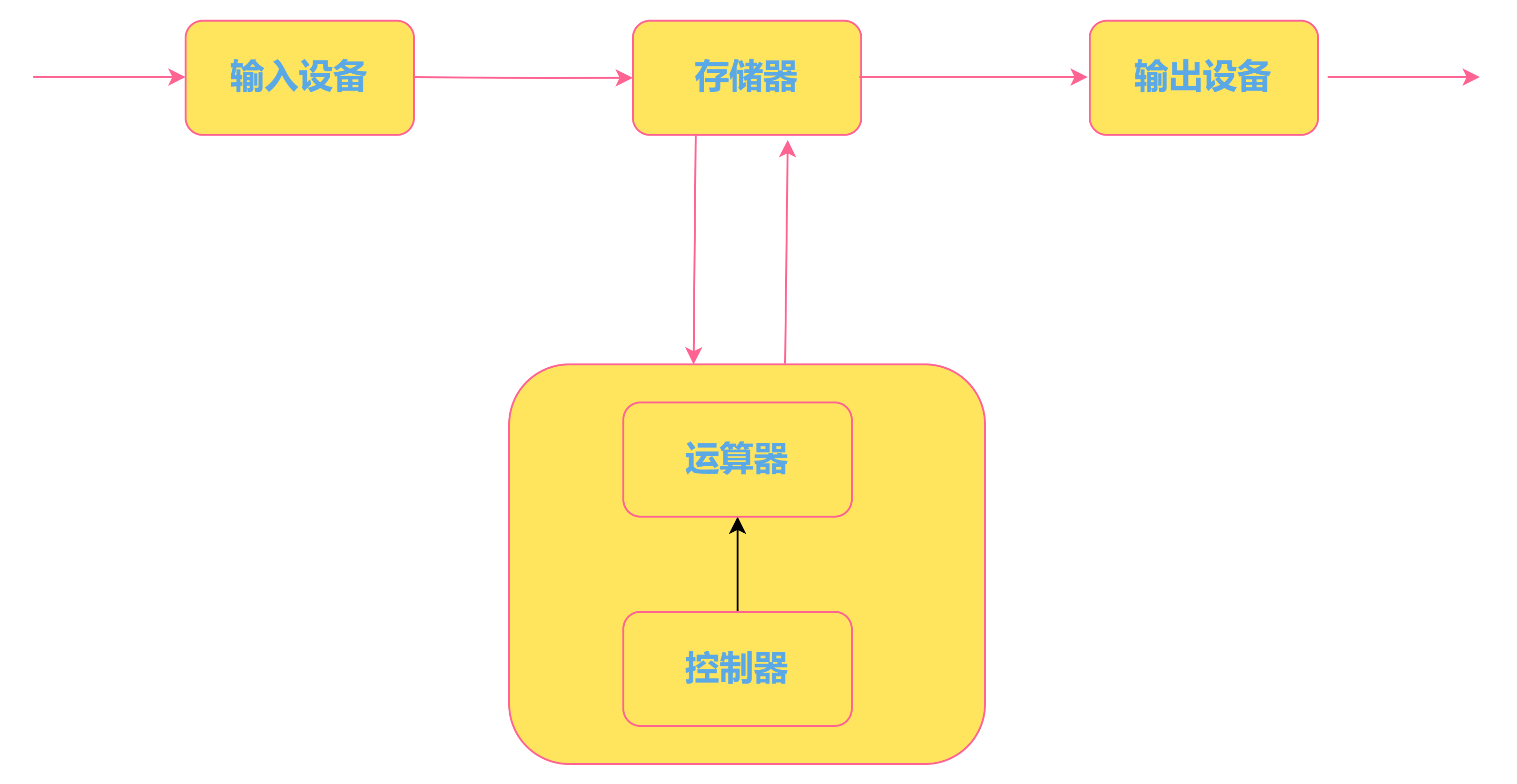
Python-tesseract 是 python 的光学字符识别 (OCR) 工具。 也就是说,它将识别并“读取”嵌入在图像中的文本。
1、下载安装 jTessBoxEditor和tesseract-ocr
我下载的是jTessBoxEditor-2.2.0版本的,里面自带tesseract-ocr。
两种下载的地方都行
阿里云盘分享 提取码: 47oh
或者各位可以去官网下载jTessBoxEditor: VietOCR - Browse /jTessBoxEditor at SourceForge.net
下载完成之后解压
里面有tesseract-ocr。
所以我们需要配置环境变量,右键此电脑图标,点击属性。
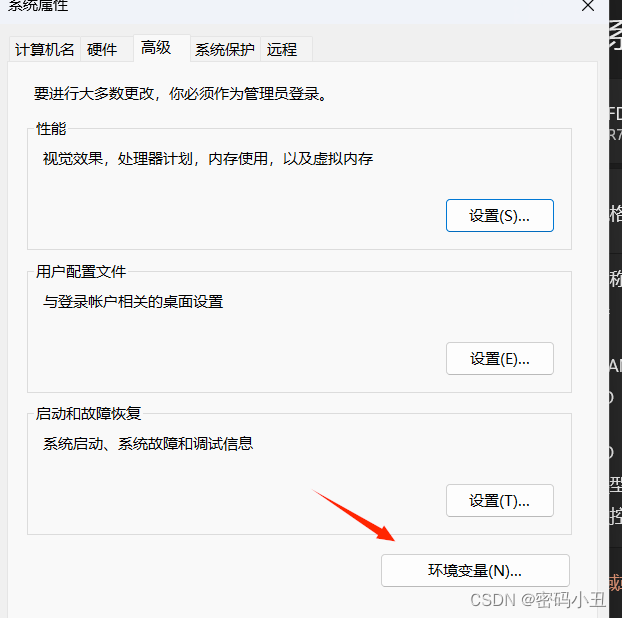
再点击高级系统设置.
在系统环境变量path路径下添加tesseract-ocr文件夹的路径。
之后在新建字库tessdata的系统变量,变量名为:TESSDATA_PREFIX
变量值为:E:\jTessBoxEditorFX\tesseract-ocr\tessdata,这个是例子,具体是你们自己的文件夹路径。
字库的训练图片格式最好是png的,注意图片数字周围的空白区域不能太窄,tesseract无法识别空白区域太窄的字符。
这个我是用某个网站的验证码脚本生成的

打开jTessBoxEditorFX.jar,打开这个的前提是要下载java环境,网上的话java环境配置一大堆,这里我就不讲了,只要你有java环境的话直接打开就行了。
选择 Tools -> Merge TIFF,打开对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片。
直接ctrl +A全选了,注意文件类型,选取自己使用的文件类型,不然显示不出来。
选好了之后,点击打开按钮,出现文件保存对话框,输入文件名:num_1.font.exp0.tif
保存在自己想放的位置。
2、使用tesseract生成.box文件
进入刚才存储num_1.font.exp0.tif文件所在目录,进入终端模式。
tesseract num_1.font.exp0.tif num_1.font.exp0 –l eng batch.nochop makebox
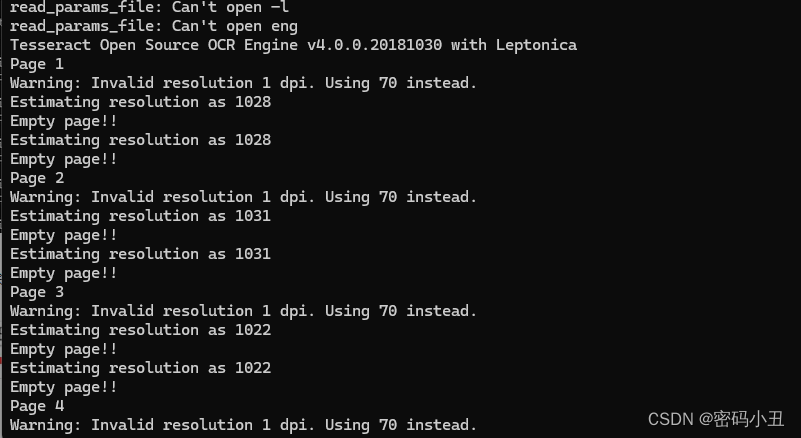
读取不出图片。
但是有些人可能会出现我这种情况,网上很多都没写,研究了很久之后才解决,浪费了我很多时间,所以我才想写这一篇文章,同时也记录一下问题。
tesseract num.font.exp0.tif num.font.exp0 -l eng --psm 11 batch.nochop makebox这里加上了--psm参数,以下是psm参数的一些作用
-
PSM 0 - Orientation and script detection (OSD) only: 仅检测文本方向和脚本,不执行 OCR 识别。
-
PSM 1 - Automatic page segmentation with OSD: 使用方向和脚本检测的自动页面分割。这是默认模式。
-
PSM 2 - Automatic page segmentation, but no OSD, or OCR: 自动页面分割,但不进行方向检测和 OCR 识别。适用于单一方向的文档。
-
PSM 3 - Fully automatic page segmentation, but no OSD: 完全自动页面分割,但不进行方向和脚本检测。
-
PSM 4 - Assume a single column of text of variable sizes: 假设文本为单列,文本大小可变。
-
PSM 5 - Assume a single uniform block of vertically aligned text: 假设文本为单一块,垂直对齐的文本。
-
PSM 6 - Assume a single uniform block of text: 假设文本为单一块,统一大小的文本。
-
PSM 7 - Treat the image as a single text line: 将图像作为单行文本处理。
-
PSM 8 - Treat the image as a single word: 将图像作为单个单词处理。
-
PSM 9 - Treat the image as a single word in a circle: 将图像作为圆圈中的单个单词处理。
-
PSM 10 - Treat the image as a single character: 将图像作为单个字符处理。
-
PSM 11 - Sparse text. Find as much text as possible in no particular order: 稀疏文本,尽可能多地查找文本,无特定顺序。
-
PSM 12 - Sparse text with OSD: 带有方向和脚本检测的稀疏文本。
-
PSM 13 - Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific: 处理原始文本行,绕过特定于 Tesseract 的修正。
这里选用psm 11的原因我认为图片识别的时候认为我文本太稀疏,识别不出图片内容。
正常生成。
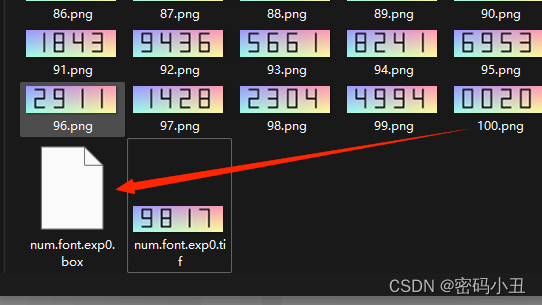
使用jTessBoxEditor调整.box训练文件.box文件中记录了每个字符在图片上的位置以及识别出的内容,但是我们需要对里面的内容进行修改,毕竟有些识别不是很准确。
对每张图片的识别字符和识别框进行纠正,如果字符识别错了,我们就改成正确的,如果识别出现偏差,我们也要进行调整。
打开进行手动调整
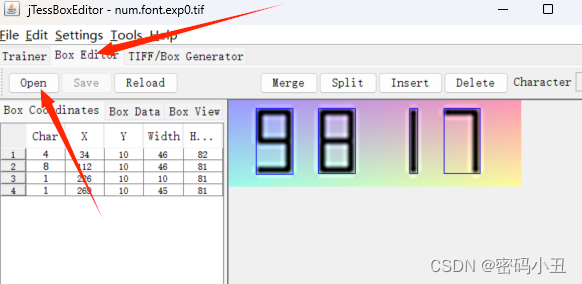
图片识别出4811。肯定是错的。
这种只要调整识别的数字就行了,接下来这个需要调整识别框的大小。
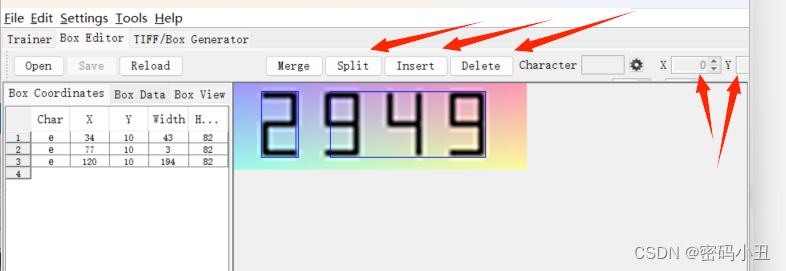
split分割,insert插入框,delete删除框。
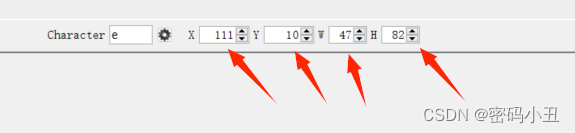
X和Y调整位置,W和H调整宽度和高度。
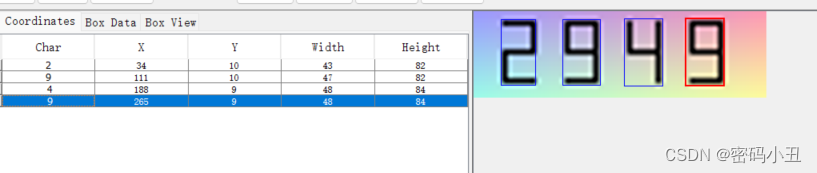
这样就调整好了,每个都要有错误都要调整一下。搞完之后要save一下。每个图片都要处理一下。
3、创建一个文件创建字体特征文件
在刚才文件夹内右键新建一个txt文件输入
font 0 0 0 0 0表示字体 font 的粗体、倾斜等共计5个属性全都设置为0。保存好之后吧txt后缀名去掉。文件名为font_properties。
4、使用tesseract生成num.font.exp0.tr训练文件
tesseract num.font.exp0.tif num.font.exp0 nobatch box.train还是错的,还是得加上--psm11.。
tesseract num.font.exp0.tif num.font.exp0 --psm 11 nobatch box.train
生成成功。
5、生成字符集文件
unicharset_extractor num.font.exp0.box
执行之后在当前目录生成unicharset文件。
6、生成数据字典
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
cntraining num.font.exp0.tr 
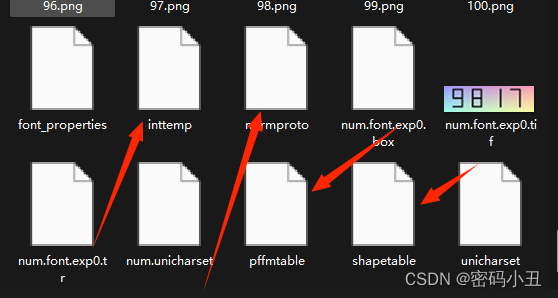
改名字。
需要手动修改名称,这里我们修改成num.inttemp、num.pffmtable、num.normproto、num.shapetable。
7、合并数据文件,生成字库文件。
combine_tessdata num. 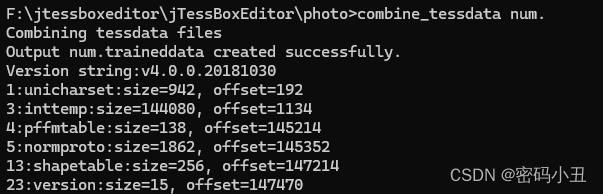
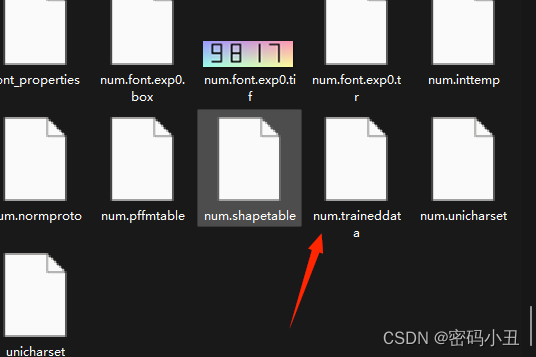
生成字库文件。把字库文件放到F:\jtessboxeditor\jTessBoxEditor\tesseract-ocr\tessdata。
文件路径写自己的。
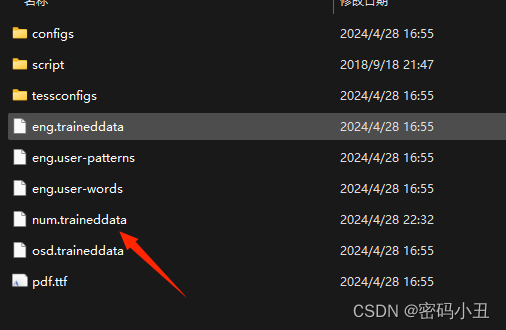
输入命令:
tesseract --list-langs

tesseract 3.png stdout -l num --psm 11试看看。

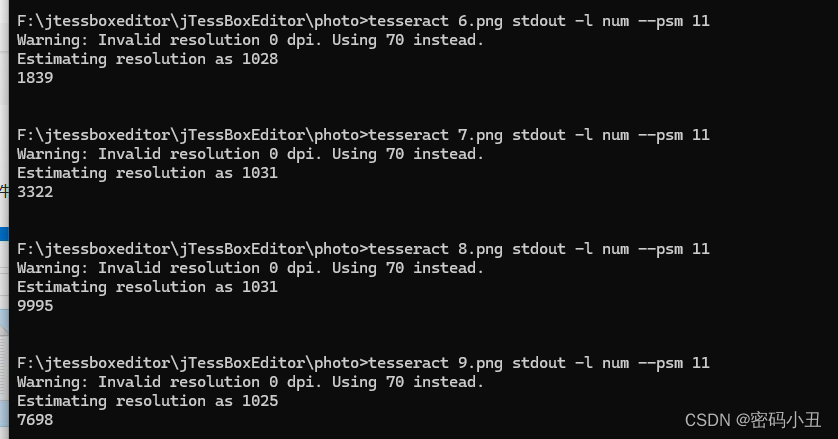
基本全部正确。
tesseract-ocr也可以当做接口使用。
8、tesseract-ocr接口python使用。
pip install pytesseract第一种方法:
下载pytesseract库。下载好了之后去python库文件地方修改pytesseract.py
 ‘
‘
’
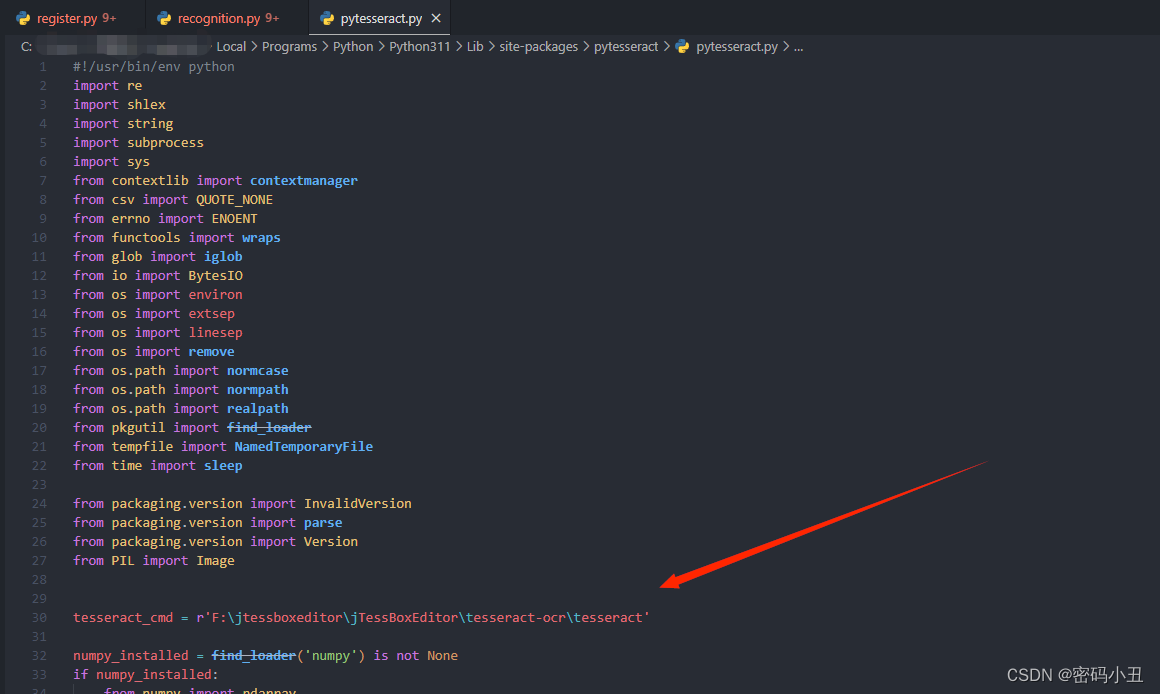
cmd修改成自己tesseract文件夹的位置。
接下来就可以使用了。
使用例子:
import pytesseract
import cv2
from PIL import Image
import osdef recognize_text(input_path):#调整图片宽高def resize_image(input_path, output_path, scale_factor, interpolation=cv2.INTER_CUBIC):# 读取输入图像img = cv2.imread(input_path)# 如果图像读取失败,则返回错误消息if img is None:print("无法读取输入图像,请检查文件路径!")return# 获取输入图像的高度和宽度height, width = img.shape[:2]# 根据缩放因子计算输出图像的大小new_width = int(width * scale_factor)new_height = int(height * scale_factor)# 调整图像大小resized_img = cv2.resize(img, (new_width, new_height), interpolation=interpolation)#删除原本图像os.remove(input_path)# 保存调整后的图像cv2.imwrite(output_path, resized_img)print("已保存调整大小后的图像:", output_path)output_path = input_pathresize_image(input_path,output_path, 6)image=Image.open(input_path)configdigit='--psm 11' #参数配置text=pytesseract.image_to_string(image,lang='num',config=configdigit) #选用自己的训练的数据集numreturn text #返回识别结果这个的话我有对输入进去的图片进行处理,我那个图片太小了,得把他调大。主要使用都是最后的几行。
第二种改进方法是:
每次在代码中加入以下代码,指明tesseract_cmd命令的位置,方便pytesseract调用:
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
pytesseract.pytesseract.tesseract_cmd =tesseract_cmd