在深度学习中,数据处理是模型训练的关键环节之一。Hugging Face Datasets 库提供了一套强大的工具来简化这一过程,使数据集的管理和预处理变得高效且直观。本文将详细介绍 Hugging Face Datasets 库的基本用法和数据预处理策略,并结合实际代码示例,帮助您掌握这一工具的使用方法。
一、Hugging Face Datasets 库简介
1. Hugging Face Datasets 库是什么?
Hugging Face Datasets 是一个开源 Python 库,旨在简化自然语言处理(NLP)、计算机视觉(CV)和音频任务的数据集处理。通过这个库,您可以轻松加载、处理和共享数据集,仅需一行代码即可完成大部分数据集的加载工作。它与 Hugging Face Hub 深度集成,使得数据集的管理和共享变得更加便捷。
2. 使用 Datasets 下载开源数据集
通过 datasets 库,您可以轻松下载和加载各种开源数据集。以下是一个示例,演示如何下载并加载 GLUE 数据集中的 MRPC 任务:

在上述代码中,我们使用 load_dataset 函数加载了 GLUE 数据集的 MRPC 任务。这个函数会自动从 Hugging Face Hub 下载数据集并进行基本的预处理。
3. Datasets.load_dataset 实现原理简介

datasets.load_dataset() 函数背后使用了 DatasetBuilder 类,该类负责数据集的下载和构建。该函数首先检查本地缓存是否存在数据集,如果缓存中没有,则从 Hugging Face Hub 下载数据。然后,DatasetBuilder 类将数据集加载到内存中,并进行初步的处理。
4. 构造 DatasetBuilder 类的主要配置 BuilderConfig
在构造自定义数据集时,DatasetBuilder 类使用 BuilderConfig 类来配置数据集的各种属性。例如,您可以指定数据集的类别标签或其他属性。以下是如何创建自定义配置的示例:
from datasets import DatasetBuilder, BuilderConfigclass CustomDatasetBuilder(DatasetBuilder):BUILDER_CONFIGS = [ BuilderConfig(name="custom_config", description="A custom dataset configuration") ] def _info(self): return DatasetInfo( description="Custom dataset", features=Features({ "text": Value(dtype="string"), "label": ClassLabel(names=["negative", "positive"]) }) ) def _split_generators(self, dl_manager): # 实现数据下载和划分的逻辑 pass def _generate_examples(self, filepath): # 实现数据生成的逻辑 pass
在这个示例中,我们定义了一个名为 CustomDatasetBuilder 的数据集构建器,并指定了一个自定义的 BuilderConfig。_info 方法定义了数据集的基本信息,包括数据特征和标签。
5. 实际构造数据集的类 DatasetBuilder
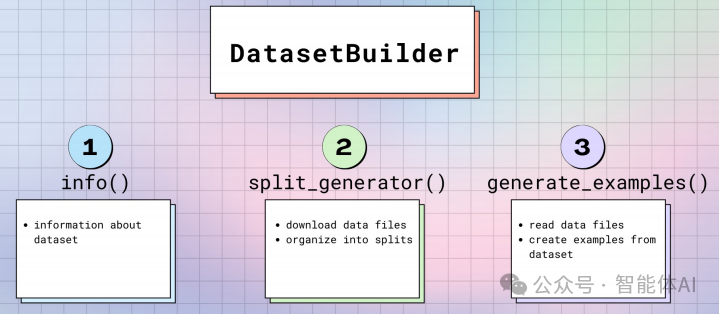
DatasetBuilder 类是数据集构建的核心,通过继承和实现其中的方法,我们可以创建自定义的数据集。例如,您可以实现数据的下载、处理和生成逻辑:
from datasets import DatasetBuilderclass MyDatasetBuilder(DatasetBuilder):def _split_generators(self, dl_manager): # 下载数据集并返回数据划分 return [ SplitGenerator(name="train", gen_kwargs={"filepath": "path/to/train_data"}), SplitGenerator(name="test", gen_kwargs={"filepath": "path/to/test_data"}) ] def _generate_examples(self, filepath): # 从文件中读取数据并生成示例 with open(filepath, "r") as file: for id_, line in enumerate(file): yield id_, {"text": line.strip(), "label": 1} # 示例标签
6. Datasets 帮助构建不同用途的数据集
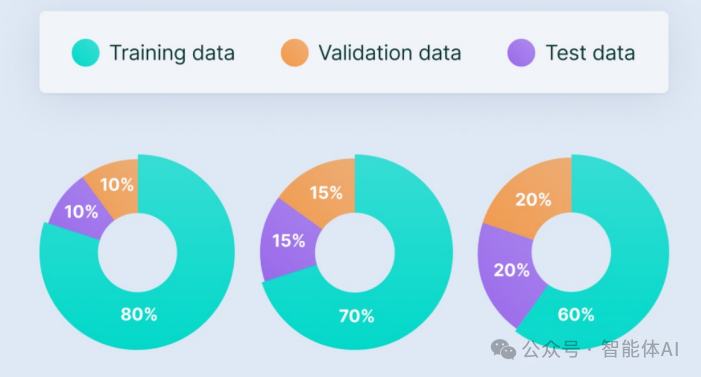
使用 Hugging Face Datasets 库,您可以轻松创建训练集、验证集和测试集。只需在数据集构建器中定义不同的数据划分,即可实现这一目标:
dataset = load_dataset('glue', 'mrpc', split='train') # 加载训练集
二、数据预处理策略:填充与截断
在处理数据时,填充(Padding)和截断(Truncation)是两种常见的预处理策略。这些策略确保模型输入的数据符合要求,并提高训练效率。
1. 数据预处理策略:填充(Padding)

填充是将序列扩展到固定长度,以便于批处理。以下是使用 Hugging Face Datasets 库进行填充的示例:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")def preprocess_function(examples):return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)dataset = load_dataset('glue', 'mrpc')
dataset = dataset.map(preprocess_function, batched=True)
在这个示例中,我们使用 AutoTokenizer 对数据进行填充,将所有输入序列扩展到最大长度 128。
2. 数据预处理策略:截断(Truncation)

截断是将超出最大长度的数据裁剪掉,以避免模型处理过长的输入数据:
def preprocess_function(examples):return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)dataset = load_dataset('glue', 'mrpc')
dataset = dataset.map(preprocess_function, batched=True)
在上述代码中,truncation=True 参数确保了输入序列被截断到最大长度 128。
三、使用 Datasets.map 方法处理数据集

datasets.map 方法允许我们对数据集进行批量处理。通过将自定义的预处理函数应用于数据集,可以实现高效的数据处理和转换:
def preprocess_function(examples):return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)# 使用 map 方法应用预处理函数
processed_dataset = dataset.map(preprocess_function, batched=True)# 打印处理后的数据集样本
print(processed_dataset)
在这个示例中,datasets.map 方法将 preprocess_function 应用到整个数据集,从而实现批量的填充和截断。
四、总结
Hugging Face Datasets 库提供了强大的数据集管理和处理功能,使得数据的准备和处理变得更加高效。通过掌握库的基本用法和数据预处理策略,您可以更好地为 Transformers 模型的微调做好数据准备。希望本文能帮助您更好地理解和使用 Hugging Face Datasets 库,提高模型训练的效果。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习还有100套面试题等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。




