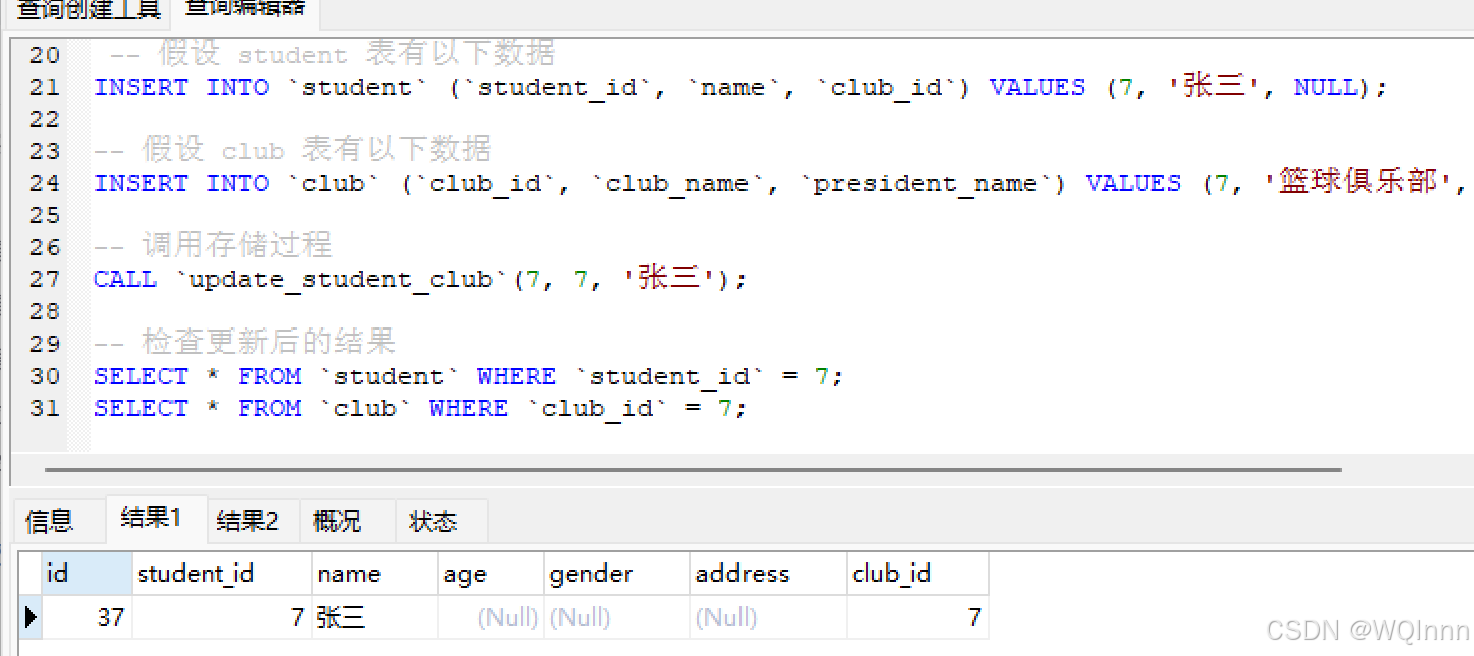
1.整体collection体系图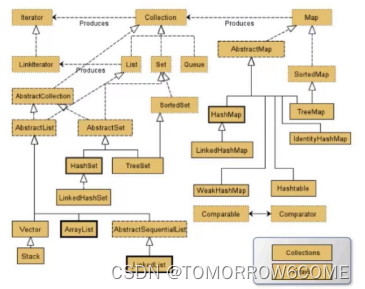
2.集合List和Set

(1)ArrayList和LinkedList区别
我们知道,通常情况下,ArrayList和LinkedList的区别有以下几点:
1. ArrayList是实现了基于动态数组的数据结构(可以实现扩容,实现方式是建立一个新的数组,再覆盖掉原先的数组;因为ArrayList的创建就是新建一个数组),而LinkedList是基于链表的数据结构;(LinkedList底层维护了一个双向链表,由于其是双向链表所以其对元素的增,删效率要比ArrayList要好,也因是链表,其没有扩容机制,就是一直在前面和后面新增就好(链表的头插法和尾插法))
2. 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;
对于插入跟删除,LinkedList的时间更长了, 现在大概知道了,插入位置的选取对LinkedList有很大的影响,
因为LinkedList在插入时需要向移动指针到指定节点, 才能开始插入,,一旦要插入的位置比较远,LinkedList就需要一步一步的移动指针, 直到移动到插入位置,这就解释了, 为什么节点值越大, 时间越长, 因为指针移动需要时间。
而ArrayList是数组的数据结构, 可以根据下标直接获得位置, 这就省去了查找特定节点的时间,所以对ArrayList的影响不是特别大。
压测:
主要有两个因素决定他们的效率,插入的数据量和插入的位置。我们可以在程序里改变这两个因素来测试它们的效率。当数据量较小时,测试程序中,大约小于30的时候,两者效率差不多,没有显著区别;当数据量较大时,大约在容量的1/10处开始,LinkedList的效率就开始没有ArrayList效率高了,特别到一半以及后半的位置插入时 ,LinkedList效率明显要低于ArrayList,而且数据量越大,越明显。
(2)Hashset与TreeSet的区别
Hashset的底层是HashMap.在调用add方法时,将元素以键的形式放入到HashMap里,同时给他对应一个值。
TreeSet是NavigableMap的马甲。使用add将元素以键的形式保存到TreeMap的key里。而它的值就是final Object PRESENT.NavigableMap是个interface。是由TreeMap实现的。TreeSet是TreeMap的马甲。使用compareto进行自然排序的。关键词:排序
3.集合之Map

Map里的key是通过set实现的,不可重复,唯一。Value是通过collection实现的,可重复的
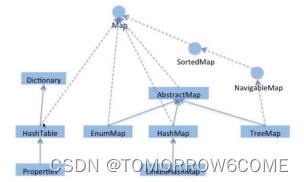
(1)HashMap与HashTable与conccurentHashMap的区别
hashmap的数组长度默认是16.
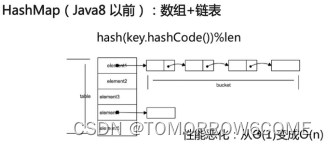
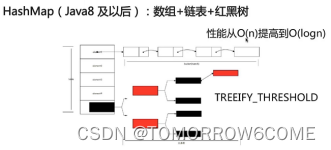
分析:
使用TREEIFY_THRESHOLD来控制是否将链表转化为红黑树来存储。
Hash值相等的键值对以链表形式存储,如果链表的大小超过TREEIFY_THRESHOLD(默认是8),就会被改造成红黑树。低于UNTREEIFY_THRESHOLD(默认为6),又会被转化成链表。为了更高的性能。HashMap使用lazyLoad的原则,在首次使用的时候才会被初始化。

碰撞:意味着hash值相等。


Hashtable:
早期java类库提供的哈希表的实现。
线程安全:涉及到修改HashTable的方法,使用synchronized修饰
串行化方式运行,性能较差。
conccurentHashMap:
分析:
如何优化Hashtable?
通过锁细粒度化,将锁拆解成多个锁进行优化。
早期的ConcurrentHashMap通过分段锁Segment实现。

当前的ConcurrentHashMap:CAS+synchronized使锁更细化。
数据结构采用数组+链表+红黑树。Synchronized只锁住当前链表或者红黑树的首节点,
只要hash不冲突,就不会产生并发。


总结: