去年底的时候,笔者写过,与其在RAG系统上雕花,可以重新思考一下,自己的业务场景是否非RAG不可吗?随着去年大模型的蓬勃发展,长度外推、更长的上下文模型,更厉害的中文底座大模型,都可以让整个系统的压力往生成部分上迁移。
后来笔者造了一个词,文档片段化。对于常规的pdf问答档问答,基本上都能使用单一的大模型覆盖到了。但是对于知识库,文档库的问答,似乎RAG还是必不可少的。但是如果生成模型能力更强了,那与其在思考如何去更好的解析文档结构,去划分块大小,不如放大维度,把更大粒度的文本,如文档,当作传统的块,可以省掉很多细碎的工作。
回归主题,RAG场景如何吃到大模型长上下文的红利?本文主要是分享新出的一个研究工作LongRAG,为了解决检索器和阅读器之间工作量不平衡的问题,文中提出了一个新的框架,称为 LongRAG,它包括一个“长检索器” (long retriever)和一个“长阅读器”(long reader - llm)。文档块变长很显然,long retriever应该如何设计才能保证召回效果(正确答案的块相比与短块包含了更多的噪声),这个是本文的核心内容。
LongRAG 将整个维基百科处理成4K-token的chunks,这比以前的chunk长度长了30倍。通过增加chunk大小,显著减少了总chunk数,从22M减少到600K。使用现有的长上下文大型语言模型(LLM)进行答案提取,在NQ数据集上,LongRAG将答案召回率@1从52%提高到71%,在HotpotQA数据集上,将答案召回率@2从47%提高到72%。LongRAG在不需要任何训练的情况下,取得了与经过微调的RAG模型相当的结果。
文章地址如下:
https://arxiv.org/html/2406.15319v1
框架对比图如下,相比于vanilla rag的模式(下图左),longrag采样更大的块大小(下图右),所以理论上上对long retriever上应该需要一些特别的操作。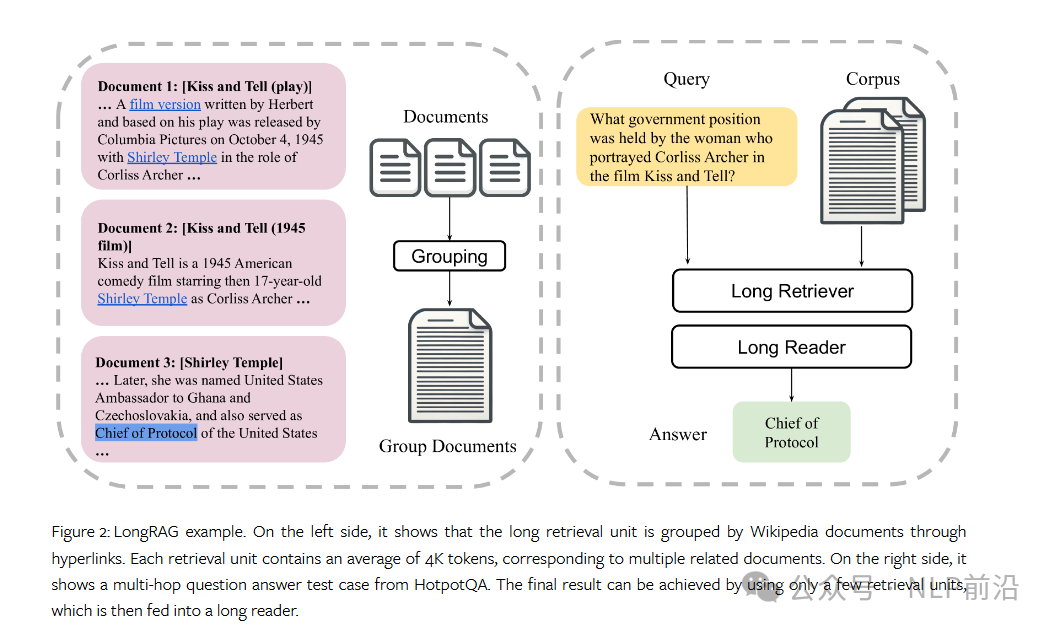
long retriever
传统的 RAG 中,检索块 g 通常是从文档 d 中分离出来的一小段段落,包含数百个标记。在这里,g 可能与整个文档甚至多个文档一样长,所以像传统那样算相似度可能就会有比较多的噪声干扰了。
因此首先能合并在一起的文档那不能不太相关联,不然召回之后作为模型的上下文噪声太大了。所以第一步需要先进行一个文档分组,这个算法类似于以前的那种流式聚类,还是什么聚类,名词记不太清了。文档是否相关使用的文档的连边,类似于那种有结构层级的知识库的大目录信息。细看就是如下图,很好理解:

然后计算相似度,传统那样query-passage计算比较有难度,所以使用近似,算query和passage中的小块的最大相似度,这个小块的粒度是个实验维度,可能是段落,也可能是文档级,也可能是上面的文档组。

到这里,核心的算法原理部分基本就结束了,对了,还有一个超参数,对于小的文档块召回为了提高召回率,一般用比较大的k。但是这里不行了,论文中设置的k为4到8。
核心的实验
下图为,使用段落、文档、文档组召回,真实答案的召回率(最右边一行),召回数量更多,召回率肯定更高,这个没什么好说的。召回块越大,需要达到接近的召回率的top k越少。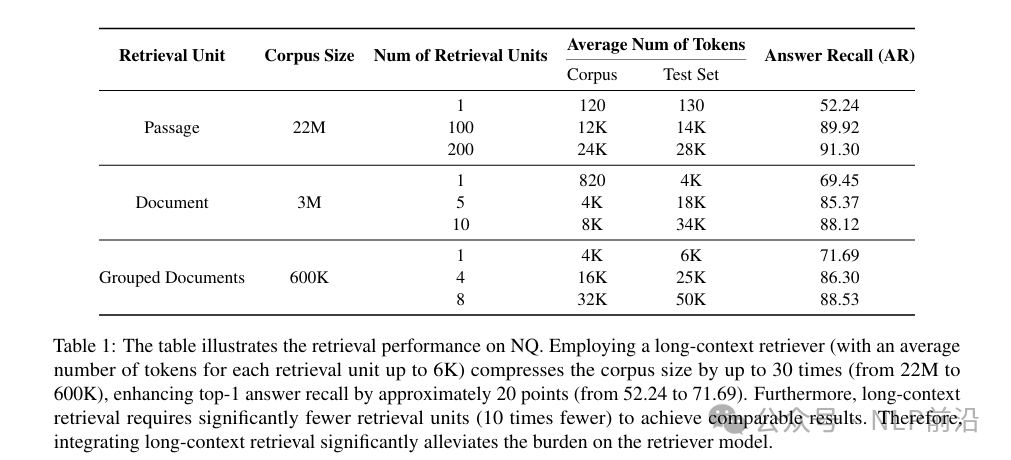
最后
整体的结论在前面提过了,很优秀。块长度变长,信息包含的更多,可能很难用一个向量来表达完整的内容,所以longrag的更多的探索会发生在如何有效且精准的找到包含答案片段的大块。本文中使用的近似策略以及文档组的构建都是在这个领域,目前很少见的探索尝试,并提供了一些实验论证。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。