1.GANs生成网络的定义
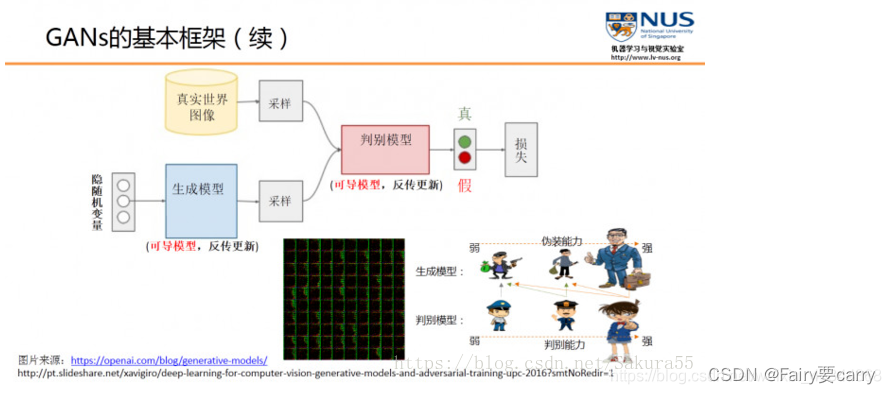
GANs是一种深度学习模型,用于生成新的数据实例,如图像、音频和文本。它主要由两部分组成:生成器(Generator)和判别器(Discriminator)。
2.生成器
生成器的目标是创造出尽可能逼真的数据,以便能够欺骗判别器。它接收一个随机噪声信号作为输入,并通过学习训练数据的分布来输出新的数据实例。这里的示例图中显示了生成器产生的图像,看起来像是数字或者某种图案。
3.判别器
判别器的任务是区分输入数据是真实的(来自训练集)还是由生成器产生的假数据。它接收数据(无论是真实的还是生成的)并输出其为真实数据的概率。图中的红绿灯象征判别器的决策——红灯代表“假”,绿灯代表“真”。
4.训练过程
GANs的训练过程涉及这两个网络的对抗过程:
1、生成器尝试生成越来越逼真的数据以欺骗判别器。
2、判别器则努力提高其区分真假数据的能力。
训练持续进行,直到生成器变得足够好,以至于判别器难以区分真假数据。这时,判别器对于真实数据和生成数据的判断准确率大约为50%,意味着它已经无法区分生成数据和真实数据。
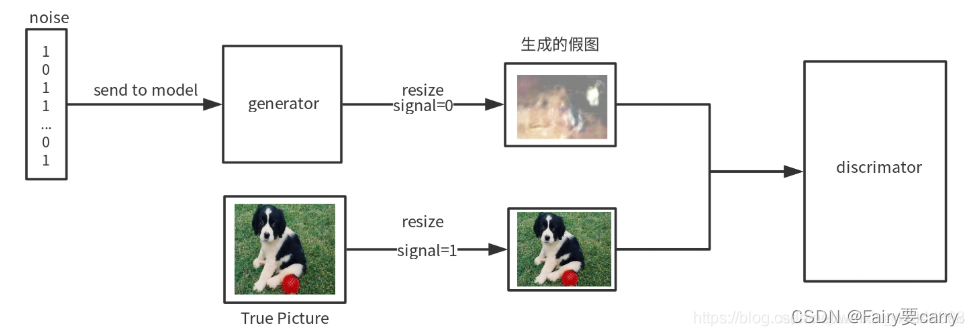
1. 数据输入:
在每个训练周期(epoch)中,判别器接收两种类型的数据输入:
1、**真实数据:**这些是从实际数据集中直接取出的样本,如真实的图片、声音片段等。
2、**生成数据:**这些数据由生成器产生,最初可能看起来与真实数据相比质量较低。
2. 输出判断:
判别器对每个输入数据进行评估,输出一个标量(通常是0到1之间的值),表示该数据被认为是真实的概率。在理想情况下,对于真实数据,这个值应该接近1;对于生成的数据,这个值应该接近0。
3. 损失函数:
为了训练判别器,我们使用一个损失函数来衡量它的表现。一种常用的损失函数是交叉熵损失(cross-entropy loss),这种损失函数可以衡量判别器输出的概率分布和真实标签之间的差异。判别器的目标是最小化这个损失值。(交叉熵本质就是对激活函数的负对数)
4.参数更新:
基于计算出的损失,使用反向传播算法来更新判别器的权重。这个步骤是通过梯度下降或其它优化算法实现的,目的是调整判别器的内部参数(如权重和偏置),使其更好地区分真实数据和生成数据。
与CNN和RNN的对比
(PS:建议先看看CNN和RNN的内容)
CNN卷积神经网络
RNN循环神经网络

综上所述:
1.数据处理: CNN适合处理空间数据(如图像),RNN适合处理时间序列数据,而GANs主要用于生成新的数据样本。
2.训练方式: CNN和RNN通常是监督学习或半监督学习,依赖于标记的数据集;GANs则是通过无监督学习的对抗训练过程,不直接依赖于标签数据。
3,输出: CNN和RNN通常输出一个分类或回归结果;GANs则输出新的数据实例。
5.为什么GANs是无监督学习?
结论: GANs的确需要真实的数据集来训练判别器和生成器的对抗过程,这一点和传统的无监督学习有所不同。然而,从技术定义上讲,GANs的训练方式更接近于一种特殊形式的无监督学习。
无标签数据的使用: 在GANs中,虽然判别器需要真实的数据集来进行训练,但这些数据并不需要明确的标签(例如,对于图像来说,不需要知道图像中具体是什么,只需要知道它是真实的)。判别器的任务是区分真实数据和生成数据,而不是进行分类或回归任务。因此,GANs并没有使用传统的监督学习所需的明确标签。
生成器的目标: 生成器的目标是通过对抗训练,生成足够逼真的数据以欺骗判别器。生成器本身并没有直接的监督信号(例如,真实数据的标签)来指导它生成什么样的数据,而是通过判别器的反馈来逐步改进自己。这个过程并不需要对生成的数据进行标注,因此具有无监督学习的特征。