文章目录
一、Zookeeper JavaAPI操作
1、Curator介绍
- Curator是Apache Zookeeper的Java客户端。
- 常见的Zookeeper Java API:
- 原生Java API。
- ZkClient。
- Curator。
- Curator项目目标是简化Zookeeper客户端的使用。
- Curator最初是Netfix研发的,后来捐献了Apache基金会,目前是Apache的顶级项目。
- 官网:https://curator.apache.org/docs/about
2、创建、查询、修改、删除节点
public class CuratorTest {private CuratorFramework client;@Beforepublic void init() {// 1、方式一RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient("localhost:2181", 60 * 1000, 15 * 1000, retryPolicy);// 2、方式二CuratorFramework client = CuratorFrameworkFactory.builder().connectString("localhost:2181").sessionTimeoutMs(60 * 1000).connectionTimeoutMs(15 * 1000).retryPolicy(retryPolicy).namespace("test").build();// 开启连接client.start();this.client = client;}/*** 1、基本创建:client.create().forPath("/app1")* 2、创建节点,带有数据:client.create().forPath("/app1", data)* 3、设置节点的类型: client.create().withMode(CreateMode.EPHEMERAL).forPath("/app1")* 4、创建多级节点: client.create().creatingParentsIfNeeded().forPath("/app1/app2")*/@Testpublic void testCreate() {// 1、基本创建// 如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储try {String path = client.create().forPath("/app1");System.out.println(path);} catch (Exception e) {throw new RuntimeException(e);}}/*** 查询节点:* 1、查询数据:get* 2、查询子节点: ls* 3、查询节点状态信息: ls -s*/@Testpublic void testQueryData() {// 1、查询数据: gettry {byte[] data = client.getData().forPath("/app1");System.out.println(new String(data));} catch (Exception e) {throw new RuntimeException(e);}}@Testpublic void testQueryChildren() {// 查询子节点: lstry {List<String> stringList = client.getChildren().forPath("/");System.out.println(stringList);} catch (Exception e) {throw new RuntimeException(e);}}@Testpublic void testQueryState() {// 查询节点状态信息: ls -sStat status = new Stat();try {client.getData().storingStatIn(status).forPath("/app1");System.out.println(status);} catch (Exception e) {throw new RuntimeException(e);}}/*** 修改数据:* 1、修改数据。* 2、根据版本修改*/@Testpublic void testSet() {// 修改数据try {client.setData().forPath("/app1", "haha".getBytes());} catch (Exception e) {throw new RuntimeException(e);}}@Testpublic void testSetForVersion() throws Exception {// 根据版本修改Stat stat = new Stat();// 查询节点状态信息: ls -sclient.getData().storingStatIn(stat).forPath("/app1");int version = stat.getVersion();client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());}/*** 删除节点:delete、deleteall* 1、删除单个节点* 2、删除带有子节点的节点* 3、必须成功的删除: 为了防止网络抖动。本质就是重试。* 4、回调*/@Testpublic void testSingleDelete() throws Exception {// 1、删除单个节点client.delete().forPath("/app1");// 2、删除带有子节点的节点client.delete().deletingChildrenIfNeeded().forPath("/app1");// 3、必须成功删除client.delete().guaranteed().forPath("/app1");//4、回调client.delete().guaranteed().inBackground((client, event) -> {System.out.println("我被删除了");System.out.println(event);}).forPath("/app1");}@Afterpublic void close() {if (client != null) {client.close();}}
}
3、Watch事件监听
- Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,Zookeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要性。
- Zookeeper中引入了Watcher机制来实现了发布/订阅功能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
- Zookeeper原生支持通过注册Watcher来进行事件监听,但是其使用并不是特别方便需要开发人员自己反复注册Watcher,比较繁琐。
- Curator引入了Cache来实现对Zookeeper服务端事件的监听。
- Zookeeper提供了三种Watcher:
- NodeCache:只是监听某一个特定的节点。
- PathChildrenCache:监控一个ZNode的子节点。
- TreeCache:可以监控整个树上所有节点,类似于PathChildrenCache和NodeCache的组合。
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.*;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;public class CuratorWatcherTest {private CuratorFramework client;@Beforepublic void init() {// 1、方式一RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient("localhost:2181", 60 * 1000, 15 * 1000, retryPolicy);// 2、方式二CuratorFramework client = CuratorFrameworkFactory.builder().connectString("localhost:2181").sessionTimeoutMs(60 * 1000).connectionTimeoutMs(15 * 1000).retryPolicy(retryPolicy).namespace("test").build();// 开启连接client.start();this.client = client;}@Testpublic void testPathChildrenCache() {// 1、创建监听对象PathChildrenCache pathChildrenCache = new PathChildrenCache(client, "/app2", true);// 2、绑定监听器pathChildrenCache.getListenable().addListener((curatorFramework, event) -> {System.out.println("- 子节点变化了 -");System.out.println(event);// 监听子节点的数据变更,并且拿到变更后的数据// 获取类型PathChildrenCacheEvent.Type type = event.getType();// 判断类型是否是updateif (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) {System.out.println("数据变了");byte[] data = event.getData().getData();System.out.println(new String(data));}});}@Testpublic void testTreeCache() {// 创建监听器TreeCache treeCache = new TreeCache(client, "/app2");// 2、注册监听器treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework curatorFramework, TreeCacheEvent event) throws Exception {System.out.println("节点变化了");System.out.println(event);}});}@Afterpublic void close() {if (client != null) {client.close();}}}二、Zookeeper分布式锁原理
1、 分布式锁
- 在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
- 但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程间的锁解决同步问题。
- 那么就需要一种更加高级的锁机制,来处理这种跨机器的进程之间的数据同步问题–分布式锁。
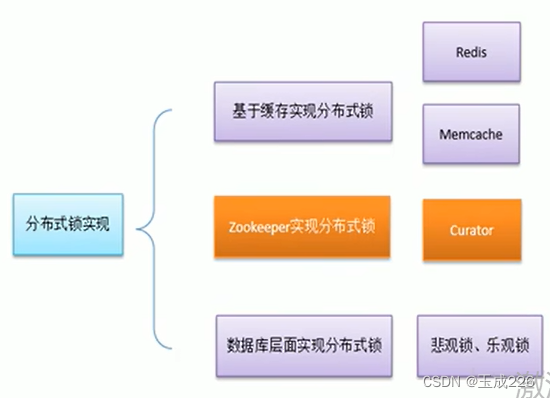
2、Zookeeper分布式锁
(1)原理
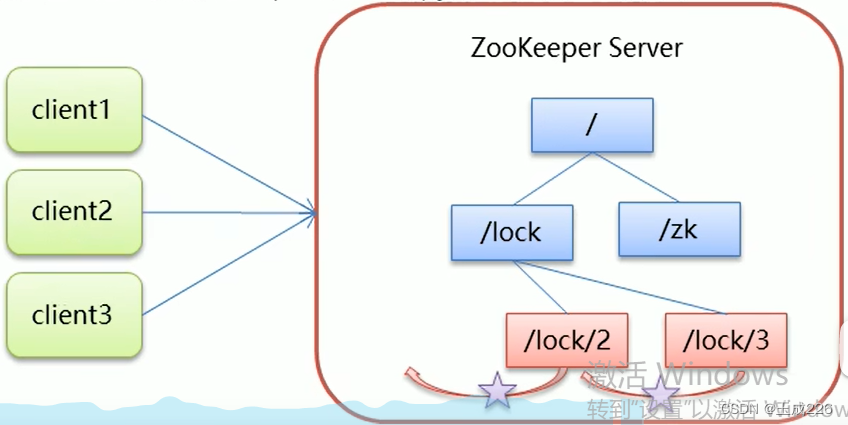
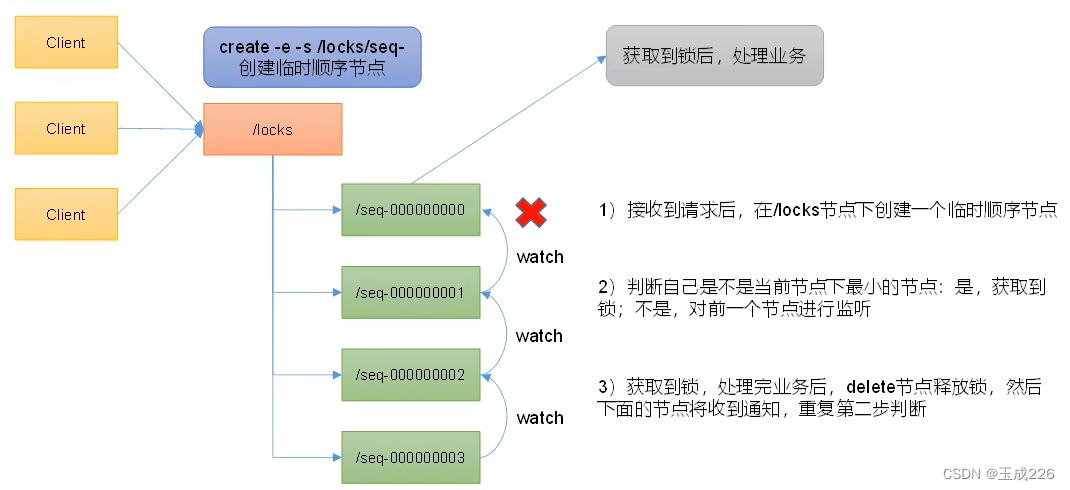
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除节点。
- 客户端获取锁时,在lock节点下创建临时顺序节点。
- 然后获取lock下面所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁,使用完锁后,删除该节点。
- 如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
- 如果发现比自己小的那个节点被删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序列号最小的,如果是则获取锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
(2)Curator实现分布式锁API
在Curator中有五种锁方案: