图神经网络实战(10)——归纳学习
- 0. 前言
- 1. 转导学习与归纳学习
- 2. 蛋白质相互作用数据集
- 3. 构建 GraphSAGE 模型实现归纳学习
- 小结
- 系列链接
0. 前言
归纳学习 (Inductive learning) 通过基于已观测训练数据,建立一个通用模型,使模型能够对未见过的节点和图进行归纳预测,而转导学习(Transductive learning, 也称直推学习)是基于所有已经观测到的训练和测试数据构建模型,这种方法是通过已经有标记的节点信息来预测无标记数据节点,因此,在图神经网络 (Graph Neural Networks, GNN)、图卷积网络 (Graph Convolutional Network, GCN)、图注意力网络 (Graph Attention Networks,GAT) 和 GraphSAGE 等节中所构建的模型均属于转导学习模型。在本节中,我们将介绍图数据中的归纳学习和多标签分类,使用 GraphSAGE 模型在蛋白质相互作用 (protein-protein interactions) 数据集执行多标签分类任务,并了解归纳学习的优势和实现方法。
1. 转导学习与归纳学习
在图神经网络 (Graph Neural Networks, GNN)中,可以将学习分为两类,转导学习(Transductive learning, 也称直推学习)和归纳学习 (Inductive learning):
- 在归纳学习中,
GNN在训练过程中只看到训练集中的数据,而在测试过程中需要对未见过的数据进行预测,这属于机器学习中典型的监督学习 (supervised learning)。在这种情况下,标签用来调整GNN的参数,模型需要具备良好的泛化能力,能够从有限的样本中推断出普遍适用的规律 - 在转导学习中,
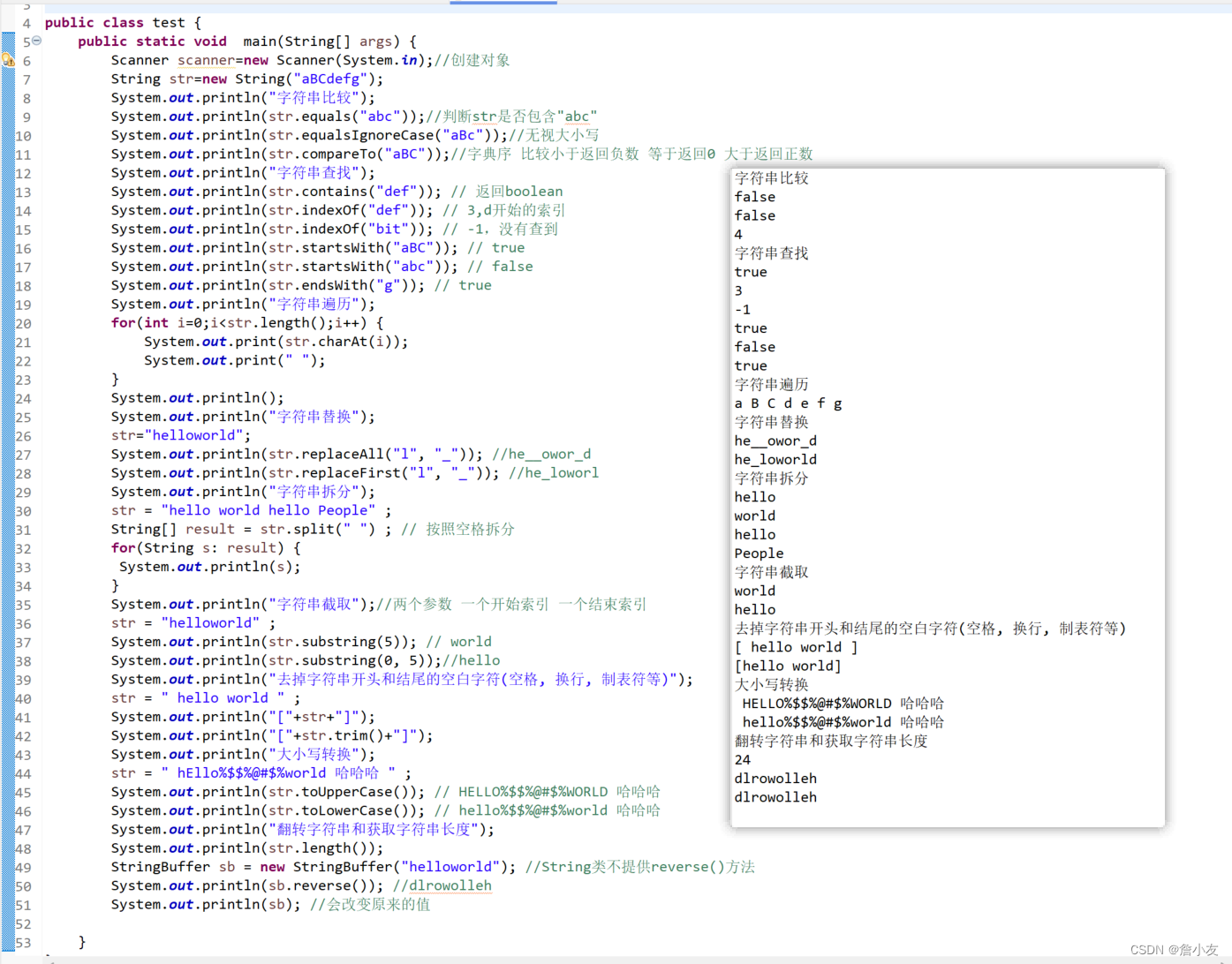
GNN在训练过程中会看到来自训练集和测试集的数据,它通过对已有的样本进行学习来进行预测和分类。模型只从训练集中学习数据,模型会尝试将已有的样本归类到已知的类别中,并根据这些样本的特征进行预测,标签用于信息扩散。转导学习不是直接从训练集中学习出一般性的规律,而是利用图数据间的相似性或连接性进行预测
我们在之前构建的图神经网络 (Graph Neural Networks, GNN) 和图卷积网络 (Graph Convolutional Network, GCN) 属于转导学习情况。而 GraphSAGE 模型可以在训练过程中使用整个图进行预测 (self(batch.x, batch.edge_index)),然后部分屏蔽这些预测,只使用训练数据计算损失并训练模型 (criterion(out[batch.train_mask], batch.y[batch.train_mask]))。
转导学习只能为固定的图生成嵌入,不能泛化到未见过的节点或图。但由于采用了邻居采样,GraphSAGE 可以在局部水平上对经过剪枝的计算图进行预测,这种情况下属于归纳学习框架,可以应用于具有相同特征模式的任何计算图。
2. 蛋白质相互作用数据集
在 GraphSAGE 一节中,我们已经在 PubMed 数据集上构建 GraphSAGE 模型实现了转导学习。接下来,我们将 GraphSAGE 应用于由 Agrawal 等人提出的蛋白质相互作用 (protein-protein interaction, PPI) 网络数据集。该数据集是 24 个图的集合,其中节点( 21,557 个)是人类蛋白质,边( 342,353 条)是人类细胞中蛋白质之间的连接。用 Gephi 制作的 PPI 图数据集可视化结果如下所示:

该数据集的目标是使用 121 个标签进行多标签分类,这意味着每个节点可以具有 0 到 121 个标签。这不同于多类别分类,多类别分类中每个节点只会属于一个类别。接下来,我们使用 PyTorch Geometric (PyG) 实现 GraphSAGE 模型用于对 PPI 数据集执行多标签分类任务。
(1) 将 PPI 数据集加载为三个不同的子集,训练集、验证集和测试集:
import torch
from sklearn.metrics import f1_scorefrom torch_geometric.datasets import PPI
from torch_geometric.data import Batch
from torch_geometric.loader import DataLoader, NeighborLoader
from torch_geometric.nn import GraphSAGE# Load training, evaluation, and test sets
train_dataset = PPI(root=".", split='train')
val_dataset = PPI(root=".", split='val')
test_dataset = PPI(root=".", split='test')
(2) 训练集包含 20 个图,而验证集和测试集只有两个图。对训练集应用邻居采样,为了方便起见,使用 Batch.from_data_list() 将所有训练图统一到一个集合中,然后应用邻居采样:
train_data = Batch.from_data_list(train_dataset)
train_loader = NeighborLoader(train_data, batch_size=2048, shuffle=True, num_neighbors=[20, 10], num_workers=2, persistent_workers=True)
(3) 训练集创建完毕后,使用 DataLoader 类创建批数据,将 batch_size 值定义为 2,与每批图的数量相对应:
val_loader = DataLoader(val_dataset, batch_size=2)
test_loader = DataLoader(test_dataset, batch_size=2)
(4) 定义设备使批处理能够在 GPU 上进行处理。如果计算机中有 GPU,使用 GPU,否则就使用 CPU:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
3. 构建 GraphSAGE 模型实现归纳学习
使用 PyTorch Geometric 的 torch_geometric.nn 模块构建 GraphSAGE 模型。
(1) 使用 GraphSAGE() 类初始化一个两层的 GraphSAGE 模型,其中隐藏维度为 512,此外,还需要使用 to(device) 将模型放置在与数据相同的设备上:
model = GraphSAGE(in_channels=train_dataset.num_features,hidden_channels=512,num_layers=2,out_channels=train_dataset.num_classes,
).to(device)
(2) fit() 函数与 GraphSAGE 一节中使用的函数类似,不同之处在于,我们希望尽可能将数据移动到 GPU 上,并且由于每批数据有两个图,因此将损失乘以 2 (data.num_graphs):
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)def fit(loader):model.train()total_loss = 0for data in loader:data = data.to(device)optimizer.zero_grad()out = model(data.x, data.edge_index)loss = criterion(out, data.y)total_loss += loss.item() * data.num_graphsloss.backward()optimizer.step()return total_loss / len(loader.data)
由于 val_loader 和 test_loader 包含两个图且 batch_size 值为 2,因此在 test() 函数中,两个图位于同一个批数据中,而无需像训练时那样在加载器中循环。
(3) 使用度量指标 F1 分数代替准确率,F1 分数相当于精确度和召回率的调和平均值。但,模型的预测结果是 121 维的实数向量,我们需要将其转换成二进制向量,使用 out > 0 将它们与 data.y 进行比较:
@torch.no_grad()
def test(loader):model.eval()data = next(iter(loader))out = model(data.x.to(device), data.edge_index.to(device))preds = (out > 0).float().cpu()y, pred = data.y.numpy(), preds.numpy()return f1_score(y, pred, average='micro') if pred.sum() > 0 else 0
(4) 对模型进行 300 个 epoch 的训练,并打印训练过程中模型在验证数据集上的 F1 分数:
for epoch in range(301):loss = fit(train_loader)val_f1 = test(val_loader)if epoch % 50 == 0:print(f'Epoch {epoch:>3} | Train Loss: {loss:.3f} | Val F1-score: {val_f1:.4f}')
'''
Epoch 0 | Train Loss: 12.686 | Val F1-score: 0.4866
Epoch 50 | Train Loss: 8.734 | Val F1-score: 0.7963
Epoch 100 | Train Loss: 8.600 | Val F1-score: 0.8098
Epoch 150 | Train Loss: 8.531 | Val F1-score: 0.8202
Epoch 200 | Train Loss: 8.495 | Val F1-score: 0.8230
Epoch 250 | Train Loss: 8.497 | Val F1-score: 0.8255
Epoch 300 | Train Loss: 8.432 | Val F1-score: 0.8290
'''
(5) 最后,计算测试集上的 F1 分数:
print(f'Test F1-score: {test(test_loader):.4f}')# Test F1-score: 0.8527
可以看到,在归纳学习中,模型在 PPI 数据集上训练后的 F1 分数为 0.9360。当增加或减少隐藏维度的大小时,模型的性能会有有大幅改变,我们可以使用不同的值,如 128 和 1,024,并观察训练的后的模型 F1 分数变化。
需要注意的是,在以上代码中,我们并未显式的使用掩码。这是由于实际上,归纳学习是由 PPI 数据集强制实现的;训练数据、验证数据和测试数据位于不同的图和数据加载器中。我们也可以使用 Batch.from_data_list() 将它们合并,然后再使用归纳学习的设定。
小结
在本节中,学习了图神经网络中转导学习(Transductive learning, 也称直推学习)和归纳学习 (Inductive learning) 的区别。其中,图神经网络中的归纳学习通常指的是从给定的训练图数据中学习出一个泛化能力强的模型,以便对未知图数据中的节点或边进行预测或分类,而转导学习通常指的是利用训练图数据和测试图数据之间的关联性进行推断,从而对给定的测试图数据进行预测或分类。并且构建了 GraphSAGE 模型在 PPI 数据集上测试了归纳学习,以执行多标签分类任务。
系列链接
图神经网络实战(1)——图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战(2)——图论基础
图神经网络实战(3)——基于DeepWalk创建节点表示
图神经网络实战(4)——基于Node2Vec改进嵌入质量
图神经网络实战(5)——常用图数据集
图神经网络实战(6)——使用PyTorch构建图神经网络
图神经网络实战(7)——图卷积网络(Graph Convolutional Network, GCN)详解与实现
图神经网络实战(8)——图注意力网络(Graph Attention Networks, GAT)
图神经网络实战(9)——GraphSAGE详解与实现