1. 部署向量知识库到生产机
1.1. 基本环境配置
生产机上的环境还没有配好,这里我记录下需要配置的环境。
python 3.11.8
首先python环境最好选用3.11(准确来说支持3.8-3.11的任何release),我选择了python3.11.8

Python Release Python 3.11.8 | Python.org![]() http://PY3118
http://PY3118
Git
另外我需要在生产机上部署一些我自己写的程序,例如分词程序、建立易学知识库的程序,这就需要拉代码(不然回回拿着硬盘上机房拷代码太繁琐了),因此还得配置好git的环境。
Git - Downloading Package (git-scm.com) ![]() http://Git
http://Git
1.2. 安装依赖库
创建虚拟环境
这台服务器上还跑着其它的服务,每个服务都有自己的依赖库,为了防止不同环境的依赖冲突,需要配置虚拟环境(python virtual environment)。
有两种方式可以配置,第一种利用IDE,第二种使用命令行:
 利用IDE:File->Settings->Project Interpreter,随后新创建一个虚拟环境(最好不要继承基解释器的包)。
利用IDE:File->Settings->Project Interpreter,随后新创建一个虚拟环境(最好不要继承基解释器的包)。
利用命令行:
python">python -m venv path.to.your.venv随后激活虚拟环境:
python">path.to.your.venv/Scripts/activate即可进入虚拟环境。

Git - Downloading Package (git-scm.com)
想要退出,deactivate即可。
安装依赖库
到项目根目录下:
python">pip install -r requirements.txt
pip install -r requirements_api.txt
pip install -r requirements_webui.txt 切换torch到Cuda对应版本
由于我们是带着大模型启动的(Model Worker),而配置上是GPU版本的PyTorch。但是Requirements.txt中的torch是CPU版本的。
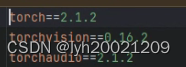
如果是GPU版本,应该是torch==2.1.2+cu的某个版本。
所以之后我们要手动下载一遍GPU版本,首先先查看本机cuda版本:
找到英伟达控制面板
找到系统信息
随后在组件中查看cuda驱动版本

随后我们就要找到对应的torch版本,先来到torch官网:
PyTorch![]() https://pytorch.org/
https://pytorch.org/
随后选择适合自己机器的选项,例如我是:
- Windows系统
- Pip包管理
- 语言python
- cuda 12.2
这样选完之后,即可获得安装对应torch的命令:
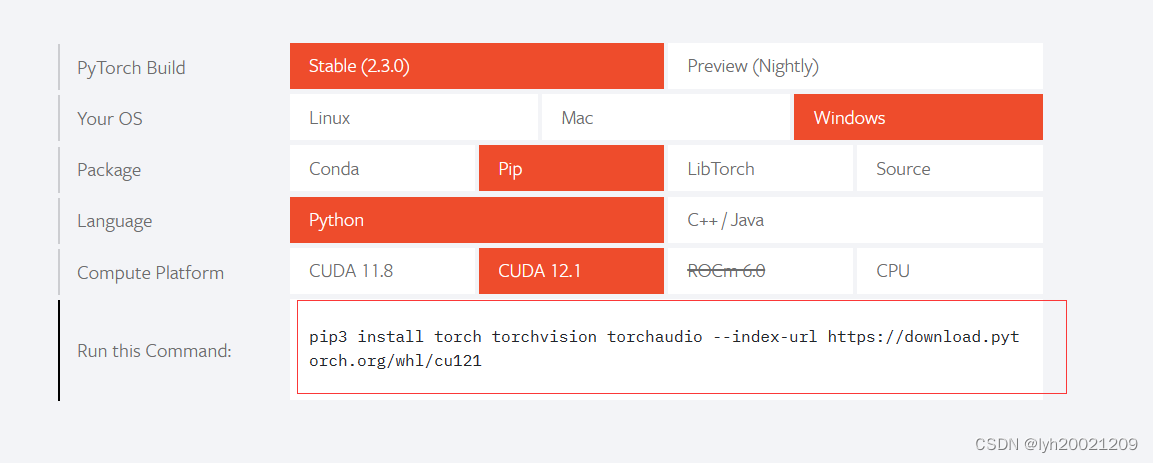 利用这个命令安装即可。
利用这个命令安装即可。

现在我们的torch带cuda版本了。
1.3. 运行服务
一行命令启动:
python">python startup.py -a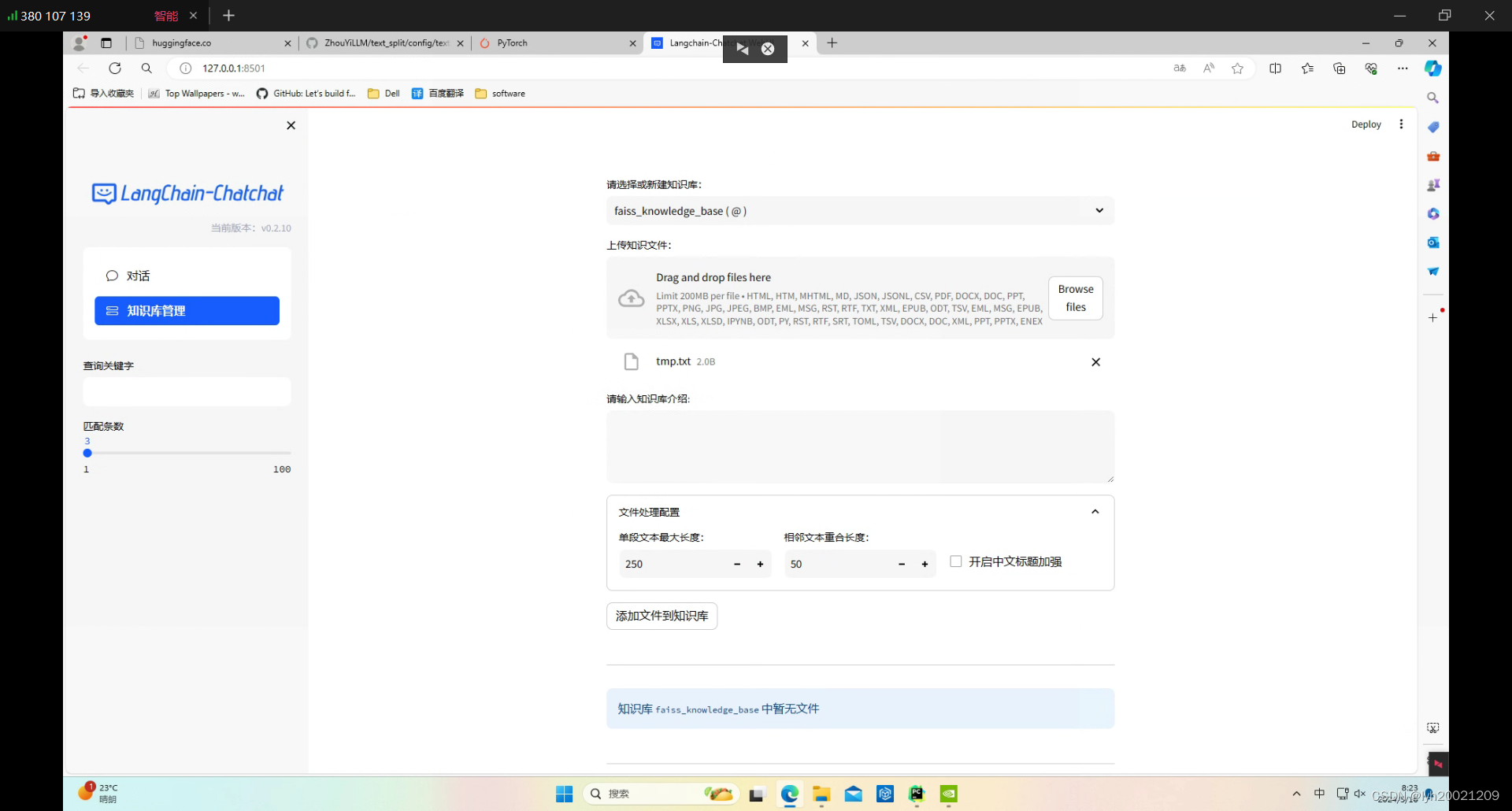
2. 分词与文档分割
这个任务主要还是非结构化文本,像之前我们整理出来的json文件,基本上可以不用动。
有哪些非结构化文本呢?主要还是集中于《周易研究》期刊的各个文章。之前我们是对它进行了Self-QA,提取了问答对,形成了json文件。不过Self-QA仅仅是阅读整篇文章后,提出问题并予以解答,可能会遗漏知识。因此我们需要对这部分文档进行分词,向量化,建立索引,并存入知识库。
2.1. 建立工作站
由于文件的存储结构是文件系统中一棵文件树的结构。因此为了防止掉电和宕机,以便于恢复现场,需要先建立工作站文件。
这一部分我复用了之前生成语料的工作站,详情见于:
项目实训2024.04.12日志:Self-QA生成问答对_self-qa论文-CSDN博客![]() https://blog.csdn.net/lyh20021209/article/details/137696063?spm=1001.2014.3001.5501
https://blog.csdn.net/lyh20021209/article/details/137696063?spm=1001.2014.3001.5501
2.2. 工作流程
简单来说:
- 从配置文件中提取源文件路径、目标存储路径、工作站名称、分词参数等
- 遍历所有需要分词的源文件根目录
- 提取当前路径下的工作站文件,遍历每一条工作任务记录
- 如果任务是文件夹,继续向下深度搜索
- 如果是文件,则进行分词
- 删除本条工作任务记录
- 回溯
获取配置参数
我将需要用到的参数全部配置到了一个json配置文件中:
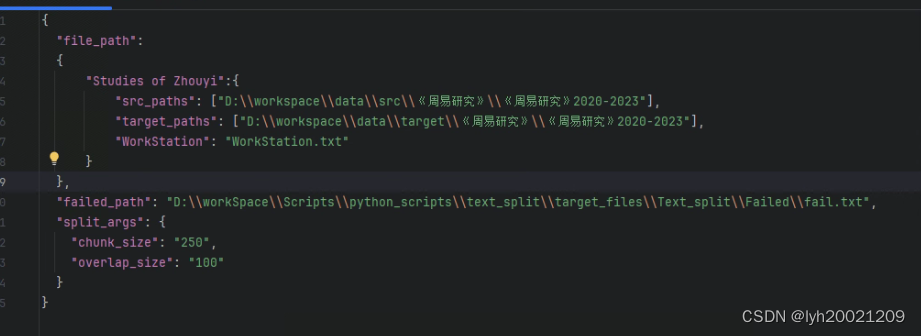
- 其中file_path包括了来源不同的源文件的源路径以及分词后的存储目标路径,还有源路径下的工作站名称。
- 此外还有一个failed_path记录处理失败的任务,便于重新执行。
- 之后的split_args是分词时的参数
此时我们就能够提取这些参数,准备深搜源文件:
python"> text_split_path = sys.argv[1]with open(text_split_path, 'r', encoding='utf-8') as f:config = json.load(f)fp = config['file_path']failed_root = config['failed_path']split_args = config['split_args']chunk = int(split_args['chunk_size'])overlap = int(split_args['overlap_size'])遍历所有需要分词的源文件根目录,因为可能源文件的根目录有多个,例如《周易研究》2020-2023、《周易研究》2008-2015等。
python"> for root in fp.values():src_paths = root['src_paths']target_paths = root['target_paths']for i in range(len(src_paths)):dfs_split(src_paths[i], target_paths[i], work_station=root['WorkStation'])深搜处理任务
对于每一个路径,提取当前路径下的工作站文件,遍历每一条工作任务记录。如果任务是文件夹,继续向下深度搜索。如果是文件,则进行分词
python">def dfs_split(path: str, target: str, work_station: str):# 获取工作站名称ws = os.sep.join([path, work_station])# 副本ws_tmp = work_station.replace('.txt', '.tmp')ws_tmp = os.sep.join([path, ws_tmp])# print(f'{ws}\n{ws_tmp}')while True:with open(ws, 'r+', encoding='utf-8') as file, open(ws_tmp, 'a+', encoding='utf-8') as tmp:lines = file.readlines()if len(lines) == 0:return# 读取第一条任务task = path + '\\' + lines[0].rstrip()# 剩余任务写入副本for k in range(1, len(lines)):tmp.write(lines[k].rstrip() + '\n')print(f'正在处理任务:{task}')# 文件夹深搜if os.path.isdir(task):dfs_split(task, target, work_station)else:# 分词res = do_split(task)# 保存do_save(target, res, task, lines[0].rstrip())if os.path.exists(ws):os.remove(ws)# 重命名副本覆盖工作站os.rename(ws_tmp, ws)分词器
这个api在langchain官网有介绍:
LangChain中文网:500页中文文档教程,助力大模型LLM应用开发从入门到精通![]() https://www.langchain.com.cn/
https://www.langchain.com.cn/
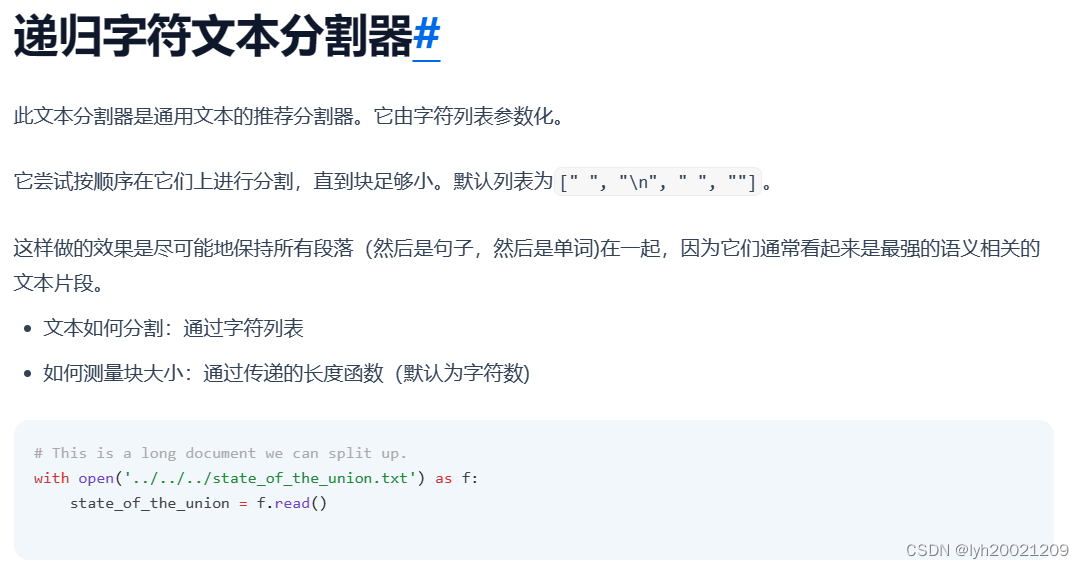 因此我根据这个递归字符文本分割器,封装了一个专门用于中文的(也即模式串上更符合汉语特点的)分词器:
因此我根据这个递归字符文本分割器,封装了一个专门用于中文的(也即模式串上更符合汉语特点的)分词器:
python"> def __init__(self,separators: Optional[List[str]] = None,keep_separator: bool = True,is_separator_regex: bool = True,**kwargs: Any,) -> None:"""Create a new TextSplitter."""super().__init__(keep_separator=keep_separator, **kwargs)self._separators = separators or ["\n\n","\n","。|!|?","\.\s|\!\s|\?\s",";|;\s",",|,\s"]self._is_separator_regex = is_separator_regex在类对象初始化时,我先看用户是否穿了自定义的模式串(因为用户肯定是对待分词文本更了解的那个),如果没有,用一个默认的模式串分隔符。
python"> def _split_text(self, text: str, separators: List[str]) -> List[str]:"""Split incoming text and return chunks."""final_chunks = []# Get appropriate separator to useseparator = separators[-1]new_separators = []for i, _s in enumerate(separators):_separator = _s if self._is_separator_regex else re.escape(_s)if _s == "":separator = _sbreakif re.search(_separator, text):separator = _snew_separators = separators[i + 1:]break_separator = separator if self._is_separator_regex else re.escape(separator)splits = _split_text_with_regex_from_end(text, _separator, self._keep_separator)# Now go merging things, recursively splitting longer texts._good_splits = []_separator = "" if self._keep_separator else separatorfor s in splits:if self._length_function(s) < self._chunk_size:_good_splits.append(s)else:if _good_splits:merged_text = self._merge_splits(_good_splits, _separator)final_chunks.extend(merged_text)_good_splits = []if not new_separators:final_chunks.append(s)else:other_info = self._split_text(s, new_separators)final_chunks.extend(other_info)if _good_splits:merged_text = self._merge_splits(_good_splits, _separator)final_chunks.extend(merged_text)return [re.sub(r"\n{2,}", "\n", chunk.strip()) for chunk in final_chunks if chunk.strip()!=""]-
初始化:创建一个空列表
final_chunks,用于存储最终的文本块。 -
选择分隔符:从
separators列表中选择一个分隔符。如果separators的最后一个元素不是空字符串,并且它在文本中存在,则选择它作为分隔符。如果存在多个分隔符,将选择第一个在文本中找到的分隔符,并使用剩余的分隔符进行后续的分割。 -
转义分隔符:如果
_is_separator_regex为False,则使用re.escape()对分隔符进行转义,以确保分隔符中的任何特殊字符都被正确处理。 -
分割文本:使用
_split_text_with_regex_from_end函数(这个函数没有在代码中定义,可能是外部定义的)来根据选定的分隔符分割文本。self._keep_separator参数决定是否保留分隔符。 -
合并文本块:遍历分割后的文本块,如果文本块的长度小于
self._chunk_size,则将其添加到_good_splits列表中。否则,将_good_splits中的文本块合并,然后添加到final_chunks中,并清空_good_splits以进行下一轮的合并。 -
递归分割:如果当前文本块不能直接合并,并且
new_separators(剩余的分隔符)不为空,则对当前文本块使用剩余的分隔符进行递归分割。 -
最终合并:如果在遍历结束后
_good_splits中还有文本块,则将它们合并并添加到final_chunks中。 -
清理和返回:最后,使用正则表达式替换连续的换行符(
\n),并去除空白字符,然后返回非空的文本块列表。
因此在分词过程中,我们初始化一个类实例,随后把之前获取到的配置参数传入:
python">def do_split(task: str) -> List[str]:global chunk, overlaptry:text = read_docx(task)# 调分词器t_splitter = ChineseRecursiveTextSplitter(keep_separator=True,is_separator_regex=True,chunk_size=chunk,chunk_overlap=overlap)res = t_splitter.split_text(text)return resexcept Exception as e:print(f'对{task}进行分词时出现错误:{e}')do_fail_rec(task)分词效果大致如下:
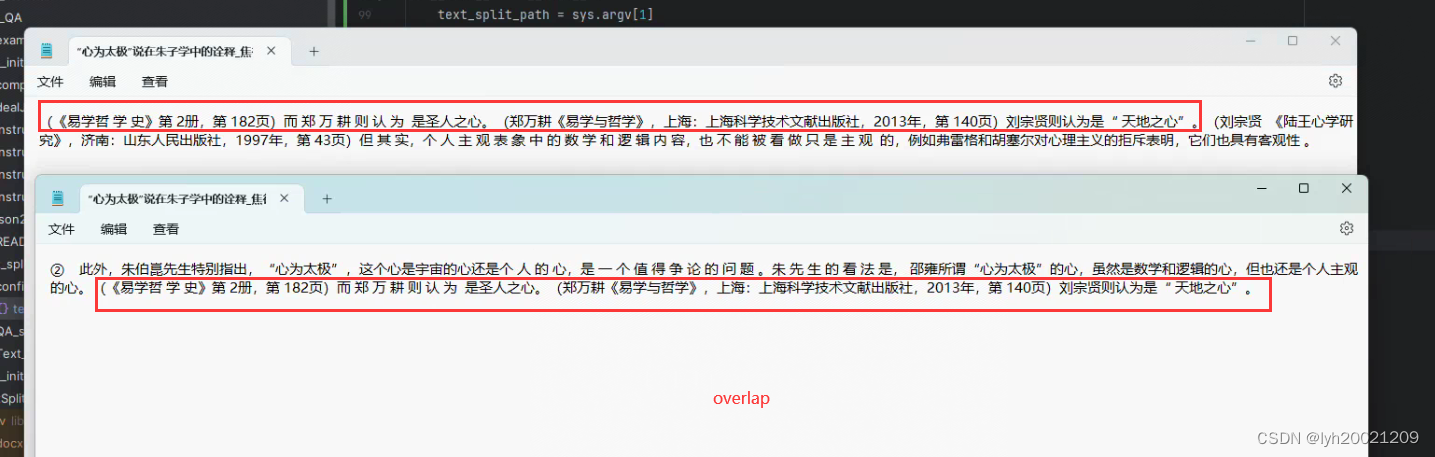
可以看到,两段相邻分块之间是有重合的部分,这可以更好的保存上下文线索,便于检索。
3. 建立易学知识库
(待更新)