Kafka集群搭建可视化指南
- 前言
- 准备工作
- 硬件要求
- 环境准备
- kafka集群的部署与配置
- 3.1 单节点部署与多节点集群搭建
- 单节点部署:
- 多节点集群搭建:
- 3.2 Broker配置与优化
- 3.3 Topic的创建与管理
- 3.4 安全性配置与权限管理
- knowstreaming
- docker-compose搭建
- 引入kafka集群
前言
想象一下,你正在开发一款新的实时数据分析工具,但在处理大规模数据流时遇到了瓶颈。你需要一种可靠、高效的数据传输系统来帮助你实现这一目标。在这个挑战中,Kafka就是你的得力助手。本文将为你揭开Kafka集群搭建的神秘面纱,让你轻松掌握数据处理的主动权。
准备工作
在搭建 Kafka 集群之前,首先需要准备好硬件和环境。以下是一些准备工作的关键步骤:
硬件要求
-
服务器资源:
- 确保每个服务器都有足够的 CPU 和内存资源来运行 Kafka 和 ZooKeeper。资源需求会根据你的实际使用情况而变化。
-
网络连接:
- 确保服务器之间有稳定的网络连接,这对 Kafka 集群的正常运行至关重要。
环境准备
-
Java 安装:
- 安装 Java Development Kit (JDK)。Kafka 是用 Java 编写的,因此需要在服务器上安装 Java。推荐使用 Java 8 或更高版本。
-
ZooKeeper 安装:
- Kafka 集群依赖于 ZooKeeper 进行协调和管理。在安装 Kafka 之前,确保 ZooKeeper 已经安装并正常运行。你可以参考 ZooKeeper 的官方文档安装和配置 ZooKeeper。
kafka_31">kafka集群的部署与配置
3.1 单节点部署与多节点集群搭建
单节点部署:
-
下载 Kafka:
- 访问 Kafka 的官方网站,下载最新版本的 Kafka。
-
解压 Kafka:
- 将下载的 Kafka 压缩文件解压到你选择的目录。
-
配置 Kafka:
- 进入 Kafka 目录,编辑
config/server.properties文件。 - 修改
broker.id为唯一的整数,表示单节点的 Broker ID。 - 根据需要修改其他配置,如监听端口、日志目录等。
- 进入 Kafka 目录,编辑
-
启动 Kafka 服务器:
-
在 Kafka 目录运行以下命令启动 Kafka 服务器:
bin/kafka-server-start.sh config/server.properties
-
多节点集群搭建:
-
配置不同的 Broker:
- 在每个 Kafka 服务器上,根据需要修改
config/server.properties中的broker.id和其他配置。 - 每个 Broker 的
broker.id必须是唯一的。
- 在每个 Kafka 服务器上,根据需要修改
-
配置 ZooKeeper:
-
在
config/server.properties中设置 ZooKeeper 连接信息,如:zookeeper.connect=zk1:2181,zk2:2181,zk3:2181其中,
zk1,zk2,zk3是你 ZooKeeper 集群的地址。
-
-
启动 Kafka 服务器:
-
在每个 Kafka 服务器上运行以下命令启动 Kafka 服务器:
bin/kafka-server-start.sh config/server.properties
-
3.2 Broker配置与优化
-
配置文件详解:
config/server.properties包含了 Kafka 服务器的配置。根据需要修改其中的参数,如listeners、log.dirs、num.partitions等。
-
JVM 配置:
- 配置 Kafka 的 JVM 参数,可通过
config/server.properties中的KAFKA_HEAP_OPTS来设置内存大小。
- 配置 Kafka 的 JVM 参数,可通过
-
硬盘与网络优化:
- 配置正确的硬盘路径 (
log.dirs),确保 Kafka 有足够的磁盘空间。 - 确保服务器之间的网络连接是高速和稳定的。
- 配置正确的硬盘路径 (
3.3 Topic的创建与管理
-
创建 Topic:
-
查看 Topic 列表:
-
查看 Topic 详细信息:
3.4 安全性配置与权限管理
-
SSL 配置:
- 配置 Kafka 使用 SSL 进行安全通信。编辑
config/server.properties文件,设置 SSL 配置项。
- 配置 Kafka 使用 SSL 进行安全通信。编辑
-
SASL 配置:
- 配置 Kafka 使用 SASL 进行身份验证。编辑
config/server.properties文件,设置 SASL 配置项。
- 配置 Kafka 使用 SASL 进行身份验证。编辑
-
ACL 权限管理:
- 配置 Kafka ACL(Access Control Lists)进行精确的权限管理。编辑
config/server.properties文件,设置 ACL 配置项。
- 配置 Kafka ACL(Access Control Lists)进行精确的权限管理。编辑
-
认证与授权:
- 配置 Kafka 使用其他认证和授权机制,如 Kerberos。编辑
config/server.properties文件,设置相应的配置项。
- 配置 Kafka 使用其他认证和授权机制,如 Kerberos。编辑
请注意,确保配置和安全性设置符合你的生产环境需求。详细的配置选项和更多的信息可以参考 Kafka 的官方文档。
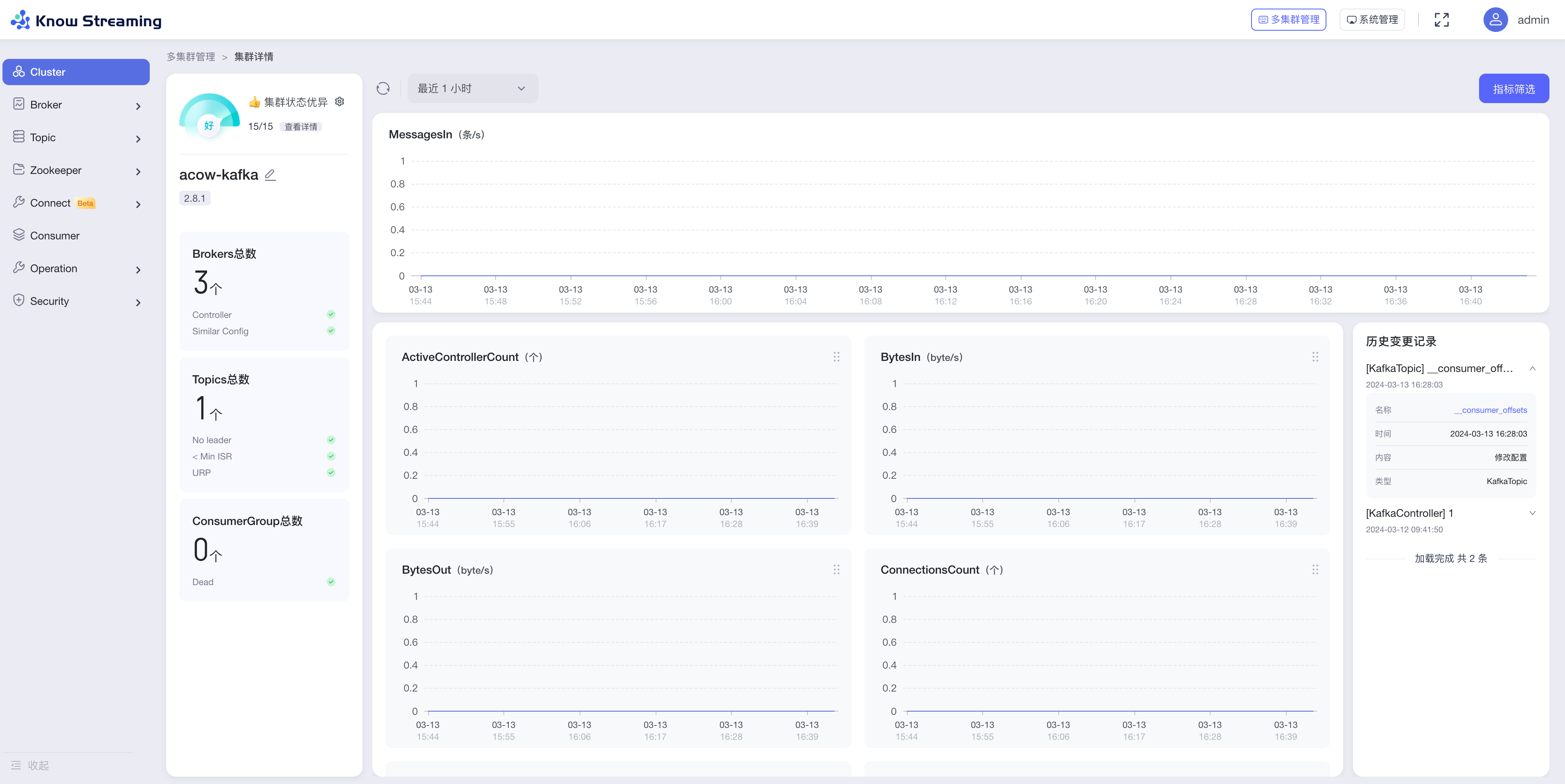
knowstreaming_138">knowstreaming
可视化官方文档
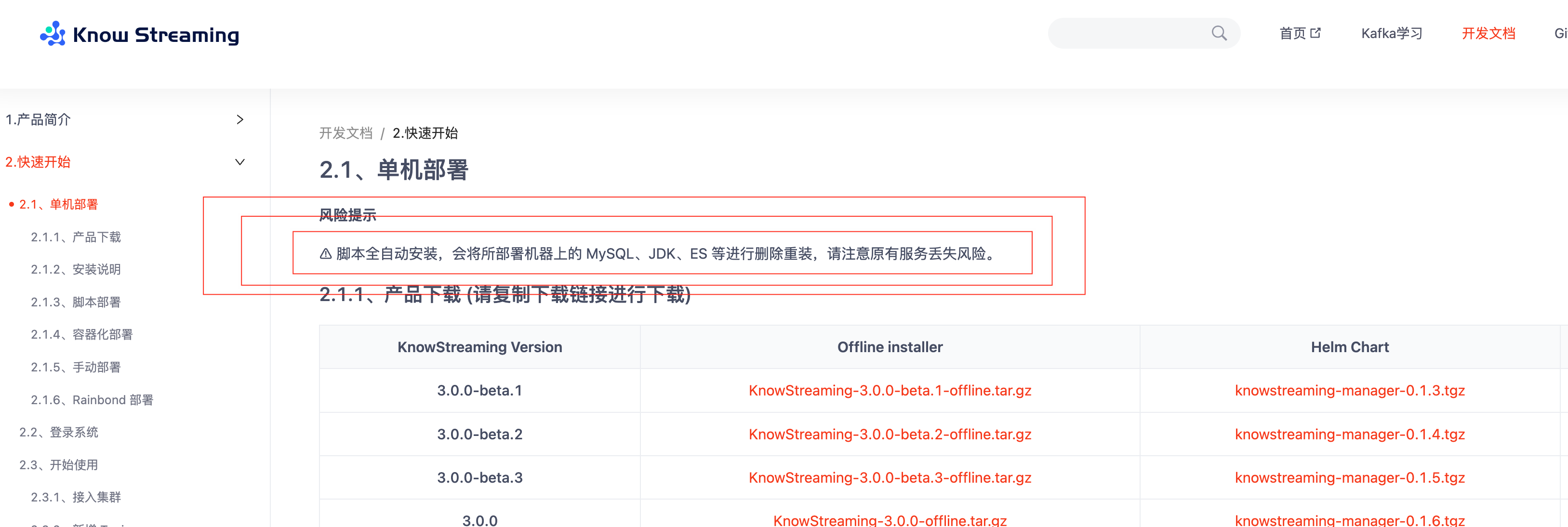
一定要注意脚本单机搭建风险提示,一定注意:
docker-compose搭建
docker-compose操作手册
这个是在官网的基础上做了部分修改
- ui端口映射改到了8081,这个最好先试一下你的端口是否被占用了
lsof -i tcp:port- es的镜像对于我的系统没有匹配的,也做了修改
- 官网默认没有挂载相关的日志以及数据,这里建议挂载一下。
- 启动之后如果出现登录网络异常,请稍微等一下再试,你可以看下manage的日志,还没有完全启动
- 首次启动之后init模块加载完成后会自动退出
version: '2'
services:# *不要调整knowstreaming-manager服务名称,ui中会用到knowstreaming-manager:image: knowstreaming/knowstreaming-manager:0.7.0container_name: knowstreaming-managerprivileged: truerestart: alwaysdepends_on:- elasticsearch-single- knowstreaming-mysqlexpose:- 80command:- /bin/sh- /ks-start.shenvironment:TZ: Asia/Shanghai# mysql服务地址SERVER_MYSQL_ADDRESS: knowstreaming-mysql:3306# mysql数据库名SERVER_MYSQL_DB: know_streaming# mysql用户名SERVER_MYSQL_USER: root# mysql用户密码SERVER_MYSQL_PASSWORD: admin2022_# es服务地址SERVER_ES_ADDRESS: elasticsearch-single:9200# 服务JVM参数JAVA_OPTS: -Xmx1g -Xms1g# 对于kafka中ADVERTISED_LISTENERS填写的hostname可以通过该方式完成# extra_hosts:# - "hostname:x.x.x.x"# 服务日志路径volumes:- /Users/xiaobo/DockerImage/knowstreaming/log:/logsknowstreaming-ui:image: knowstreaming/knowstreaming-ui:0.7.0container_name: knowstreaming-uirestart: alwaysports:- '8081:80'environment:TZ: Asia/Shanghaidepends_on:- knowstreaming-manager# extra_hosts:# - "hostname:x.x.x.x"elasticsearch-single:image: elasticsearch:7.16.3container_name: elasticsearch-singlerestart: alwaysexpose:- 9200- 9300# ports:# - '9200:9200'# - '9300:9300'environment:TZ: Asia/Shanghai# es的JVM参数ES_JAVA_OPTS: -Xms512m -Xmx512m# 单节点配置,多节点集群参考 https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docker.html#docker-compose-filediscovery.type: single-node# 数据持久化路径volumes:- /Users/xiaobo/DockerImage/knowstreaming/data:/usr/share/elasticsearch/data# es初始化服务,与manager使用同一镜像# 首次启动es需初始化模版和索引,后续会自动创建knowstreaming-init:image: knowstreaming/knowstreaming-manager:0.7.0container_name: knowstreaming-initdepends_on:- elasticsearch-singlecommand:- /bin/bash- /es_template_create.shenvironment:TZ: Asia/Shanghai# es服务地址SERVER_ES_ADDRESS: elasticsearch-single:9200knowstreaming-mysql:image: knowstreaming/knowstreaming-mysql:0.7.0container_name: knowstreaming-mysqlrestart: alwaysenvironment:TZ: Asia/Shanghai# root 用户密码MYSQL_ROOT_PASSWORD: admin2022_# 初始化时创建的数据库名称MYSQL_DATABASE: know_streaming# 通配所有host,可以访问远程MYSQL_ROOT_HOST: '%'expose:- 3306
# ports:
# - '3306:3306'
# 数据持久化路径volumes:- /Users/xiaobo/DockerImage/knowstreaming/mysql:/data/mysql
kafka_263">引入kafka集群