一、说明
二、无模型算法
RL 算法可分为基于模型的算法和无模型算法。在无模型RL中,我们不知道也不想学习系统动力学
![]()
或者,我们只是不在乎,因为该方法不需要状态转换的知识。我们对行动进行抽样并观察相应的奖励,以优化政策或拟合价值函数。
无模型 RL 分为策略优化或价值学习:

以下是每个类别中的一些高级说明:
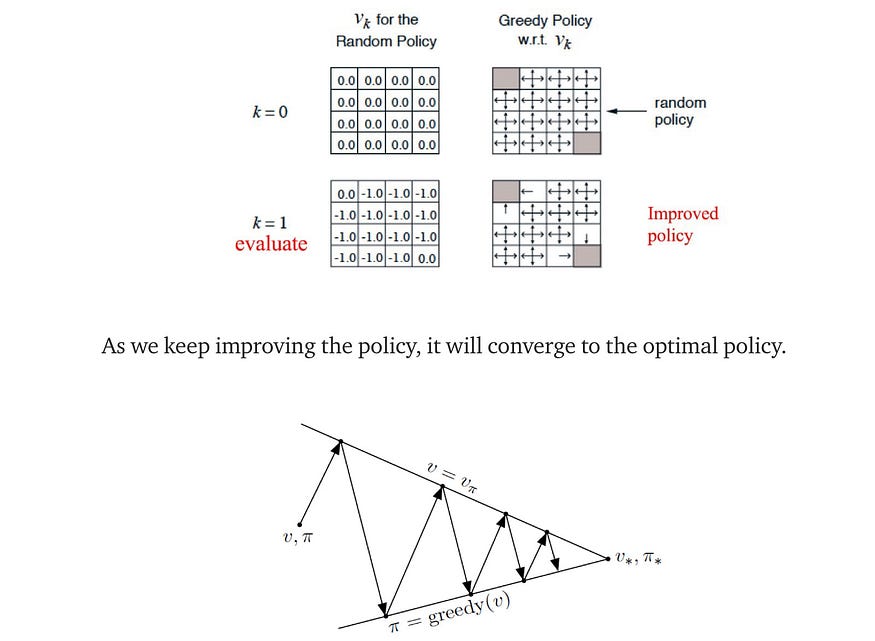
- 值迭代 — 值迭代使用动态规划以迭代方式计算值函数。
![]()

从源代码修改
- 策略迭代 — 我们计算价值函数,并在替代步骤中优化策略。
源
- 价值学习/Q-学习(例如DQN,Q学习,TD,拟合值迭代)- 如果没有明确的策略,我们将价值函数或Q值函数迭代拟合,与非策略采取的行动下观察到的奖励,例如ε贪婪策略,它根据Q值函数选择操作,有时选择随机操作进行探索。
- 策略梯度(例如 REINREINFORCEMENT、TRPO、PPO) — 我们使用奖励的梯度上升来优化策略,w.r.t. 策略参数 θ。直观地说,它逐渐改进了政策,使特定状态下的高回报行动更有可能。
![]()
- 参与者-批评者(例如 A3C、SAC)—策略梯度方法中的梯度可以由参与者来决定采取什么操作,批评者来估计值或 Q 函数。参与者-批评者方法主要是一种政策梯度方法,其优势函数由观察到的奖励和批评者网络计算。在这种方法中,我们迭代拟合批评者(值函数或Q函数)和参与者。
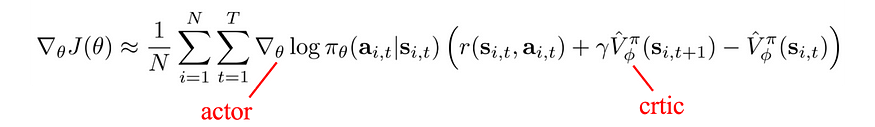
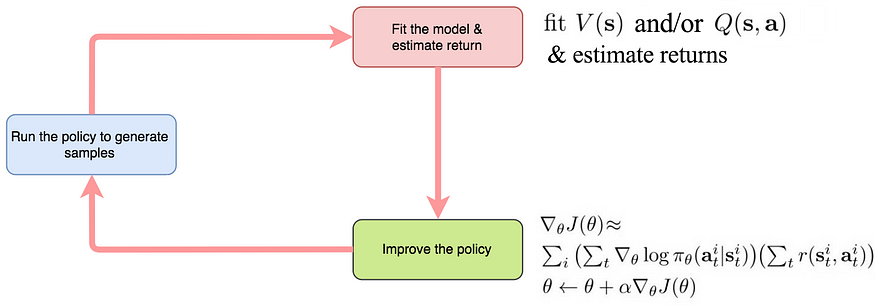
- 进化 — 我们从随机策略开始。我们采取行动并观察奖励。我们进行许多猜测(行动),并保留那些奖励更高的猜测(行动)。通过重复这个过程,我们允许更有前途的解决方案发展和成熟。

源
三、基于模型的强化学习
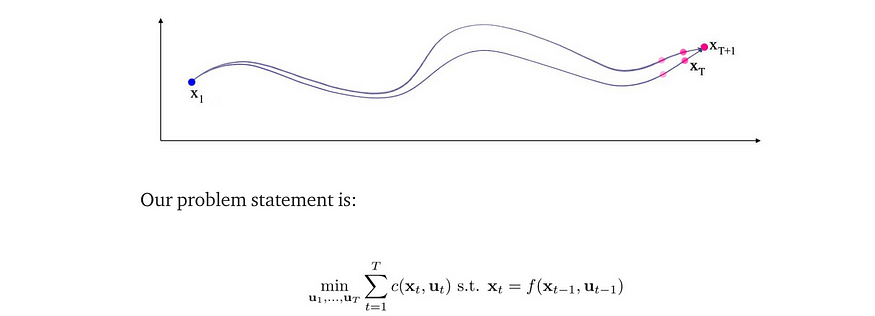
对于基于模型的RL,我们从系统动力学(模型)和成本函数开始,以做出最佳决策。

- 轨迹优化(例如 iLQR)— 使用模型和成本函数规划最佳操作(最佳策略)的最佳控制器。
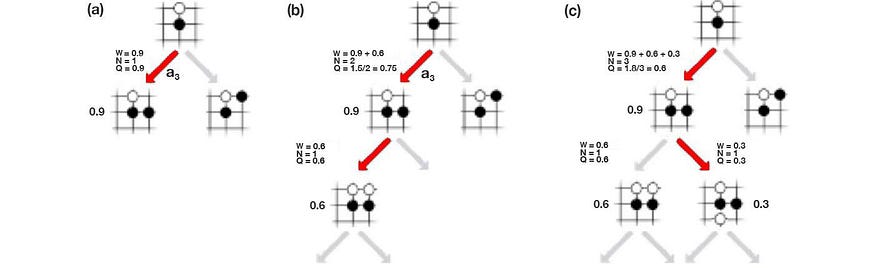
- 蒙特卡罗树搜索 (MCTS) — MCTS 是离散控制空间中的轨迹优化。MCTS 搜索可能的移动并将结果记录在搜索树中。它使用 Q 值函数来利用有希望的行动,并添加探索加成以实现更好的探索。最终,它会在确定下一步行动时构建本地策略。
- 反向传播(例如PILCO) — 如果成本函数和模型已知,我们可以通过成本函数和模型使用反向传播来改进策略。

- 模仿最优控制(例如引导策略搜索)—我们使用类似于轨迹优化的概念训练最优控制器。但与此同时,我们使用最优控制器生成的采样轨迹来创建策略π(下面的红框)。
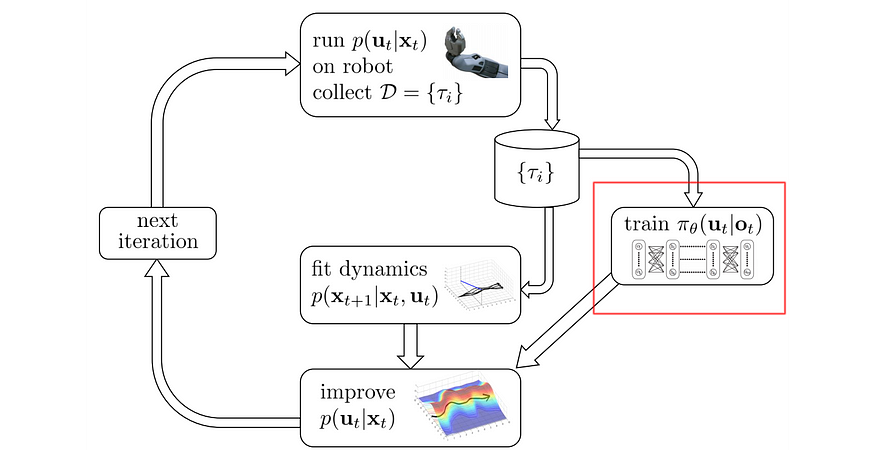
从源代码修改
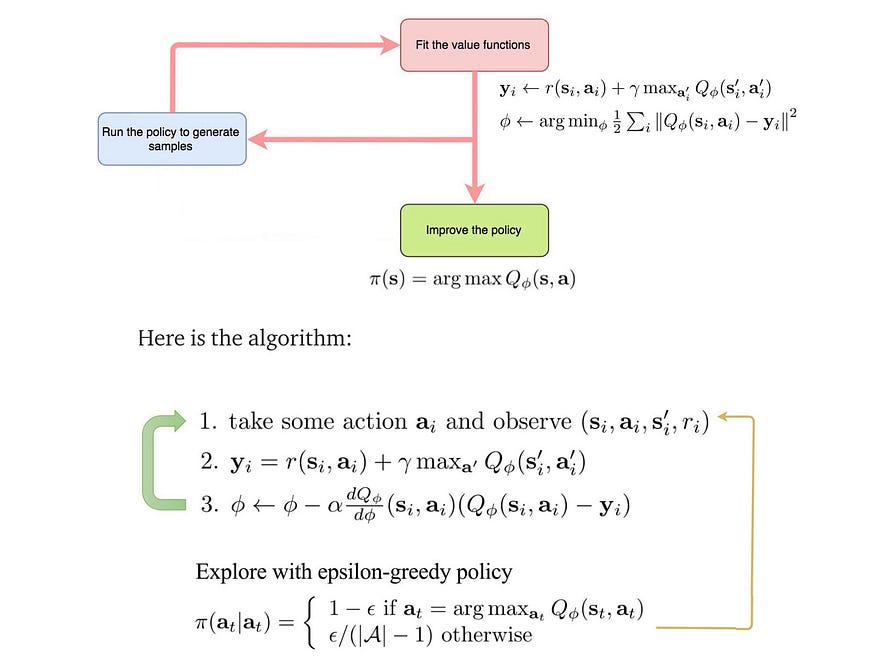
- 规划(例如 Dyna)— Dyna 使用真实经验来拟合价值函数(步骤 d),并在步骤 e 的“模型”中记录动态过渡和奖励。现在,我们可以随机重播“模型”的经验(步骤 f)以进一步训练值函数。

源

源
四、目的
无模型和基于模型的强化学习都会优化操作,以最大化预期奖励。
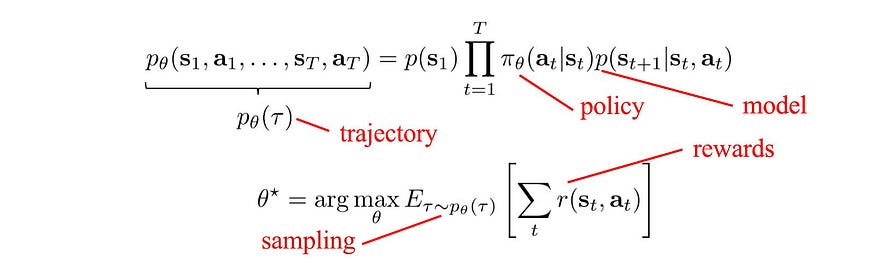
五、价值学习
价值学习使用监督学习来拟合抽样奖励中的 Q 值或 V 值。
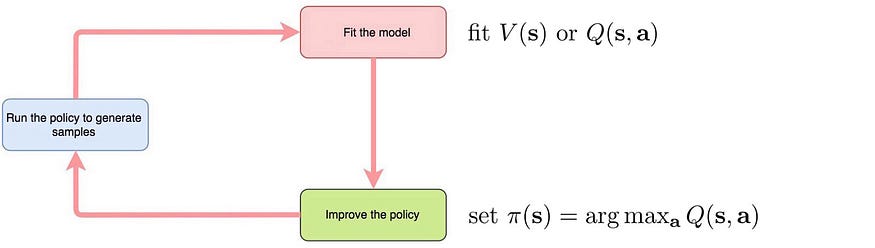
局限性:
- 最小化错误拟合:不直接优化最终策略。
- 当使用值函数的非线性近似器时,不能保证收敛。
- 如果值函数是近似的,而不是精确计算它,则存在稳定性问题。它可以通过像 DQN 中的方案那样来缓解。
- 许多超参数:目标网络延迟、重放缓冲区大小以及对学习速率的敏感性。
六、策略梯度
策略梯度使获得高回报的行动的可能性最大化。

为了稳定训练,我们用基线减去预期奖励以减少方差。
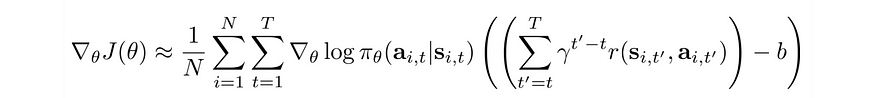
基线的一个常见选择是 V(S)。以下是定义:


强度:
- 直接优化策略。
- 与深度学习模型(包括 RNN)配合良好的梯度下降解决方案。
- 可以轻松地为目标函数添加约束和激励。
局限性
- 高方差。策略梯度是干扰的 - 若要缓解问题,请使用更大的批大小或信任区域。
- 难以调整的学习率 - 使用亚当或自然政策梯度方法,如PPO。
- 样品效率差 — 需要大量样品。
- 预期奖励的基线设计可能很复杂。
- 没有将问题完全定义为优化问题。
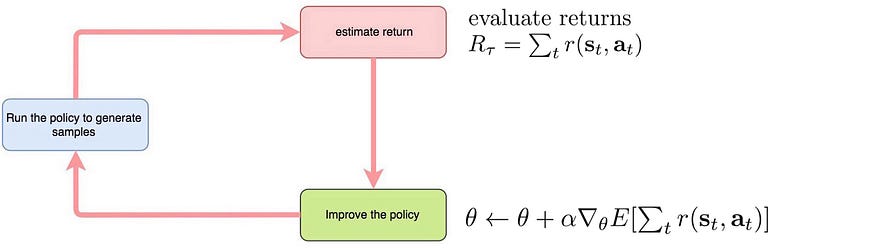
蒙特卡洛政策梯度
以下是策略梯度的算法,它使用完整的剧集推出(蒙特卡罗方法)来评估总奖励。
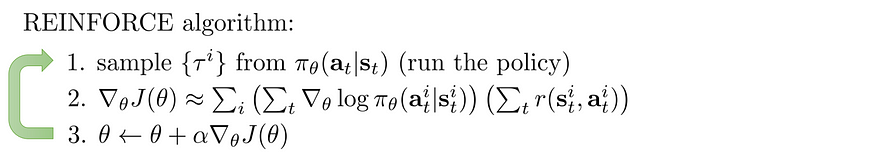
七、TRPO
策略梯度可能会进行激进的策略更改,从而破坏训练进度。TRPO是一种使用自然政策梯度的策略梯度方法。它使用信任区域来限制每次迭代中的策略更改,以实现更安全、更好的决策。

源
限度:
- TRPO中的共轭梯度很复杂,计算成本很高。
- H 的计算用于测量政策模型参数 θ 的曲率,它不能很好地与表达性政策模型(如 CNN 和 RNN)相适应。它在Atari基准测试中表现不佳。
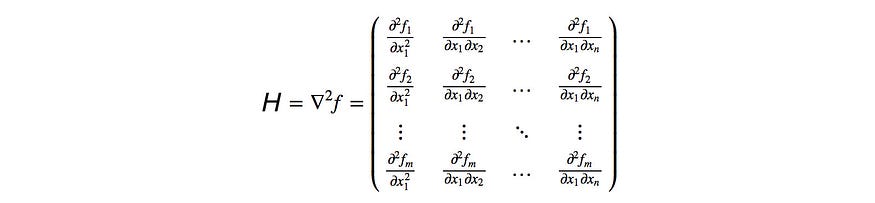
八、PPO
PPO类似于TRPO。它稍微放宽了策略更改限制,因此可以使用更快的一阶优化器,而不是计算二阶导数。

源
九、演员兼评论家
参与者-批评者方法是一种具有价值学习的策略梯度方法,以最小化预期奖励的方差。此更改稳定了训练。
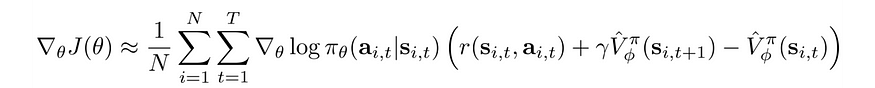

十、基于模型的强化学习
基于模型的强化学习从系统动力学(模型)和成本函数开始,以找到最佳控制。控制与此处的操作具有相同的含义。一旦训练了最佳控制器,我们仅使用它来采取行动。但有时,任务的策略可能比模型更简单。如果这是真的,我们可以使用模型和进一步规划来创建示例来训练策略(引导式策略搜索)。我们还可以使用经过训练的模型生成样本来学习价值函数(Dyna)。
基于模型的 RL(无显式策略)
我们使用采样轨迹拟合模型,并使用轨迹优化来规划进行最佳控制的控制器。
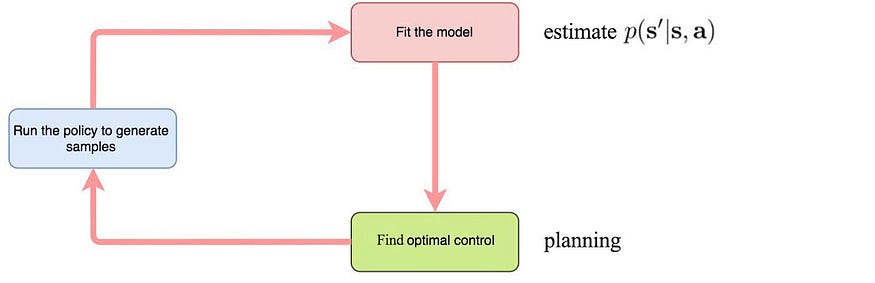
在规划中:
- 对于连续空间,请使用轨迹优化。
- 对于离散空间,请使用蒙特卡罗树搜索等方法。
局限性
- 专注于构建更好的模型。但更好的模式并不等同于更好的政策。
基于模型的RL(通过反向传播进行策略学习)
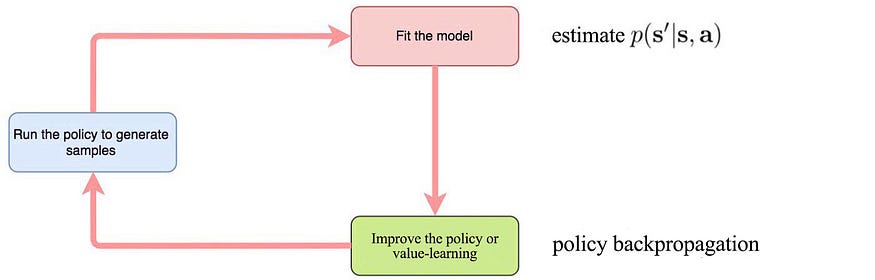
弱点
- 轨迹内的状态和操作高度相关。因此,计算出的梯度往往会自我放大。它可能会严重遭受消失和爆炸问题。

引导式策略搜索全球定位系统
GPS 使用轨迹优化来优化控制器。然后,我们运行控制器来生成轨迹,以便我们可以使用监督学习来学习策略。

从源代码修改
强度
- 在某些问题域中,策略比模型更容易学习。
动态
我们使用真实经验训练模型。稍后,我们使用经过训练的模型生成样本,以更好地学习 Q 值函数。
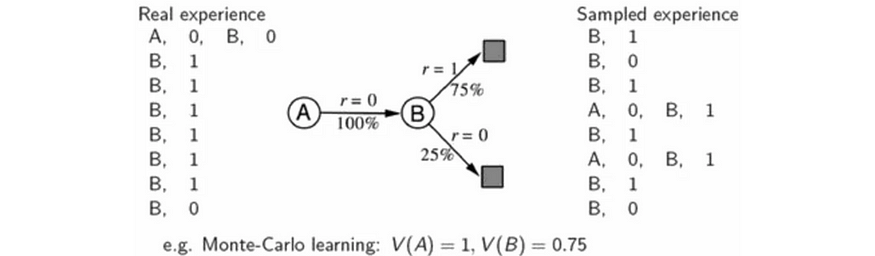
使用基于样本的计划进行基于模型的 RL(来源)

参考文章:
RL — Reinforcement Learning Algorithms Overview | by Jonathan Hui | Medium