在文本挖掘领域,大量的数据都是非结构化的,很难从信息中直接获取相关和期望的信息,一种文本挖掘的方法:主题模型(Topic Model)能够识别在文档里的主题,并且挖掘语料里隐藏信息,并且在主题聚合、从非结构化文本中提取信息、特征选择等场景有广泛的用途。
一、模型介绍
LDA 模式是生成式模型,在这里,假设需要建模的数据为 X,标签信息为 Y。判别式模型:对 Y
的产生过程进行描述,对特征信息本身不建模。判别式模型有利于构建分类器或者回归分析生成式模型时需要对 X和 Y 同时建模,更适合做无监督学习分析。
生成式模型:描述一个联合概率分布 P(X,Y)的分解过程,这个分解过程是虚拟的过程,真实的数据不是这么产生的,但是任何一个数据的产生过程可以在数学上等价为一个联合概率分布。
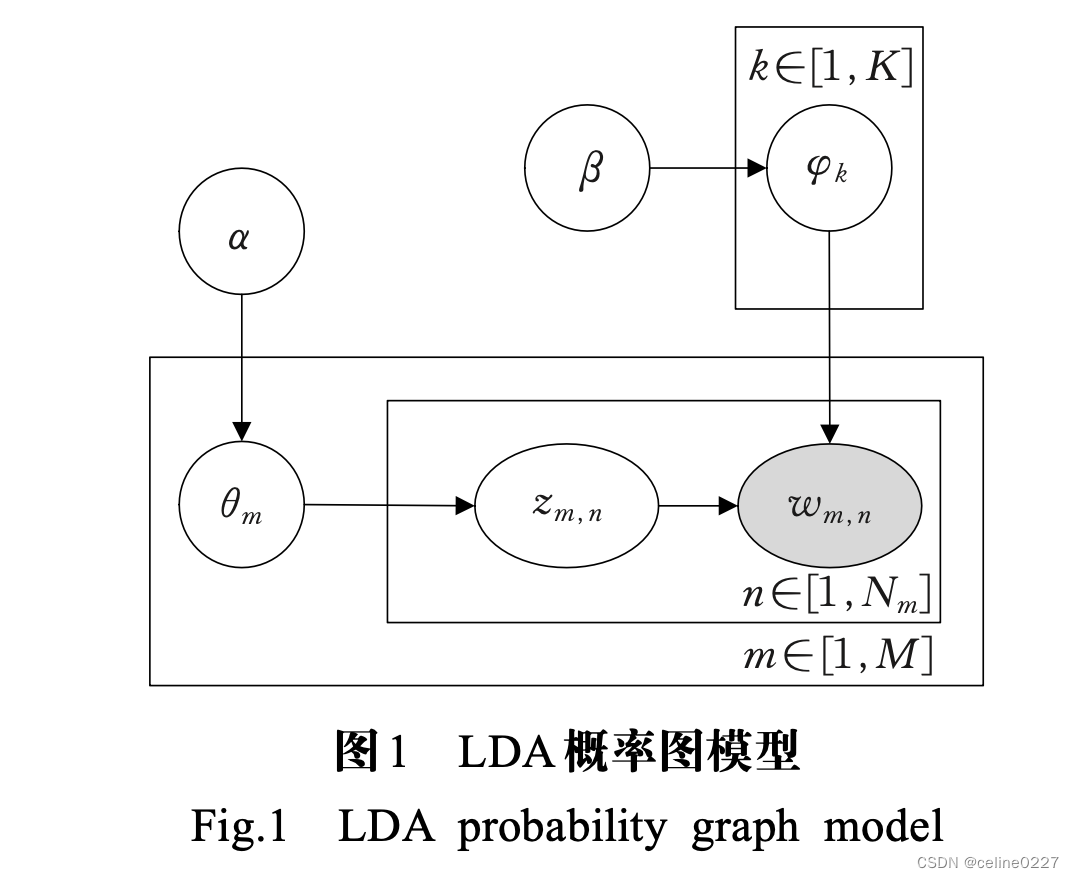
LDA 主题模型是三层贝叶斯概率生成模型,该模型认为文档是主题的概率分布,而主题是词汇的概率分布,LDA 概率图模型如图所示:
二、原理分析
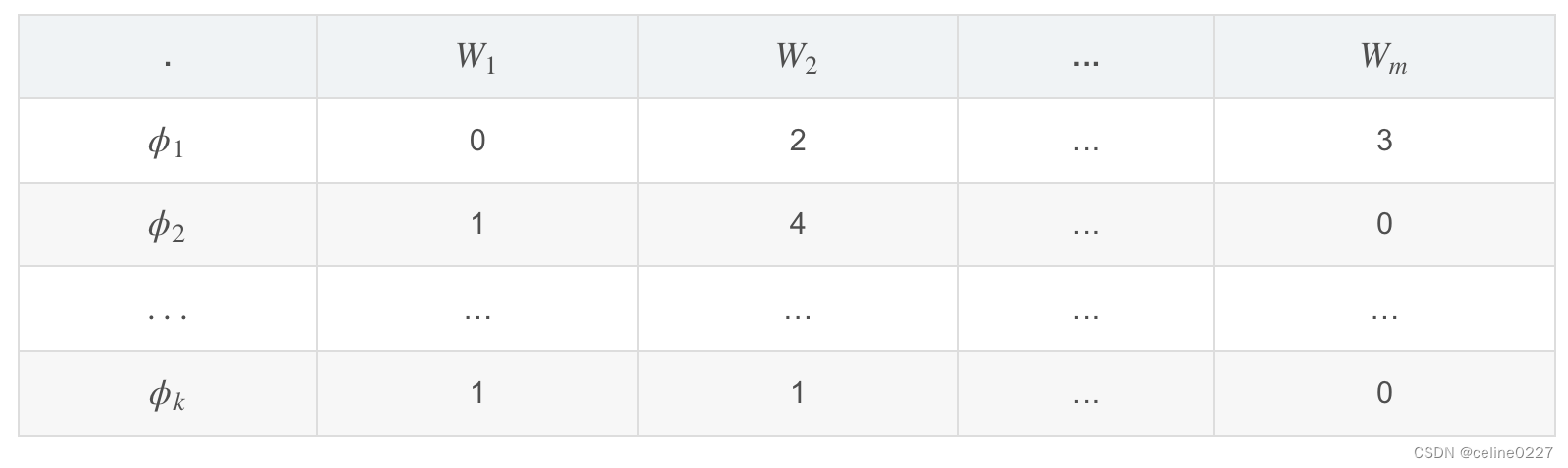
LDA 是一种矩阵分解技术,在向量空间中,任何语料(文档的集合)可以表示为文档(Document - Term,DT)矩阵。下面矩阵表达了一个语料库的组成:
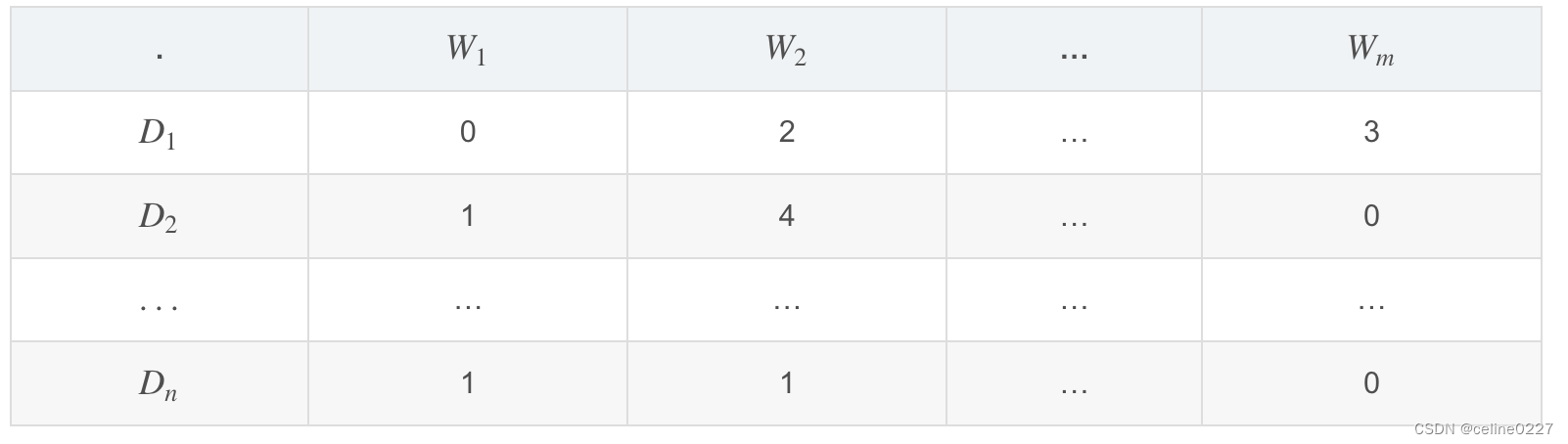
其中,N个文档 ,
...
的组成语料库,M个词 W1,W2,…,Wm 组成词汇表。矩阵中的值表示了词 Wj 在文档 Di中出现的频率。
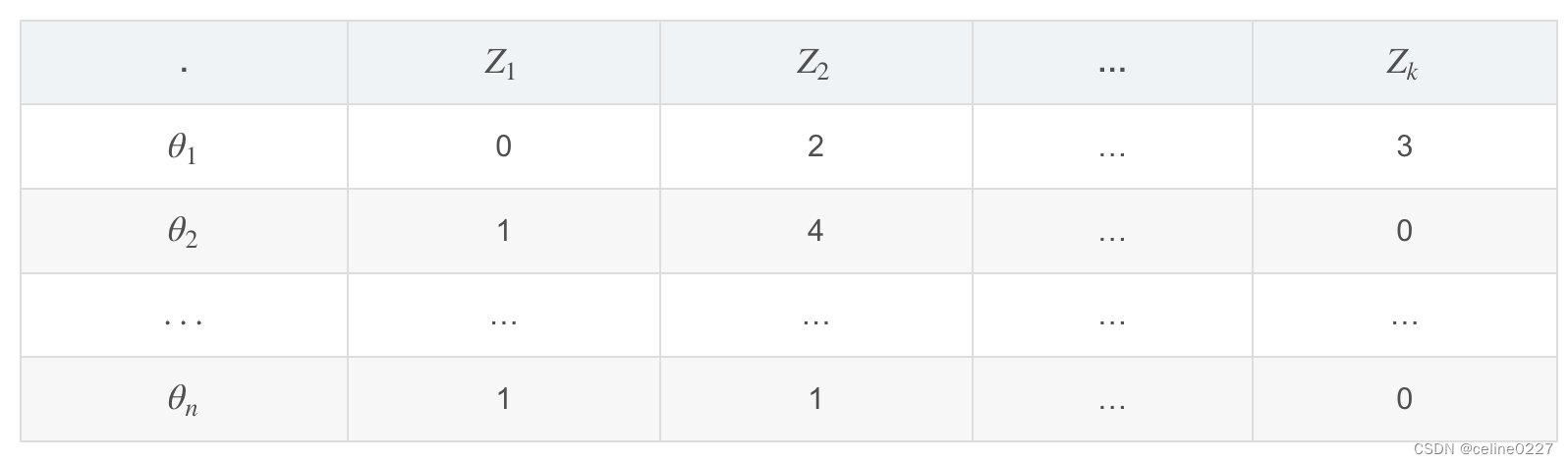
同时,LDA 将这个矩阵转换为两个低维度的矩阵,M1和 M2。
M1矩阵是一个 N∗Kdocument - topic 矩阵
N是指文档的数量,K是指主题的数量,M1中,是一个长度为 k的向量,用于描述当前文档
在 k个主题上的分布情况,Z表示具体的主题。
M2矩阵的情况,它是一个 K∗V维的 topic - term矩阵,K是指主题的数量,V指词汇表的大小。M2中每一行都是一个 分布,也就是主题
在 m个词上的多项式分布情况,可以通过学习得到。
三、训练过程
LDA 主题模型采用 Gibbs 采样算法,对第 m 篇文档的第 i 个单词 t 的隐含主题采样。吉布斯采样首先选取概率向量的一个纬度,给定其他维度变量值当前维度的值,不断收敛来输出代估参数:
1. 随机给每一篇文档的每一个字 随机分配主题编号 z
2. 统计每个主题 下出现字
的数量,每个文档n中出现主题
中字
的数量
3. 每次排除当年词 的主题
,根据其他所有词的主题分类,来估计当前词
分配到各个主题
,
...
的概率。得到概率分布后,重新为词采样一个新的主题
。用同样的方法不断更新到下一个词的主题,直到每个文档下的主题分布
和每个主题下的词分布
收敛。
4. 最后输出待估计参数和
。
二、LDA 的参数
β:表示 topic-word 密度, β越高,主题包含的单词更多,反之包含的单词更少
α:表示 document-topic 密度, α越高,文档包含的主题更多,反之包含的主题更少
主题数量:主题数量从语料中抽取得到,使用 Kullback Leibler Divergence Score 可以获取最好的主题数量。
主题词数:组成一个主题所需要的词的数量。这些词的数量通常根据需求得到,如果说需求是抽取特征或者关键词,那么主题词数比较少,如果是抽取概念或者论点,那么主题词数比较多。
迭代次数:使得 LDA 算法收敛的最大迭代次数
三、代码实现
1. 通过调整观测困惑度和一致性调整参数
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as plt# 尝试不同的主题数量
num_topics_range = range(2, 11)
perplexity_scores = []
coherence_scores = []
for num_topics in num_topics_range:print(f"\nTrying with {num_topics} topics:")# 训练 LDA 模型lda_model = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=1)# 计算困惑度perplexity_score = lda_model.log_perplexity(corpus)perplexity_scores.append(perplexity_score)# 计算一致性coherence_model = CoherenceModel(model=lda_model, texts=train_set, dictionary=dictionary, coherence='c_v')coherence_score = coherence_model.get_coherence()coherence_scores.append(coherence_score)# 绘制曲线图
plt.figure(figsize=(10, 5))# 绘制困惑度曲线
plt.subplot(1, 2, 1)
plt.plot(num_topics_range, perplexity_scores, marker='o')
plt.title('Perplexity vs. Number of Topics')
plt.xlabel('Number of Topics')
plt.ylabel('Perplexity')
plt.grid(True)
# 绘制一致性曲线
plt.subplot(1, 2, 2)
plt.plot(num_topics_range, coherence_scores, marker='o', color='orange')
plt.title('Coherence vs. Number of Topics')
plt.xlabel('Number of Topics')
plt.ylabel('Coherence')
plt.grid(True)
plt.tight_layout()
plt.show()困惑度:困惑度值越低越好,选择困惑度最小的主题数
一致性:一致性值越高越好,选择一致性最大的主题数
2. 模型参数调整
lda_model = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=20, random_state=1)corpus: 训练LDA模型的基础数据。文档-词频矩阵或doc2bow格式的数据,代表预处理后的文档集合。id2word: Dictionary对象,包含了词汇表和词语到索引的映射。通常从文档集合自动生成。num_topics: 主题数量;默认值为1。chunksize: 每次迭代处理的文档块大小。较大的块大小可以加快训练速度,但可能需要更多内存。默认值为10。passes: 对整个语料库的遍历次数。更多的遍历可能会提高模型的质量,但也会增加计算时间。默认值为1。iterations: 每次遍历中的迭代次数。默认值为20。alpha: 可选。主题 Dirichlet 分布的共现参数。可以使用'symmetric'(默认)或'asymmetric',或者直接指定为一个正的浮点数。较小的值会使模型倾向于更多的主题共享词语,较大的值会使模型倾向于更少的主题共享词语。eta: 文档 Dirichlet 分布的共现参数。可以使用'auto'(默认),'1/N'或直接指定为一个正的浮点数,其中N是词汇表的大小。较大的值会使主题分布更均匀,较小的值可能会导致更集中的主题分布。random_state: 随机数生成器的种子。用于确保结果的可重复性。默认为None,即随机。update_every: 每隔多少文档更新一次主题分配。较小的值可以加快训练速度,但可能会影响模型质量。默认值为1。perplexity: 是否在训练过程中计算困惑度(perplexity)。困惑度是衡量模型拟合数据好坏的指标。默认值为False。chaining: 是否使用“chaining”近似来加速训练过程。开启此选项可以显著加快训练速度,但可能会略微降低模型质量。默认值为True。calc_prob: 是否在训练结束后计算文档中每个词语属于每个主题的概率。这会增加额外的内存消耗。默认值为False。四、词向量(Word2Vec) + 主题模型(LDA) + 关键词网络分析
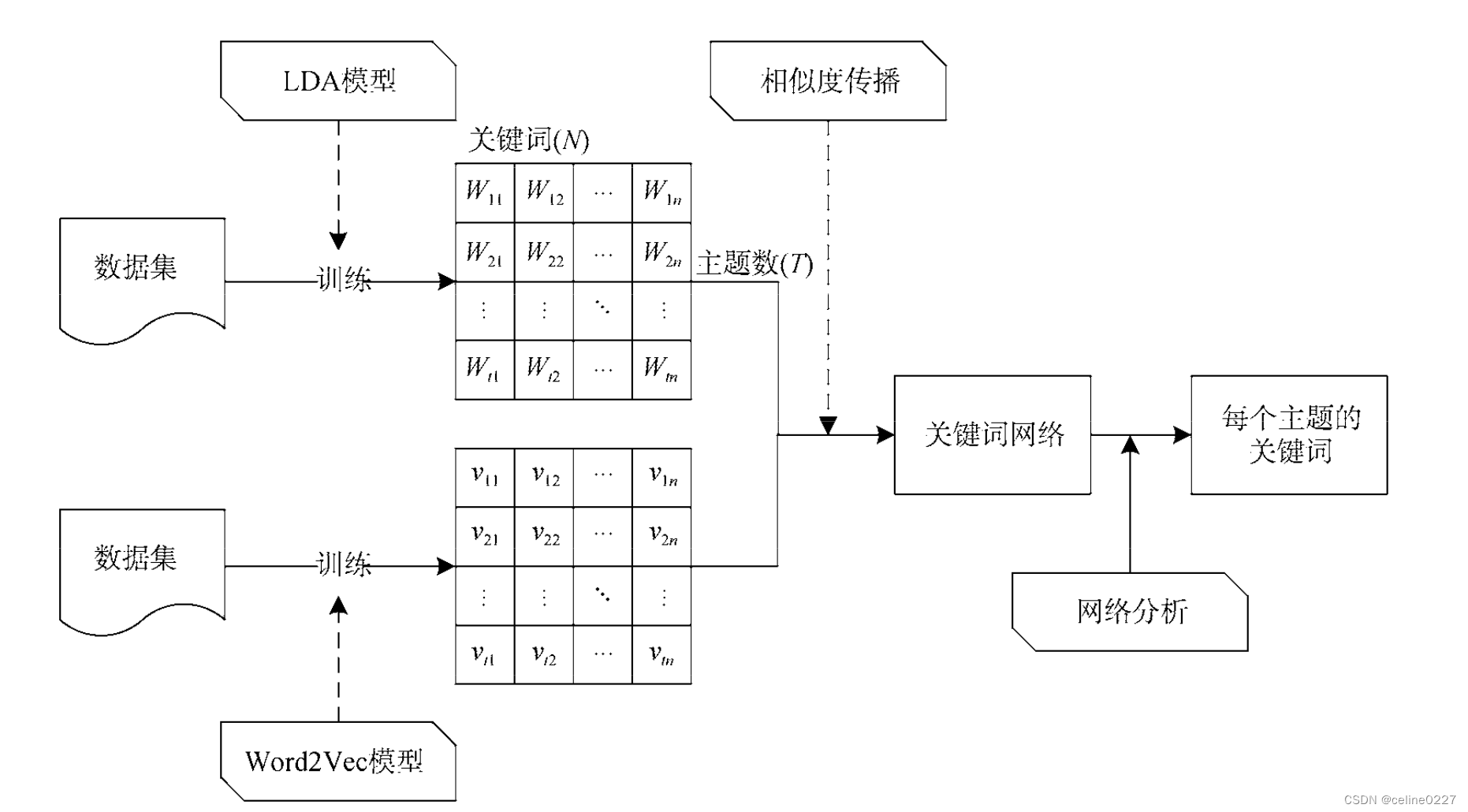
文献:融合主题词嵌入和网络结构分析的主题关键词提取方法
1. 实现过程
a. 首先利用 LDA 对于数据集的主题进行初步提取,生成 主题 - 词 (m×n) 矩阵
b. 用 Word2Vec 训练数据集,得到词向量模型
For each t in Topic (m):
For each w in KeyWords (n):
利用生成的词向量模型,用余弦法计算该主题下词与词的相似度,作为两点之间的权重;
设置阈值,过滤掉权重较低的词关系,其余的两两词之间连成一条边;
利用 PageRank 方法进行迭代,最后输出 PR 值最高的 TopN 个词作为该主题下的关键词。