要确保Kafka在使用过程中的稳定性,需要从kafka在业务中的使用周期进行依次保障。主要可以分为:事先预防(通过规范的使用、开发,预防问题产生)、运行时监控(保障集群稳定,出问题能及时发现)、故障时解决(有完整的应急预案)这三阶段。
另外的篇幅请参考
如何更好地使用Kafka? - 事先预防篇-CSDN博客
如何更好地使用Kafka? - 故障时解决-CSDN博客
运行时监控主要包含集群稳定性配置与Kafka监控的最佳实践,旨在及时发现Kafka在运行时产生的相关问题与异常。
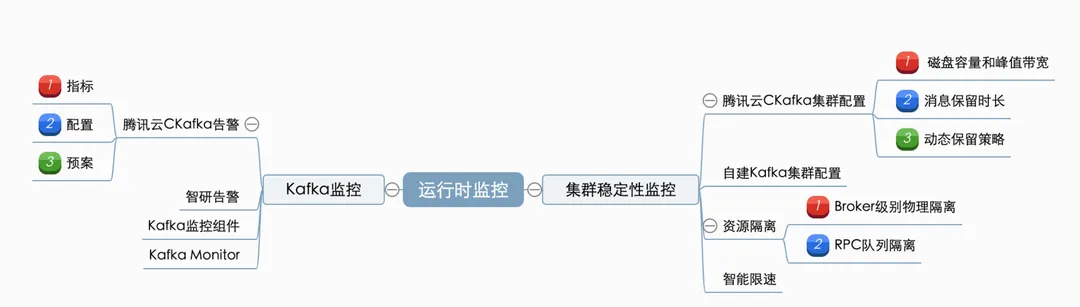
1. 集群稳定性监控
kafka%E9%9B%86%E7%BE%A4%E9%85%8D%E7%BD%AE">1.1 kafka集群配置
合理进行kafka实例配,主要关注这几个数据:
-
磁盘容量和峰值带宽
-
消息保留时长;
-
动态保留策略;
A. 磁盘容量和峰值带宽
可根据实际业务的消息内容大小、发送消息qps等进行预估,可以尽量设置大点;具体数值可根据实例监控查看,如果短时间内磁盘使用百分比就达到较高值,则需扩容。
峰值带宽=最大生产流量*副本数
B. 消息保留时长
消息即使被消费,也会持久化到磁盘存储保留时长的时间。该设置会占用磁盘空间,如果每天消息量很大的话,可适当缩短保留时间。
C. 动态保留策略
推荐开启动态保留设置。当磁盘容量达到阈值,则删除最早的消息,最多删除到保底时长范围外的消息(淘汰策略),可以很大程度避免磁盘被打满的情况。
但有调整时不会主动通知,但我们可以通过配置告警感知磁盘容量的变化。
kafka%E9%9B%86%E7%BE%A4%E9%85%8D%E7%BD%AE">1.2 Kafka集群配置
-
设置日志配置参数以使日志易于管理;
-
了解 kafka 的(低)硬件需求;
-
充分利用 Apache ZooKeeper;
-
以正确的方式设置复制和冗余;
-
注意主题配置;
-
使用并行处理;
-
带着安全性思维配置和隔离 Kafka;
-
通过提高限制避免停机;
-
保持低网络延迟;
-
利用有效的监控和警报。
1.3 资源隔离
A. Broker级别物理隔离
如果不同业务线的 topic 会共享一块磁盘,若某个consumer 出现问题而导致消费产生 lag,进而导致频繁读盘,会影响在同一块磁盘的其他业务线 TP 的写入。
解决:Broker级别物理隔离:创建Topic、迁移Topic、宕机恢复流程
B. RPC队列隔离
Kafka RPC 队列缺少隔离,一旦某个 topic 处理慢,会导致所有请求 hang 住。
解决:需要按照控制流、数据流分离,且数据流要能够按照 topic 做隔离。
-
将 call 队列按照拆解成多个,并且为每个 call 队列都分配一个线程池。
-
一个队列单独处理 controller 请求的队列(隔离控制流),其余多个队列按照 topic 做 hash 的分散开(数据流之间隔离)。
如果一个 topic 出现问题,则只会阻塞其中的一个 RPC 处理线程池,以及 call 队列,可以保障其他的处理链路是畅通的。
1.4 智能限速
整个限速逻辑实现在 RPC 工作线程处理的末端,一旦 RPC 处理完毕,则通过限速控制模块进行限速检测。
-
配置等待时间,之后放入到 delayed queue 中,否则放到 response queue 中。
-
放入到 delayed queue 中的请求,等待时间达到后,会被 delayed 线程放入到 response queue 中。
-
最终在 response queue 中的请求被返回给 consumer。
kafka%E7%9B%91%E6%8E%A7">2. Kafka监控
-
白盒监控:服务或系统自身指标,如CPU 负载、堆栈信息、连接数等;
-
黑盒监控:一般是通过模拟外部用户对其可见的系统功能进行监控的一种监控方式,相关指标如消息的延迟、错误率和重复率等性能和可用性指标。
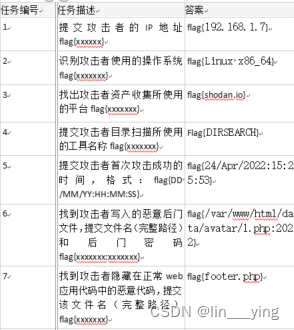
| 监控 | 功能/指标 | 详情 |
|---|---|---|
| 黑盒监控 | 操作 | 主题操作:创建、预览、查看、更新、删除 |
| 服务 | 数据写入、是否消费成功 | |
| 系统 | CPU 负载、堆栈信息、连接数等 | |
| 白盒监控 | 容量 | 总存储空间、已用存储空间、最大分区使用、集群资源、分区数量、主题数量; |
| 流量 | 消息写入、消费速率、集群网络进出; | |
| 延迟 | 消息写入、消费耗时(平均值、99分位、最大耗时)、主题消费延迟量(offset lag) | |
| 错误 | 集群异常节点数量、消息写入拒绝量、消息消费失败量、依赖zookeeper的相关错误 |
kafka%E5%91%8A%E8%AD%A6%E3%80%81%E9%85%8D%E7%BD%AE%E5%92%8C%E9%A2%84%E6%A1%88">2.1 kafka告警、配置和预案
针对kafka,需要配置告警(此类告警一般为消息积压、可用性、集群/机器健康性等检查)。
A. 指标
如:实例健康状态、节点数量、健康节点数量、问题分区数、生产消息数、消费请求数、jvm内存利用率、平均生产响应时间、分区消费偏移量等。
具体指标可以参考:消息队列 CKafka 版 查询高级监控(专业版)-操作指南-文档中心-腾讯云
B. 配置
配置文档:消息队列 CKafka 版 配置告警-操作指南-文档中心-腾讯云
选择监控实例,配置告警内容和阈值。
一般会对当前服务自身的kafka集群做告警配置,但是如果是依赖自身消息的下游服务出现消费问题,我们是感知不到了;而且针对消费端服务不共用同一个集群的情况,出现消息重复发送的问题,服务自身是很难发现的。
C. 预案
在业务上线前,最好梳理下自身服务所涉及的topic消息(上游生产端和下游消费端),并细化告警配置,如果出现上游kafka异常或者下游kafka消息堆积可以及时感知。特别需要把可能有瞬时大量消息的场景(如批量数据导入、定时全量数据同步等)做一定的告警或者预案,避免服务不可用或者影响正常业务消息。
2.2 自建告警平台
通过自建告警平台配置对服务自身的异常告警,其中包括对框架在使用kafka组件时抛出与kafka消费逻辑过程中抛出的业务异常。
其中,可能需要异常升级的情况(由于)单独做下处理(针对spring kafka):
-
自定义kafka异常处理器:实现KafkaListenerErrorHandler接口的方法,注册自定义异常监听器,区分业务异常并抛出;
-
消费Kafka消息时,将@KafkaListener的errorHandler参数设置为定义的Kafka异常处理器;
-
此后,指定的业务异常会被抛出,而不会被封装成Spring kafka的框架异常,导致不能清晰地了解具体异常信息。
kafka%E7%9B%91%E6%8E%A7%E7%BB%84%E4%BB%B6">2.3 Kafka监控组件
目前业界并没有公认的解决方案,各家都有各自的监控之道。
-
Kafka Manager:应该算是最有名的专属 Kafka 监控框架了,是独立的监控系统。
-
Kafka Monitor:LinkedIn 开源的免费框架,支持对集群进行系统测试,并实时监控测试结果。
-
CruiseControl:也是 LinkedIn 公司开源的监控框架,用于实时监测资源使用率,以及提供常用运维操作等。无 UI 界面,只提供 REST API。
-
JMX 监控:由于 Kafka 提供的监控指标都是基于 JMX 的,因此,市面上任何能够集成 JMX 的框架都可以使用,比如 Zabbix 和 Prometheus。已有大数据平台自己的监控体系:像 Cloudera 提供的 CDH 这类大数据平台,天然就提供 Kafka 监控方案。
-
JMXTool:社区提供的命令行工具,能够实时监控 JMX 指标。答上这一条,属于绝对的加分项,因为知道的人很少,而且会给人一种你对 Kafka 工具非常熟悉的感觉。如果你暂时不了解它的用法,可以在命令行以无参数方式执行一下kafka-run-class.sh kafka.tools.JmxTool,学习下它的用法。
kafka-monitor">2.4 Kafka Monitor
其中,Kafka Monitor通过模拟客户端行为,生产和消费数据并采集消息的延迟、错误率和重复率等性能和可用性指标,可以很好地发现下游的消息消费情况进而可以动态地调整消息的发送。(使用过程中需注意对样本覆盖率、功能覆盖率、流量、数据隔离、时延的控制)
Kakfa Monitor 优势:
-
通过为每个 Partition 启动单独的生产任务,确保监控覆盖所有 Partition。
-
在生产的消息中包含了时间戳、序列号,Kafka Monitor 可以依据这些数据对消息的延迟、丢失率和重复率进行统计。
-
通过设定消息生成的频率,来达到控制流量的目的。
-
生产的消息在序列化时指定为一个可配置的大小(验证对不同大小数据的处理能力、相同消息大小的性能比较)
-
通过设定单独的 Topic 和 Producer ID 来操作 Kafka 集群,可避免污染线上数据,做到一定程度上的数据隔离。
基于Kafka Monitor的设计思想,可以针对业务特点引入对消息的延迟、错误率和重复率等性能的监控告警指标。