1.背景
2023年,M Abdel-Basset等人受到克拉克的星鸦自然行为启发,提出了星鸦优化算法算法(Nutcracker Optimization Algorithm, NOA)。


2.算法原理
2.1算法思想
NOA模拟了星鸦自然行为,星鸦在不同的时期表现出两种不同的行为。星鸦的季节性行为可以分为两个主要部分:
- 夏季和秋季的种子储存:在这两个季节,星鸦积极寻找种子并将其储存在精心挑选的贮藏处,为冬季缺食的时期做准备。
- 冬季和春季的基于记忆的寻食:利用空间记忆策略,星鸦通过识别地标和其他视觉线索来找到之前隐藏的种子。如果无法找到储存的种子,它们则会随机探索周围环境以寻找食物。

2.2算法过程
NOA模拟星鸦的行为,两种主要策略:(i)觅食和储存策略;(ii)缓存搜索和恢复策略。
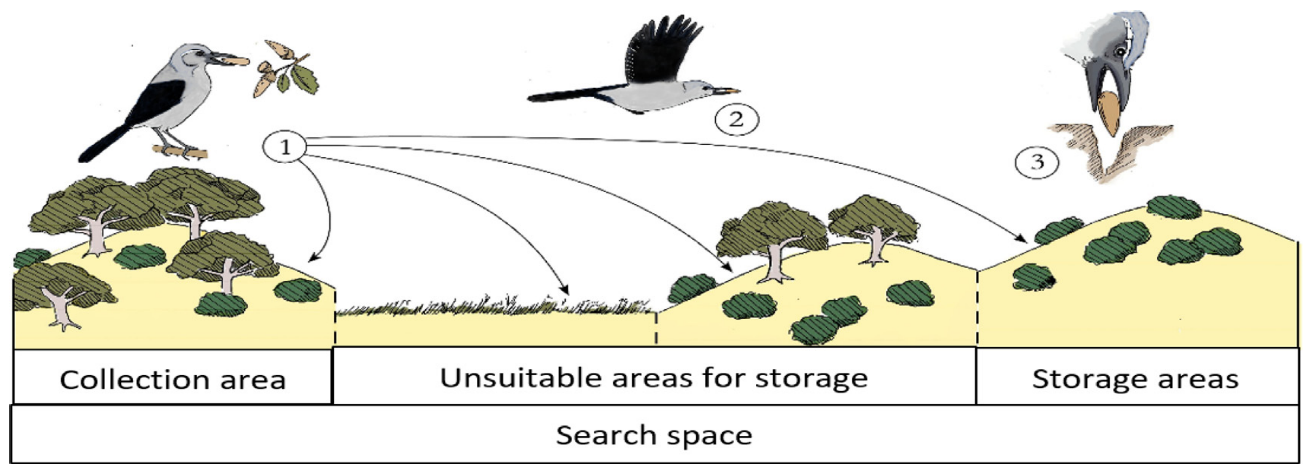
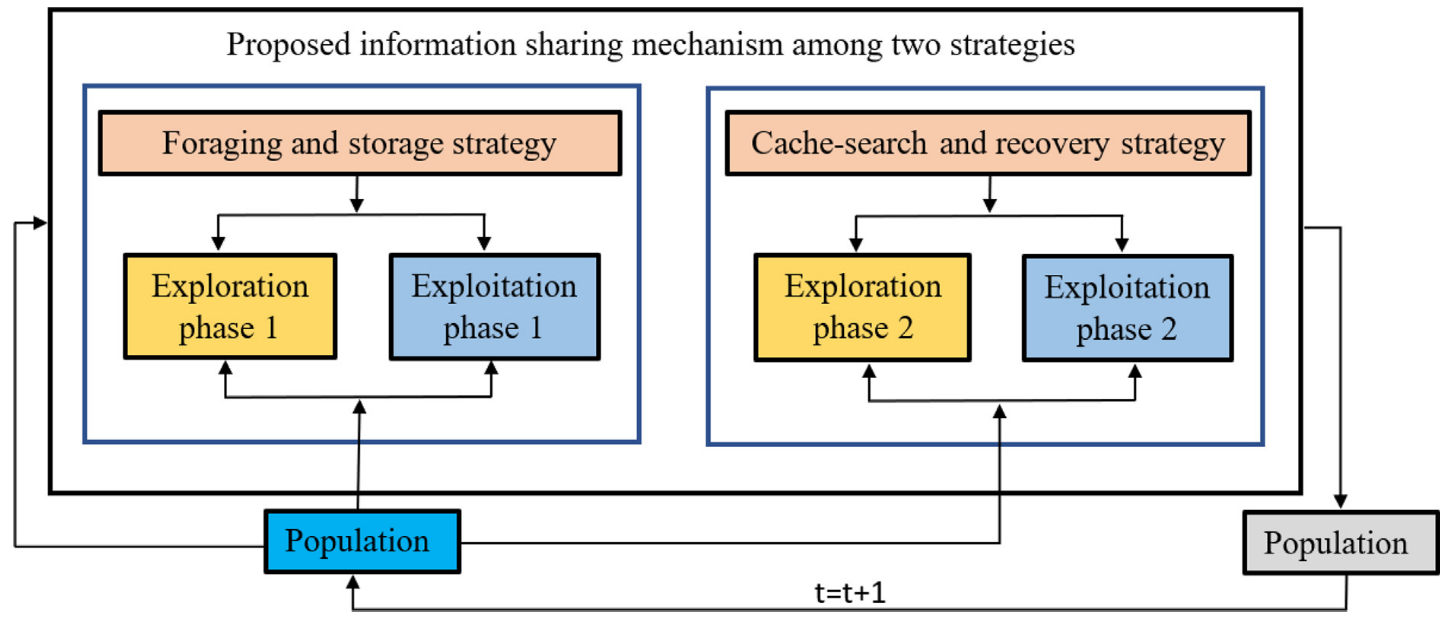
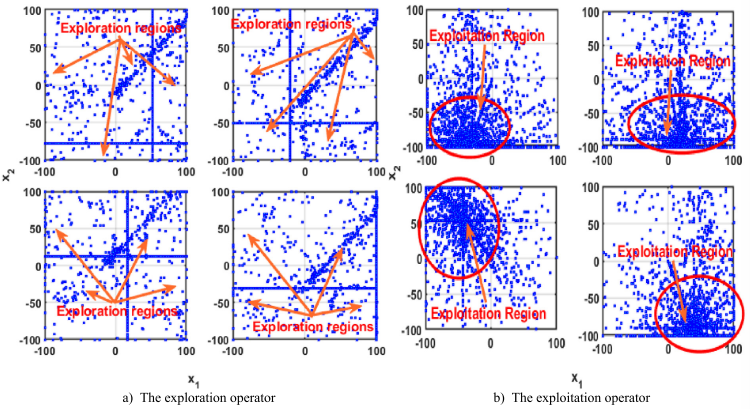
觅食阶段:探索阶段1
星鸦在搜索空间内进行寻食,它首先检查每个锥体的初始位置来寻找种子。如果发现优质的种子,星鸦会将其运送到储藏区并将其埋藏。如果未找到优质种子,它将继续在松树或其他树种的不同位置搜索新的种子:
X ⃗ i t + 1 = { X i , j t i f τ 1 < τ 2 { X m , j t + γ ⋅ ( X A , j t − X B , j t ) + μ . ( r 2 . U j − L j ) , i f t ≤ T m a x / 2.0 X C , j t + μ ⋅ ( X A , j t − X B , j t ) + μ . ( r 1 < δ ) . ( r 2 . U j − L j ) , o t h e r w i s e (1) \vec{X}_{i}^{t+1}=\begin{cases}X_{i,j}^{t}&\mathrm{if~}\tau_{1}<\tau_{2}\\\begin{cases}X_{m,j}^{t}+\gamma\cdot\left(X_{A,j}^{t}-X_{B,j}^{t}\right)\\\\+\mu.\left(r^{2}.U_{j}-L_{j}\right),&\mathrm{if~}t\leq T_{max}/2.0\\\\X_{C,j}^{t}+\mu\cdot\left(X_{A,j}^{t}-X_{B,j}^{t}\right)\\\\+\mu.\left(r_{1}<\delta\right).\left(r^{2}.U_{j}-L_{j}\right),&\mathrm{otherwise}\end{cases}\\\end{cases}\tag{1} Xit+1=⎩ ⎨ ⎧Xi,jt⎩ ⎨ ⎧Xm,jt+γ⋅(XA,jt−XB,jt)+μ.(r2.Uj−Lj),XC,jt+μ⋅(XA,jt−XB,jt)+μ.(r1<δ).(r2.Uj−Lj),if t≤Tmax/2.0otherwiseif τ1<τ2(1)
γ参数为莱维飞行得到,µ是基于正态分布(τ4), levy-flight (τ5),随机在0到1 (τ3)之间生成的数:
μ = { τ 3 i f r 1 < r 2 τ 4 i f r 2 < r 3 τ 5 i f r 1 < r 3 (2) \mu=\begin{cases}\tau_3&if r_1<r_2\\[2ex]\tau_4&if r_2<r_3\\[2ex]\tau_5&if r_1<r_3\end{cases}\tag{2} μ=⎩ ⎨ ⎧τ3τ4τ5ifr1<r2ifr2<r3ifr1<r3(2)
τ1和τ2作为尺度因子控制NOA探索能力,可以在τ1和τ2的大小范围内交替进行局部和全局搜索。µ提供星鸦信息有关所需的方向与各种步长,以探索一个新的位置。
存储阶段:开发阶段1
星鸦首先将在前一阶段(探索阶段1)中获得的食物运送到临时存储地点(存储区域):
X ⃗ i t + 1 ( n e w ) = { X ⃗ i t + μ ⋅ ( X ⃗ b e s t t − X ⃗ i t ) ⋅ ∣ λ ∣ + r 1 ⋅ ( X ⃗ A t − X ⃗ B t ) if τ 1 < τ 2 X ⃗ b e s t t + μ ⋅ ( X ⃗ A t − X ⃗ B t ) if τ 1 < τ 3 X ⃗ b e s t t ⋅ l Otherwise (3) \vec{X}_i^{t+1(new)}=\begin{cases}\vec{X}_i^t+\mu\cdot\left(\vec{X}_{best}^t-\vec{X}_i^t\right)\cdot|\lambda|+r_1\cdot\left(\vec{X}_A^t-\vec{X}_B^t\right)&\text{if }\tau_1<\tau_2\\\vec{X}_{best}^t+\mu\cdot\left(\vec{X}_A^t-\vec{X}_B^t\right)&\text{if }\tau_1<\tau_3\\\vec{X}_{best}^t\cdot l&\text{Otherwise}\end{cases}\tag{3} Xit+1(new)=⎩ ⎨ ⎧Xit+μ⋅(Xbestt−Xit)⋅∣λ∣+r1⋅(XAt−XBt)Xbestt+μ⋅(XAt−XBt)Xbestt⋅lif τ1<τ2if τ1<τ3Otherwise(3)
l是NOA开发行为从1到0线性递减的因子,觅食阶段与缓存之间平衡:
X ⃗ i t + 1 = { Eq.(1), if φ > P a 1 Eq.(3), otherwise (4) \vec{X}_i^{t+1}=\begin{cases}\text{Eq.(1),}&\text{if }\varphi>P_{a_1}\\[2ex]\text{Eq.(3),}&\text{otherwise}\end{cases}\tag{4} Xit+1=⎩ ⎨ ⎧Eq.(1),Eq.(3),if φ>Pa1otherwise(4)
其中φ是0到1之间的随机数,Pa1表示从1到0线性递减的概率值。

参考记忆
在将种子储存好之后,星鸦将会激活记忆,它们依靠对贮藏物所在位置的记忆来度过冬天。
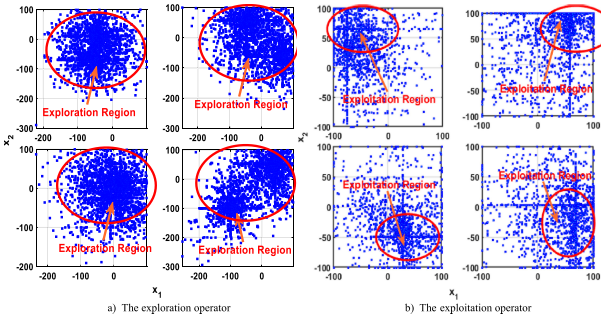
缓存搜索阶段:探索阶段2
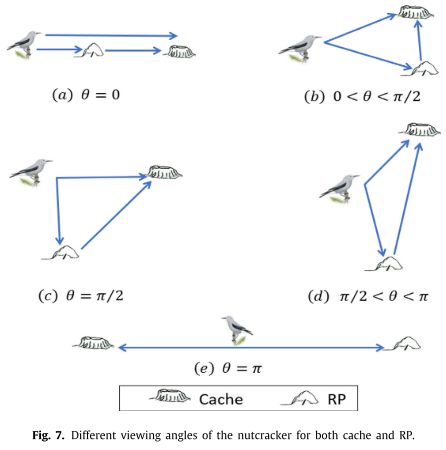
星鸦利用了一种层级记忆策略来恢复它们隐藏的食物,如果星鸦不能找到第一个RP储存的食物,那么它将通过第二个RP识别它。如果星鸦不能第二次检索它的缓存,那么它将使用第三个引用。第一个RP是通过更新相邻区域内的当前位置来找到星鸦周围隐藏的缓存:
R P → i , k t = X ⃗ i t + α ⋅ cos ( θ ) ⋅ ( ( X ⃗ A t − X ⃗ B t ) ) , k = 1 (5) \overrightarrow{RP}_{i,k}^t=\vec{X}_i^t+\alpha\cdot\cos{(\theta)}\cdot\left(\left(\vec{X}_A^t-\vec{X}_B^t\right)\right),k=1\tag{5} RPi,kt=Xit+α⋅cos(θ)⋅((XAt−XBt)),k=1(5)
探索不同的区域寻找隐藏的宝藏,第二个RP表述为:
R P → i , k t = X ⃗ i t + α ⋅ cos ( θ ) ⋅ ( ( U ⃗ − L ⃗ ) ⋅ τ 3 + L ⃗ ) ⋅ U → 2 , k = 2 U → 1 = { 1 r 2 → < P τ p 0 o t h e r w i s e (6) \begin{aligned}&\overrightarrow{RP}_{i,k}^{t}=\vec{X}_{i}^{t}+\alpha\cdot\cos{(\theta)}\cdot\left(\left(\vec{U}-\vec{L}\right)\cdot\tau_{3}+\vec{L}\right)\cdot\overrightarrow{U}_{2},k=2\\&\overrightarrow{U}_{1}=\begin{cases}1&\overrightarrow{r_{2}}<P_{\tau p}\\0&otherwise\end{cases}\end{aligned}\tag{6} RPi,kt=Xit+α⋅cos(θ)⋅((U−L)⋅τ3+L)⋅U2,k=2U1={10r2<Pτpotherwise(6)
星鸦在三维空间中有三个不同的位置,一个缓存有三个不同的RP位置:
R P → i , 1 t = { X ⃗ i t + α ⋅ cos ( θ ) ⋅ ( ( X ⃗ A t − X ⃗ B t ) ) + α ⋅ R P , i f θ = π / 2 X ⃗ i t + α ⋅ cos ( θ ) ⋅ ( ( X ⃗ A t − X ⃗ B t ) ) , o t h e r w i s e (7) \overrightarrow{RP}_{i,1}^{t}=\begin{cases}\vec{X}_{i}^{t}+\alpha\cdot\cos\left(\theta\right)\cdot\left(\left(\vec{X}_{A}^{t}-\vec{X}_{B}^{t}\right)\right)+\alpha\cdot RP,&if \theta=\pi/2\\\vec{X}_{i}^{t}+\alpha\cdot\cos\left(\theta\right)\cdot\left(\left(\vec{X}_{A}^{t}-\vec{X}_{B}^{t}\right)\right),&other wise\end{cases}\tag{7} RPi,1t=⎩ ⎨ ⎧Xit+α⋅cos(θ)⋅((XAt−XBt))+α⋅RP,Xit+α⋅cos(θ)⋅((XAt−XBt)),ifθ=π/2otherwise(7)
R P → i , 2 t = { X ⃗ i t + ( α ⋅ cos ( θ ) ⋅ ( ( U ⃗ − L ⃗ ) ⋅ τ 3 + L ⃗ ) + α ⋅ R P ) ⋅ U → 2 , i f θ = π / 2 X ⃗ i t + α ⋅ cos ( θ ) ⋅ ( ( U ⃗ − L ⃗ ) ⋅ τ 3 + L ⃗ ) ⋅ U → 2 , o t h e r w i s e (8) \overrightarrow{RP}_{i,2}^{t}=\begin{cases}\vec{X}_{i}^{t}+\left(\alpha\cdot\cos\left(\theta\right)\cdot\left(\left(\vec{U}-\vec{L}\right)\cdot\tau_{3}+\vec{L}\right)+\alpha\cdot RP\right)\cdot\overrightarrow{U}_{2}, if \theta=\pi/2\\\vec{X}_{i}^{t}+\alpha\cdot\cos(\theta)\cdot\left(\left(\vec{U}-\vec{L}\right)\cdot\tau_{3}+\vec{L}\right)\cdot\overrightarrow{U}_{2},&other wise\end{cases}\tag{8} RPi,2t=⎩ ⎨ ⎧Xit+(α⋅cos(θ)⋅((U−L)⋅τ3+L)+α⋅RP)⋅U2,ifθ=π/2Xit+α⋅cos(θ)⋅((U−L)⋅τ3+L)⋅U2,otherwise(8)
α确保NOA定期收敛,允许胡桃夹子在下一代中改进其RP选择:
α = { ( 1 − t T m a x ) 2 t T m a x , i f r 1 > r 2 ( t T m a x ) 2 t , o t h e r w i s e (9) \alpha=\begin{cases}\left(1-\frac t{T_{max}}\right)^{2\frac t{T_{max}}},&if r_1>r_2\\\\\left(\frac t{T_{max}}\right)^{\frac2t},&otherwise&\end{cases}\tag{9} α=⎩ ⎨ ⎧(1−Tmaxt)2Tmaxt,(Tmaxt)t2,ifr1>r2otherwise(9)
随着每次迭代,算法将以适当的rp探索和利用缓存周围的区域,以避免陷入局部最小值:
X ⃗ i t + 1 = { X ⃗ i t , i f f ( X ⃗ i t ) < i f ( R P ⃗ i , 1 t ) R P → i , 1 t , o t h e r w i s e (10) \vec{X}_i^{t+1}=\begin{cases}\vec{X}_i^t,&\quad if f\left(\vec{X}_i^t\right)<if (\vec{RP}_{i,1}^t)\\\overrightarrow{RP}_{i,1}^t,&\quad other wise\end{cases}\tag{10} Xit+1=⎩ ⎨ ⎧Xit,RPi,1t,iff(Xit)<if(RPi,1t)otherwise(10)
恢复阶段:开发阶段2
星鸦在寻找它的食物时可能存在两种可能。第一,星鸦可以使用第一个RP记住缓存的位置。第二,该食物不存在:
X i , j t + 1 = { X i , j t , i f τ 3 < τ 4 X i , j t + r 1 ⋅ ( X b e s t , j t − X i , j t ) + r 2 ⋅ ( R P → i , 1 t − X C , j t ) , o t h e r w i s e (11) X_{i,j}^{t+1}=\begin{cases}X_{i,j}^{t},&if \tau_{3}<\tau_{4}\\X_{i,j}^{t}+r_{1}\cdot\left(X_{best,j}^{t}-X_{i,j}^{t}\right)+r_{2}\cdot\left(\overrightarrow{RP}_{i,1}^{t}-X_{C,j}^{t}\right),&otherwise\end{cases}\tag{11} Xi,jt+1=⎩ ⎨ ⎧Xi,jt,Xi,jt+r1⋅(Xbest,jt−Xi,jt)+r2⋅(RPi,1t−XC,jt),ifτ3<τ4otherwise(11)
第二个RP进行更新:
X ⃗ i t + 1 = { X ⃗ i t , i f f ( X ⃗ i t ) < i f ( R P ⃗ i , 2 t ) R P → i , 2 t , o t h e r w i s e (12) \vec{X}_{i}^{t+1}=\begin{cases}\vec{X}_{i}^{t},&if f\left(\vec{X}_{i}^{t}\right)<if (\vec{RP}_{i,2}^{t})\\\overrightarrow{RP}_{i,2}^{t},&otherwise\end{cases}\tag{12} Xit+1=⎩ ⎨ ⎧Xit,RPi,2t,iff(Xit)<if(RPi,2t)otherwise(12)
假设星鸦使用第二个RP找到它的缓存:
X i j t + 1 = { X i j t , i f τ 5 < τ 6 X i j t + r 1 ⋅ ( X b e s t , j t − X i j t ) + r 2 ⋅ ( R → P i , 2 t − X c j t ) , o t h e r w i s e (13) X_{ij}^{t+1}=\begin{cases}X_{ij}^t,&if \tau_5<\tau_6\\X_{ij}^t+r_1\cdot\left(X_{best,j}^t-X_{ij}^t\right)+r_2\cdot\left(\overrightarrow{R}P_{i,2}^t-X_{cj}^t\right),&otherwise\end{cases}\tag{13} Xijt+1={Xijt,Xijt+r1⋅(Xbest,jt−Xijt)+r2⋅(RPi,2t−Xcjt),ifτ5<τ6otherwise(13)
算法围绕涉及最优解的最合适区域加强局部搜索,总结为:
X ⃗ i t + 1 = { Eq.(13), if τ 7 < τ 8 Eq.(15), otherwise (14) \vec{X}_i^{t+1}=\begin{cases}\text{Eq.(13),}&\text{if} \tau_7<\tau_8\\[2ex]\text{Eq.(15),}&\text{otherwise}\end{cases}\tag{14} Xit+1=⎩ ⎨ ⎧Eq.(13),Eq.(15),ifτ7<τ8otherwise(14)
等式中的第一种情况表示记住隐藏存储的星鸦,而第二种情况表示不记住隐藏存储的星鸦。第一个rp和第二个rp的探索行为之间平衡:
X ⃗ i t + 1 = { Eq.(12), if f(Eq.(12))<f(Eq.(14)) Eq.(14), otherwise (15) \vec{X}_{i}^{t+1}=\begin{cases}\text{Eq.(12),}&\text{if f(Eq.(12))<f(Eq.(14))}\\\text{Eq.(14),}&\text{otherwise}\end{cases}\tag{15} Xit+1={Eq.(12),Eq.(14),if f(Eq.(12))<f(Eq.(14))otherwise(15)
缓存搜索阶段与回收阶段的交换按照下式进行,以保持勘探与开采的平衡:
X ⃗ i t + 1 = { E q . ( 16 ) , i f ϕ > P a 2 E q . ( 17 ) , o t h e r w i s e (16) \vec{X}_{i}^{t+1}=\begin{cases}\mathrm{Eq.} ( 16),\quad if \phi>P_{a_{2}}\\[2ex]\mathrm{Eq.} ( 17 ),\quad other wise\end{cases}\tag{16} Xit+1=⎩ ⎨ ⎧Eq.(16),ifϕ>Pa2Eq.(17),otherwise(16)

伪代码

3.结果展示
使用测试框架,测试NOA性能 一键run.m
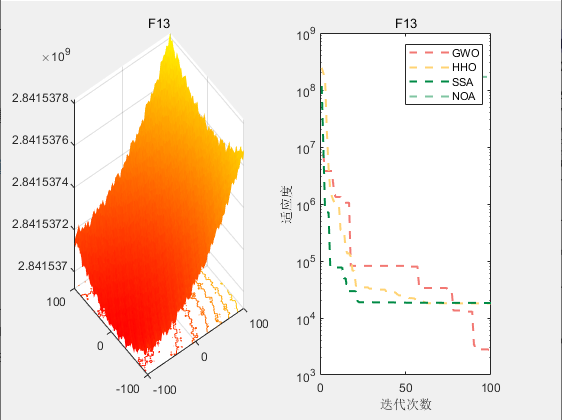
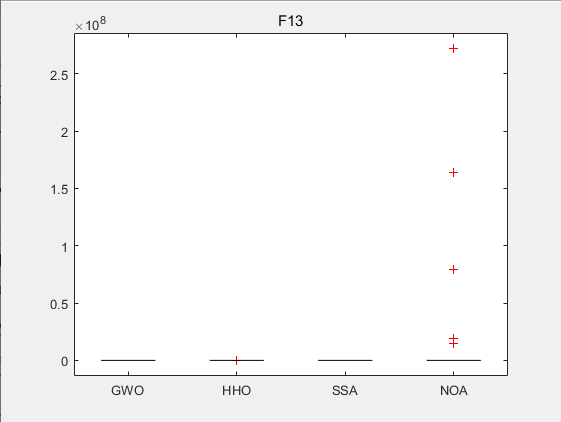
CEC2017-F13

4.参考文献
[1] Abdel-Basset M, Mohamed R, Jameel M, et al. Nutcracker optimizer: A novel nature-inspired metaheuristic algorithm for global optimization and engineering design problems[J]. Knowledge-Based Systems, 2023, 262: 110248.