1 关系型数据库ORM
SQLAlchemy 安装 pip install SQLAlchemy 优点: 易用 损耗小 可移植性强
1.1 环境整备
安装插件
pip install mysqlclient
创建数据库
create database db1;
创建数据表
create table user( id int(10), name varchar(20), email varchar(30) );
插入数据
insert into user(id,name,email) value(1, 'siheyuan', '2@2.com'); insert into user(id,name,email) value(2, 'lixina', '2@2.com'); insert into user(id,name,email) value(3, 'zhangfeo', '3@3.com'); insert into user(id,name,email) value(4, 'zhangliu', '4@4.com'); insert into user(id,name,email) value(5, 'lijiu', '5@5.com'); insert into user(id,name,email) value(6, 'daming', '6@6.com'); insert into user(id,name,email) value(7, 'duodou', '7@7.com'); insert into user(id,name,email) value(8, 'jiangshi', '8@8.com');
1.2 代码案例
新建mysqlconn.py
#!/usr/bin/env python # 导入必要的库
from sqlalchemy import create_engine, text # 导入SQLAlchemy的create_engine和text方法 # 定义数据库连接URL
db_url = 'mysql://root:123456@192.168.135.128:3306/db1' # 使用root用户,密码为123456,连接到IP地址为192.168.135.128,端口为3306的MySQL服务器上的db1数据库 # 创建数据库引擎
engine = create_engine(db_url) # 使用定义的URL创建数据库引擎 # 连接数据库
conn = engine.connect() # 使用引擎连接到数据库 # 定义SQL查询语句
sql = text("select * from user") # 使用text对象定义了一个查询user表中所有数据的SQL语句 # 执行SQL查询
result = conn.execute(sql) # 执行定义的SQL查询,返回查询结果 # 遍历查询结果并打印
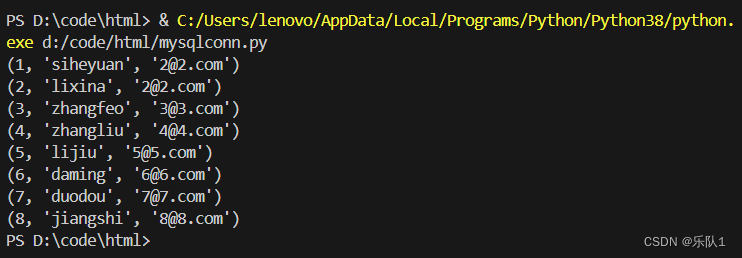
for row in result: print(row) # 遍历查询结果的每一行,并打印出来
效果
2 对象关系映射
把python类映射到数据库表中 declarative_base
2.1 代码案例
新建mysql_create_table.py
#!/usr/bin/env python # 导入SQLAlchemy库 from sqlalchemy import * # 导入SQLAlchemy的declarative_base,用于创建基类 from sqlalchemy.ext.declarative import declarative_base # 导入SQLAlchemy的sessionmaker,用于创建会话类 from sqlalchemy.orm import sessionmaker # 定义数据库连接URL db_url = 'mysql://root:123456@192.168.135.128:3306/db1' # 使用数据库连接URL创建数据库引擎 engine = create_engine(db_url) # 使用declarative_base创建基类 Base = declarative_base() # 定义User类,继承自Base基类 class User(Base): # 定义表名为'user' __tablename__ = 'user' # 定义id列,为整数类型,且为主键 id = Column(Integer, primary_key=True) # 定义name列,为最大长度为20的字符串类型 name = Column(String(20)) # 定义email列,为最大长度为50的字符串类型 email = Column(String(50)) # 定义__repr__方法,用于返回User对象的字符串表示形式 def __repr__(self): # 返回User对象的name属性值的字符串表示 return "<User(name=%s)>" % self.name # 使用sessionmaker创建会话类,并绑定到数据库引擎 Session = sessionmaker(bind=engine) # 创建会话对象 session = Session() # 执行查询操作,查询User表中的所有记录,并打印结果 # 注意:这里使用了print函数直接打印查询结果,而不是注释掉的session.query(User).all() print(session.query(User).all())
效果

3 创建数据库表
新建mysql_create_table.py
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
db_url = 'mysql://root:123456@192.168.135.131:3306/db1'
engine = create_engine(db_url)
#基类,用户声明所有表的基础
Base = declarative_base()
class Course(Base):__tablename__ = 'course'id = Column(Integer,primary_key=true)name = Column(String(40),nullable=False)instrutor = Column(String(100),nullable=False)start_date = Column(Date,nullable=False)end_date = Column(Date,nullable=False)def __repr__(self):return f"<Course(name='{self.name}',instructor='{self.instrutor}')>"
# 调用Base的metadata的create_all方法,使用前面定义的引擎创建所有定义的表
Base.metadata.create_all(engine)
from sqlalchemy import * # 导入SQLAlchemy库中的所有内容 from sqlalchemy.ext.declarative import declarative_base # 导入用于声明ORM模型的基类方法 from sqlalchemy.orm import sessionmaker # 导入用于创建会话的工厂函数 db_url = 'mysql://root:123456@192.168.135.128:3306/db1' # 定义数据库连接URL engine = create_engine(db_url) # 使用定义的URL创建数据库引擎 # 声明一个基类,用于后续声明所有表的ORM模型
Base = declarative_base() class Course(Base): # 定义一个名为Course的ORM模型,继承自Base基类 __tablename__ = 'course' # 指定这个ORM模型对应的数据库表名为'course' id = Column(Integer, primary_key=True) # 定义id列,类型为整数,为主键 name = Column(String(40), nullable=False) # 定义name列,类型为长度最多为40的字符串,不可为空 # 注意:这里应该是instructor,而不是instrutor instructor = Column(String(100), nullable=False) # 定义instructor列,类型为长度最多为100的字符串,不可为空 start_date = Column(Date, nullable=False) # 定义start_date列,类型为日期,不可为空 end_date = Column(Date, nullable=False) # 定义end_date列,类型为日期,不可为空 def __repr__(self): # 定义对象的字符串表示方法 return f"<Course(name='{self.name}',instructor='{self.instructor}')>" # 返回对象的字符串表示,包含name和instructor属性 # 调用Base的metadata的create_all方法,使用前面定义的引擎创建所有定义的表
Base.metadata.create_all(engine)
效果
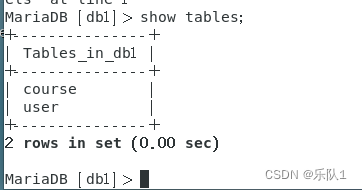
4 增删改查
新建mysql_CRUD.py
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
db_url = 'mysql://root:123456@192.168.135.128:3306/db1'
engine = create_engine(db_url)
#基类,用户声明所有表的基础
Base = declarative_base()
class Course(Base):__tablename__ = 'course'id = Column(Integer,primary_key=true)name = Column(String(40),nullable=False)instrutor = Column(String(100),nullable=False)start_date = Column(Date,nullable=False)end_date = Column(Date,nullable=False)def __repr__(self):return f"<Course(name='{self.name}',instructor='{self.instrutor}')>"
# Base.metadata.create_all(engine)
#增
# new_course = Course(name="py",instrutor="wuyue",start_date='2023-08-05',end_date='2024-08-05')
# Session = sessionmaker(bind=engine)
# session = Session()
# session.add(new_course)
# #提交会话
# session.commit()
# #关闭会话
# session.close()
#查
# Session = sessionmaker(bind=engine)
# session = Session()
# courses = session.query(Course).all()
# for c in courses:
# print(c)
#改
# Session = sessionmaker(bind=engine)
# session = Session()
# course = session.query(Course).filter_by(name="py").first()
# course.instrutor = "C++"
# #提交会话
# session.commit()
# #关闭会话
# session.close()
#删
# Session = sessionmaker(bind=engine)
# session = Session()
# course = session.query(Course).filter_by(name="py").first()
# session.delete(course)
# # #提交会话
# session.commit()
# #关闭会话
# session.close()
效果
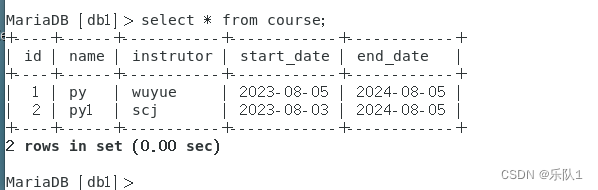
5 关系数据库的对应关系
数据库关系: 1-1:两张表中的数据是一一对应 1-M:比如coures-》实验 M-M:1个课程可以有多个标签,一个标签,也可以关联多个课程
1-1和1-M主要通过外键进行创建 M-M主要通过创建中间表,用于记录关系
新建mysqlguanxi.py
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker,relationshipdb_url = 'mysql://root:123456@192.168.135.128:3306/db1'
engine = create_engine(db_url)
#基类,用户声明所有表的基础
Base = declarative_base()#1-1
# class Course(Base):
# __tablename__ = 'course'
# id = Column(Integer,primary_key=true)
# course_name = Column(String(40),nullable=False)
# def __repr__(self):
# return f"<Course(name='{self.name}',instructor='{self.instrutor}')>"# class Experiment(Base):
# __tablename__ = 'expriment'
# id = Column(Integer,primary_key=true)
# exp_id = Column(Integer,ForeignKey('course.id'),unique=true,nullable=False)# course = relationship("Course",back_populates="expriment")# Base.metadata.create_all(engine)#1-M
# class Course(Base):
# __tablename__ = 'course'
# id = Column(Integer,primary_key=true)
# course_name = Column(String(40),nullable=False)
# def __repr__(self):
# return f"<Course(name='{self.name}',instructor='{self.instrutor}')>"# class Experiment(Base):
# __tablename__ = 'expriment'
# id = Column(Integer,primary_key=true)
# course_id = Column(Integer,ForeignKey('course.id'))# course = relationship("Couses",back_populates="course")# Course.expriments = relationship("Experiment",back_populates="course")
# Base.metadata.create_all(engine) #M-M#创建中间表,用于记录课程和标签的管理关系
course_tag_association = Table('course_tag',Base.metadata,Column('couse_id',Integer,ForeignKey('course.id')),Column('tag_id',Integer,ForeignKey('tag.id'))
)class Course(Base):__tablename__ = 'course'id = Column(Integer,primary_key=true)course_name = Column(String(40),nullable=False)tags = relationship("Tag",secondary=course_tag_association,back_populates="courses")class Tag(Base):__tablename__ = 'tag'id = Column(Integer,primary_key=true)tag_name = Column(String(40),nullable=False)courses = relationship("Course",secondary=course_tag_association,back_populates="tags")# class Course(Base):
# tags = relationship("Tag",secondary=course_tag_association,back_populates="courses")
# class Tag(Base):
# courses = relationship("Course",secondary=course_tag_association,back_populates="tags") Base.metadata.create_all(engine)
效果
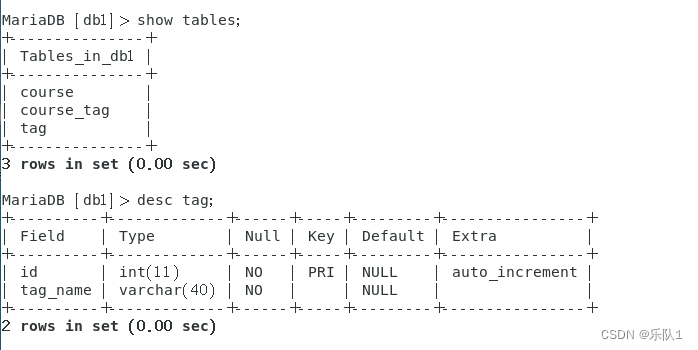
6 NOSQL-Mongodb操纵
6.1 创建数据库
在 MongoDB 中,数据库通常会在插入数据的时候自动创建。但是,你也可以使用 use 命令来显式地切换到一个不存在的数据库,此时 MongoDB 会创建这个数据库。
use mydatabase
6.2 插入文档
插入文档到集合中,如果集合不存在,MongoDB 会自动创建它。
// 插入单个文档
db.mycollection.insertOne({name: "John", age: 30}) // 插入多个文档
db.mycollection.insertMany([ {name: "Alice", age: 25}, {name: "Bob", age: 35}
])
6.3 查询文档
查询文档是 MongoDB 中最常见的操作之一。
// 查询所有文档
db.mycollection.find() // 根据条件查询
db.mycollection.find({age: {$gte: 25, $lte: 30}}) // 查询并返回特定字段
db.mycollection.find({}, {name: 1, age: 1})
6.4 更新文档
更新集合中满足条件的文档。
// 更新单个文档
db.mycollection.updateOne({name: "John"}, {$set: {age: 31}}) // 更新多个文档
db.mycollection.updateMany({age: {$lt: 30}}, {$set: {status: "young"}})
6.5 删除文档
删除集合中满足条件的文档。
// 删除单个文档
db.mycollection.deleteOne({name: "John"}) // 删除多个文档
db.mycollection.deleteMany({age: {$gt: 30}})
6.6 创建索引
为了提高查询性能,可以在字段上创建索引。
// 为 name 字段创建升序索引
db.mycollection.createIndex({name: 1}) // 为 name 字段创建降序索引
db.mycollection.createIndex({name: -1})
6.7 聚合操作
使用聚合框架对集合中的数据进行复杂的数据分析和转换。
// 计算 age 字段的平均值
db.mycollection.aggregate([ { $group: { _id: null, averageAge: {$avg: "$age"} } }
])
7python操作Mongodb
新建mongodbtest.py
#!/usr/bin/env pythonfrom http import client
from pymongo import MongoClientclient = MongoClient("mongodb://192.168.135.128:27017")
db = client.mashibing#增
# user1 = {
# "name":"Nical",
# "age":18,
# "email":"4@4.com",
# "addr":["TW","HZ","GZ"]
# }
# db["user"].insert_one(user1)# user_list = [
# {
# "name":"89",
# "age":25,
# "email":"5@5.com",
# "addr":["DYD","SZ","DG"]},
# {
# "name":"CC",
# "age":24,
# "email":"6@6.com",
# "addr":["NX","CD","SH"]},
# {
# "name":"APT27",
# "age":80,
# "email":"7@7.com",
# "addr":["MD","MB","YD"]},
# ]
# db["user"].insert_many(user_list)#查
# users = db["user"].find()
# for u in users:
# print(u)#改
# db["user"].update_one({"name":"APT27"},{"$set":{"age":16}})#删
# db["user"].delete_one({"name":"APT27"})
8 python操作redis
#!/usr/bin/env pythonimport redisclient = redis.StrictRedis(host='192.168.135.128',port=6379) # print(client)#增 # key = "name" # value = "wuyue" # client.set(key,value)#查 # key = "name" # value = client.get(key) # print(value)#改 # key = "name" # new_value = "handsome wuyue" # client.set(key,new_value)#删 # key = "name" # client.delete(key)