线程锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制 某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,只到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
创建锁 mutex = threading.Lock() 锁定 mutex.acquire() 解锁 mutex.release()
Queue线程
在线程中,访问一些全局变量,加锁是一个经常的过程。如果你是想把一些数据存储到某个队列中,那么Python内置了一个线程安全的模块叫做queue模块。Python中的queue模块中提供了同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue,LIFO(后入先出)队列LifoQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么都做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。

初始化Queue(maxsize):创建一个先进先出的队列。 empty():判断队列是否为空。 full():判断队列是否满了。 get():从队列中取最后一个数据。 put():将一个数据放到队列中。
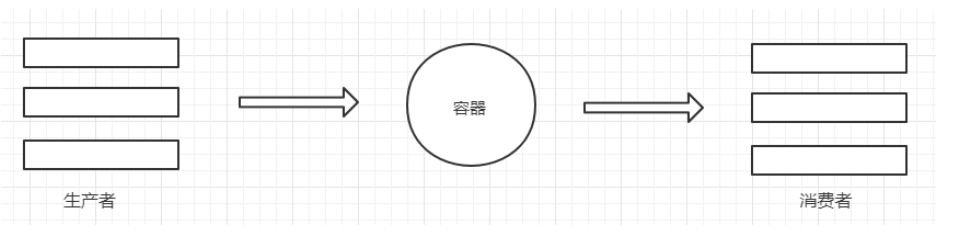
生产者与消费者模式
生产者和消费者模式是多线程开发中常见的一种模式。通过生产者和消费者模式,可以让代码达到高内聚低耦合的目标,线程管理更加方便,程序分工更加明确。 生产者的线程专门用来生产一些数据,然后存放到容器中(中间变量)。消费者在从这个中间的容器中取出数据进行消费
使用单线程下载表情包
import re
import requests
from urllib.request import urlretrieve
from lxml import etree
"""
将http://www.godoutu.com/face/hot/page/1.html下10页数据的表情包全部抓取
print(45*1801) 8w多条数据
图片数据 二进制
保存
with open wb模式
urllib
找到图片的路径 图片名字
"""
for i in range(1,2):
url = f'http://www.godoutu.com/face/hot/page/{i}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = response.text
# print(html)
# xpath对象
element = etree.HTML(html)
alldiv = element.xpath('//div[@class="ui segment imghover"]/div[@class="tagbqppdiv"]')
# print(alldiv,len(alldiv))
for j in alldiv:
everyhref = j.xpath('./a/img/@data-original')[0]
# print(everyhref)
title = j.xpath('./a/@title')[0] # 必须要是合法的
# print(title)
newtitle = re.sub('[\/:*?<>|]','',title)
# print(type(newtitle),type(everyhref))
# 保存 jpg gif
if str(everyhref).endswith('jpg'):
urlretrieve(everyhref,f'images/{newtitle}.jpg')
print(f'{newtitle}.jpg下载成功!')
else:
urlretrieve(everyhref, f'images/{newtitle}.gif')
print(f'{newtitle}.gif下载成功!')
使用生产者与消费者模式下载表情包
import threading
import time
import re
import requests
from lxml import etree
from queue import Queue
from urllib.request import urlretrieve# 生产者模型
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}def __init__(self, page_queue,img_queue ): # RuntimeError: thread.__init__() not called
# 在自写的类中的init中,先初始化Thread
threading.Thread.__init__(self) # 或则 super().__init__()
self.page_queue = page_queue
self.img_queue = img_queuedef run(self):
while True: # 让我们创建的三个生产者一直工作
if self.page_queue.empty():
break
else:
url = self.page_queue.get()
print(url)
# 获取到了url就可以去解析数据了
self.Parse_html(url)
def Parse_html(self,url):
# 上锁
lock.acquire()
# 发请求,获取响应
res = requests.get(url, headers=self.headers)
text = res.text
# 随机延迟
# time.sleep(random.random())
# 解析数据,拿真的图片地址
element = etree.HTML(text)# 将获取的所有img标签放到列表里面
alldiv = element.xpath('//div[@class="ui segment imghover"]/div[@class="tagbqppdiv"]')# 解锁
lock.release()
# 取出每一个图片的地址
for j in alldiv:
everyhref = j.xpath('./a/img/@data-original')[0]
print(everyhref)
title = j.xpath('./a/@title')[0] # 必须要是合法的
print(title)
newtitle = re.sub('[\/:*?<>|]', '', title)
# 将获取到的img_url和title数据存放在另一个队列种然后再交给消费者进行处理
self.img_queue.put((everyhref,newtitle)) # 用元组打包作为整体进行处理
# 检测我获取的数据量是否正确
print(self.img_queue.qsize())# 消费者模型
class Consumer(threading.Thread):
def __init__(self, img_queue): # RuntimeError: thread.__init__() not called
# 在自写的类中的init中,先初始化Thread
threading.Thread.__init__(self) # 或则 super().__init__()
self.img_queue = img_queuedef run(self):
while True: # 让我们创建的三个生产者一直工作
if self.img_queue.empty():
break
else:
img_data = self.img_queue.get() # 元组类型数据
# 解包
img_url, filename = img_data
# 下载操作
if str(img_url).endswith('jpg'):
urlretrieve(img_url, f'imagesss/{filename}.jpg')
print(f'{filename}.jpg下载成功!')
else:
urlretrieve(img_url, f'imagesss/{filename}.gif')
print(f'{filename}.gif下载成功!')# 程序主入口
if __name__ == '__main__':
# 创建一把锁
lock = threading.Lock()# 1 将所有的url存放在队列中
page_queue = Queue() # 创建一个队列 然后通过put方法存放进去# 创建一个存放数据的队列
img_queue = Queue() # 同样将这个队列通过init初始化传到生产者模型中for i in range(1, 11):
url = f'http://www.godoutu.com/face/hot/page/{i}.html'
page_queue.put(url)p_list = []
# 2 创建生产者对象 三个
for i in range(3):
t = Producer(page_queue,img_queue) # 将队列传给生产者处理 那再创建对象进行传参的过程中我们需要进行接收 init
t.start() # 开启多线程 执行的是run方法
p_list.append(t)for p in p_list:
p.join()# 创建三个消费者
for j in range(3):
t = Consumer(img_queue)
t.start()

![STM32F1学习笔记(五)—[定时器+HAL] PWM的输出](https://img-blog.csdnimg.cn/direct/a5af395d19fd4e61ba7a07c421841aa1.png)