算公式:
单精度计算能力的峰值 = 单核单周期计算次数 × 处理核个数 × 主频
例如: 以GTX680为例, 单核一个时钟周期单精度计算次数为两次,处理核个数 为1536, 主频为1006MHZ,那他的计算能力的峰值P 为:
P = 2 × 1536 × 1006MHZ = 3.09TFLOPS
这里1MHZ = 1000000HZ, 1T为1兆,也就是说,GTX680每秒可以进行超过3兆次的单精度运算。
各种FLOPS的含义
MFLOPS (megaFLOPS):每秒一百万 (=10^6) 次的浮点运算
GFLOPS (gigaFLOPS) :每秒十亿 (=10^9) 次的浮点运算
TFLOPS (teraFLOPS) :每秒一万亿 (=10^12) 次的浮点运算
PFLOPS (petaFLOPS) :每秒一千万亿 (=10^15) 次的浮点运算
补充:
算力单位
TOPS(Tera Operations Per Second:)1TOPS处理器每秒钟可进行一万亿次(10^12)操作。
GOPS(Giga Operations Per Second):1GOPS处理器每秒钟可进行一亿次(10^9)操作。
MOPS(Million Operation Per Second):1MOPS处理器每秒钟可进行一百万次(10^6)操作。
在某些情况下,还使用 TOPS/W 来作为评价处理器运算能力的一个性能指标,TOPS/W 用于度量在1W功耗的情况下,处理器能进行多少万亿次操作。
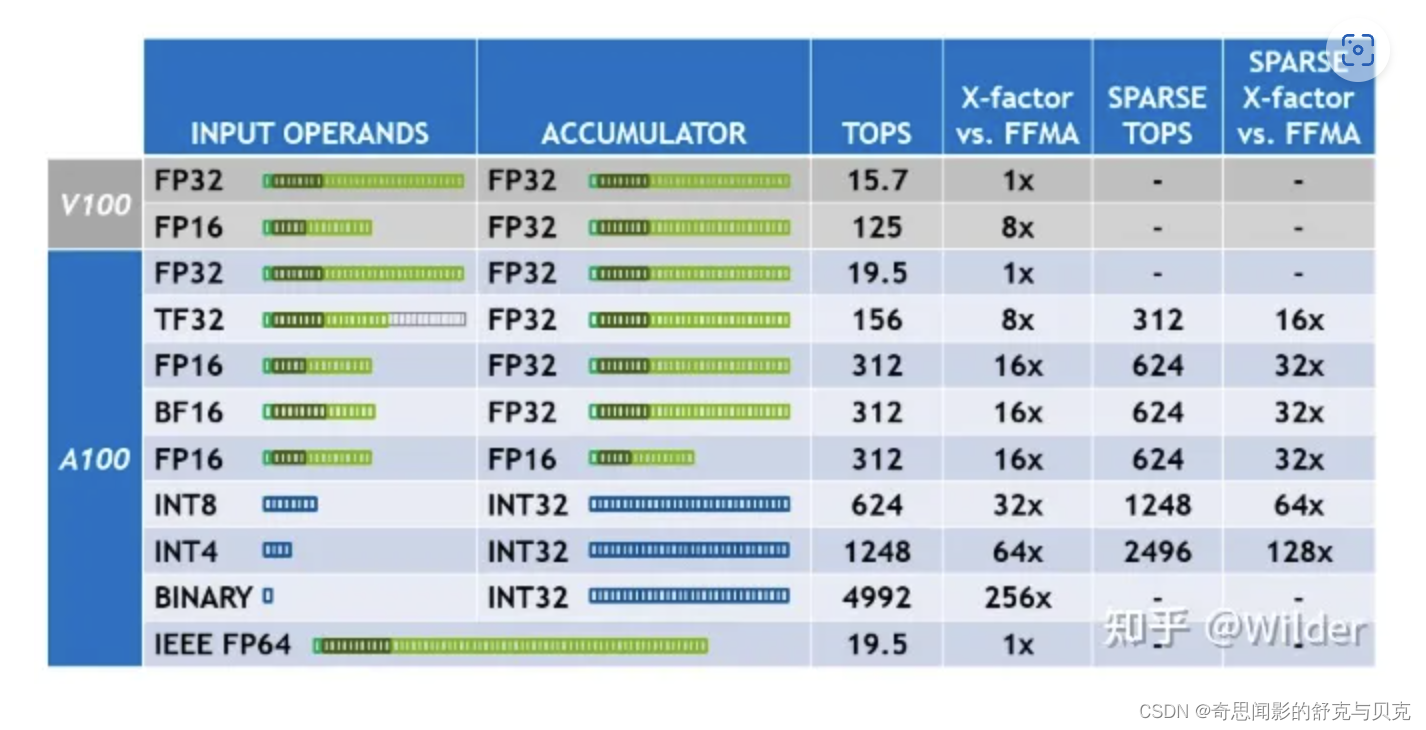
FP32 = float32 单精度浮点格式
IEEE 754-2008 标准指定了额外的浮点类型,例如 64 位 base-2双精度,以及最近的 base-10 表示。
TF32 = TensorFlow-32 英伟达提出的代替FP32的单精度浮点格式
NVIDIA A100/Ampere安培架构 GPU 中的新数据类型,TF32 使用与半精度 (FP16) 数学相同的 10 位尾数,表明对于 AI 工作负载的精度要求有足够的余量。并且TF32采用与FP32相同的8位指数,因此可以支持相同的数值范围。
TF32 在性能、范围和精度上实现了平衡。
TF32 采用了与半精度( FP16 )数学相同的10 位尾数位精度,这样的精度水平远高于AI 工作负载的精度要求,有足够的余量。同时, TF32 采用了与FP32 相同的8 位指数位,能够支持与其相同的数字范围。
这样的组合使TF32 成为了代替FP32 ,进行单精度数学计算的绝佳替代品,尤其是用于大量的乘积累加计算,其是深度学习和许多HPC 应用的核心。
借助于NVIDIA 函示库,用户无需修改代码,即可使其应用程式充分发挥TF32 的各种优势。TF32 Tensor Core 根据FP32 的输入进行计算,并生成FP32 格式的结果。目前,其他非矩阵计算仍然使用FP32 。
为获得最佳性能, A100 还具有经过增强的16 位数学功能。它以两倍于TF32 的速度支持FP16 和Bfloat16 ( BF16 )。利用自动混合精度,用户只需几行代码就可以将性能再提高2 倍。
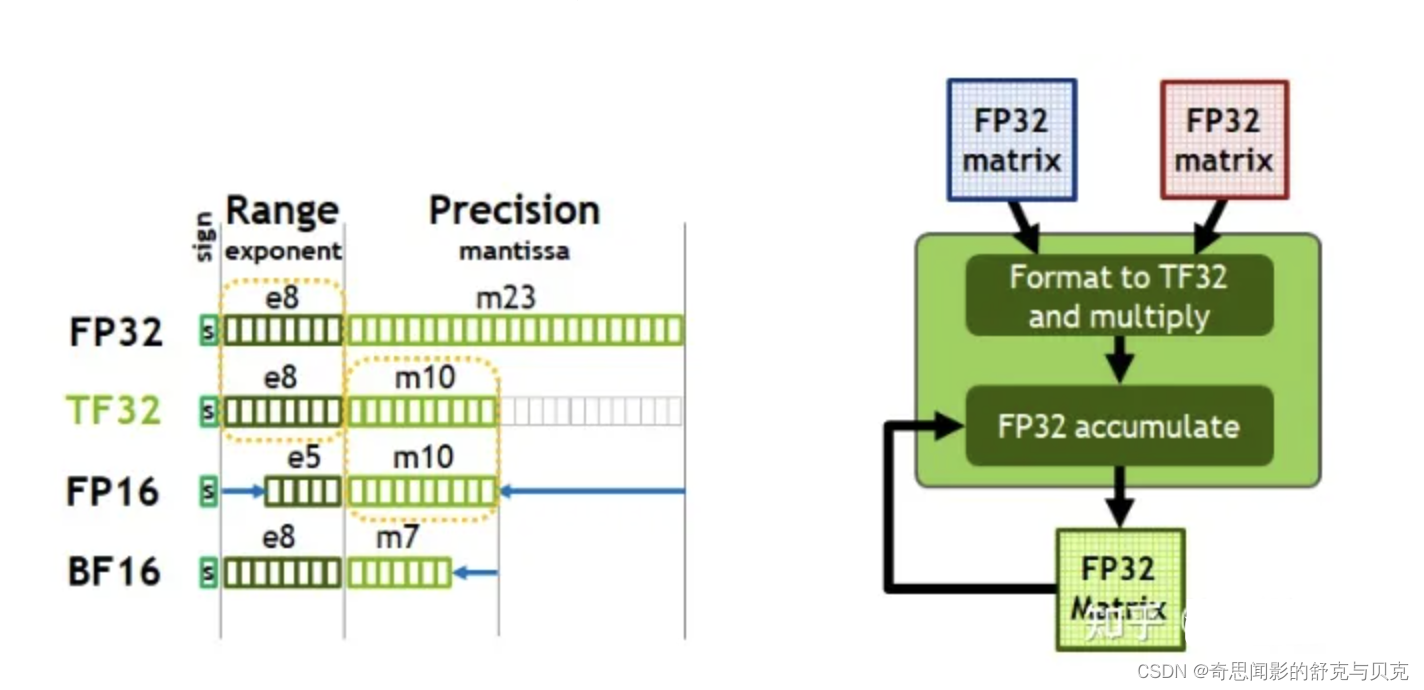
所以通过降低精度让TF32新单精度数据类型代替了FP32原有的单精度数据类型,从而减少了数据所占空间大小在同样的硬件条件下可以更多更快地运行。
算力单位概述 - 知乎 (zhihu.com)
GPU运算能力对(2022.4.5更新)_gpu算力换算_敢敢のwings的博客-CSDN博客