单机搭建
kafka_1">一、安装kafka
1.安装前要先了解:由于kafka依赖zookeeper环境,所以要先安装zookeeper、再安装kafka
2.安装zookeeper
sudo docker pull wurstmeister/zookeeper
3.安装kafka
sudo docker pull wurstmeister/kafka
4.分别启动zookeeper和kafka
# 1、创建并启动zookeeper
sudo docker run -d --name zookeeper -p 2181 -t wurstmeister/zookeeper# 2、创建并启动kafka
sudo docker run -d --name kafka -p 9092:9092
-e KAFKA_BROKER_ID=1
-e KAFKA_ZOOKEEPER_CONNECT=192.168.158.130:2181/kafka
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.158.130:9092
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
-v /etc/localtime:/etc/localtime wurstmeister/kafka# 3、说明:
KAFKA_BROKER_ID=1 kafka在集群中的唯一标识
KAFKA_ZOOKEEPER_CONNECT=192.168.158.130:2181 监听zookeeper的地址
KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.158.130:9092 kafka服务器的地址
KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 指定端口
5.进入kafka容器,使用kafka创建消息生产者,和消息消费者
# 进入容器
docker exec -it 容器ID bash# 运行kafka生产者发送消息
/opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic hellokafka# 重新开一个窗口
# 运行kafka消费者接受消息
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hellokafka
kafkamap_50">二、安装kafka-map可视化
1、 拉取kafka-map镜像
docker pull dushixiang/kafka-map:latest
docker run -d --name kafka-map -p 9001:8080-v /opt/kafka-map/data:/usr/local/kafka-map/data-e DEFAULT_USERNAME=admin-e DEFAULT_PASSWORD=admindushixiang/kafka-map:latest
3、访问:http://192.168.56.103:9001
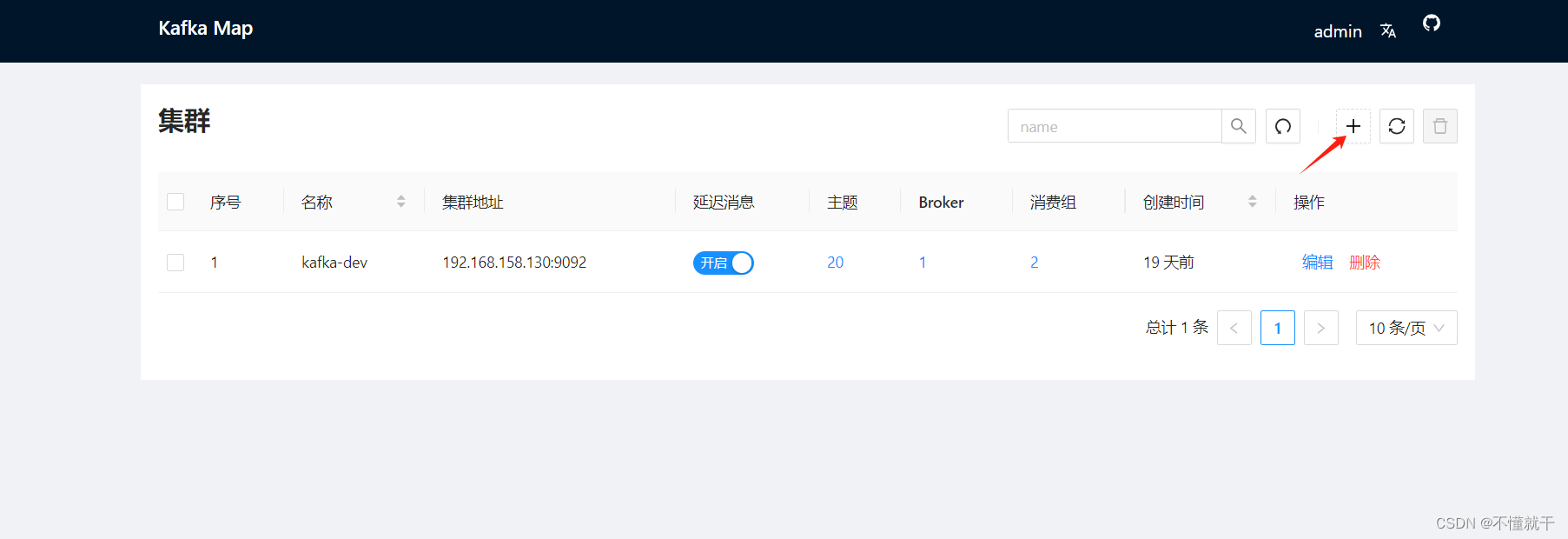
点击右上角+号完成kafka的接入:
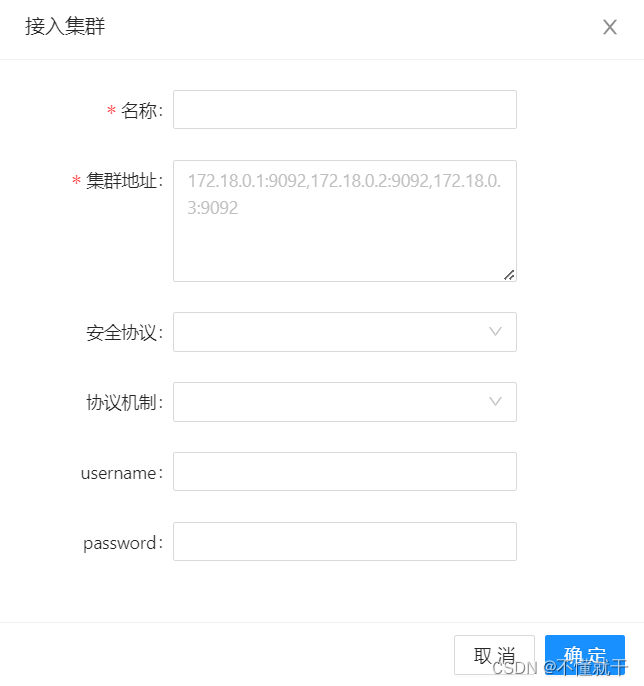
集群搭建
本次基于docker搭建kafka集群,zookeeper使用单实例
1、准备2台虚拟机,ip分别是:192.168.56.103,192.168.56.104
2、104 上操作
a、拉取zookeeper镜像
docker pull wurstmeister/zookeeper
b、启动zookeeper容器
docker run -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime wurstmeister/zookeeper
c、拉取kafka镜像
docker pull wurstmeister/kafka
e、拉取kafka-map镜像
docker pull dushixiang/kafka-map:latest
docker run -d --name kafka-map-p 9001:8080-v /opt/kafka-map/data:/usr/local/kafka-map/data-e DEFAULT_USERNAME=admin-e DEFAULT_PASSWORD=admindushixiang/kafka-map:latest
3、103上操作
a、拉取kafka镜像
docker pull wurstmeister/kafka
docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=192.168.56.103:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.56.103:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka
注意:103和104启动kafka的区别就是指定不同的KAFKA_BROKER_ID,如果是以配置文件启动的,在配置文件中修改即可
kafkamapkafka_115">4 登录到kafka-map上创建对应的kafka集群信息,实现界面化操作