目录
内容来源:
【GUN】【tr】指令介绍
【busybox】【tr】指令介绍
linux%E3%80%91%E3%80%90tr%E3%80%91%E6%8C%87%E4%BB%A4%E4%BB%8B%E7%BB%8D-toc" style="margin-left:0px;">【linux】【tr】指令介绍
使用示例:
转换字符 - 默认
转换字符 - 不翻译指定字符数组
此指令目前接触少,用得少,把精力放到其他常用指令上
常用组合指令:
指令不常用/组合用法还需继续挖掘:
内容来源:
GUN : Coreutils - GNU core utilities
busybox v1.36.1 : 【busybox记录】【shell指令】基于的Busybox的版本和下载方式-CSDN博客
【GUN】【tr】指令介绍
tr:翻译、压缩和/或删除字符
简介:tr [option]... string1 [string2]tr 执行下列操作之一,将标准输入复制到标准输出。翻译,并可选择压缩结果中重复的字符,挤压重复的字符,删除字符,删除字符,然后从结果中挤出重复的字符。操作数string1和string2定义了字符数组array1和array2。默认情况下,array1列出tr操作的输入字符,array2列出相应的翻译。在某些情况下,第二个操作数会被省略。该程序接受以下选项。参见第2章[常见选项],第2页。
选项必须在操作数之前。
‘-c’
‘-C’
‘--complement’使用它的补码(string1没有指定的所有字符),并按升序排列,而不是array1。在多字节语言环境中使用此选项时要谨慎,因为其含义并不总是明确或可移植。参见第9.1.1节[字符数组],第82页。
‘-d’
‘--delete’删除array1中的字符;不要翻译。
‘-s’
‘--squeeze-repeats’将最后一个指定数组中列出的重复字符的每个序列替换为该字符的一次出现。
‘-t’
‘--truncate-set1’将array1的长度截断为array2的长度。
退出状态为零表示成功,非零值表示失败。
9.1.1指定字符数组虽然string1和string2操作数看起来很相似,但它们不是正则表达式。相反,它们只是表示字符数组。作为POSIX的GNU扩展,空字符串操作数表示空字符数组。string1和string2的解释取决于语言环境。GNU tr完全只支持安全的单字节语言环境,其中每个可能的输入字节表示一个字符。不幸的是,这意味着GNU tr不会以您所期望的方式处理类似`tr¨o Ł`这样的命令,因为(假设是UTF-8编码)这等价于`tr '\303\266' '\305\201'`,并且GNU tr将简单地将所有的`\303`字节转换为`\305`字节,等等。POSIX没有明确指定tr在某些区域中的行为,这些区域中的字符使用字节序列而不是单个字节表示,或者数据可能包含编码错误的无效字节。为了避免这方面的问题,您可以使用类似于`LC_ALL=C tr`的shell命令而不是普通的tr,在安全的单字节区域设置中运行tr。尽管大多数字符只是简单地用string1和string2表示自己,但为了方便,这些字符串也可以包含下面列出的简写。有些简写只能在string1或string2中使用,如下所述。反斜杠转义可以识别下列反斜杠转义序列:‘\a’ Bell (BEL, Control-G).‘\b’ Backspace (BS, Control-H).‘\f’ Form feed (FF, Control-L).‘\n’ Newline (LF, Control-J).‘\r’ Carriage return (CR, Control-M).‘\t’ Tab (HT, Control-I).‘\v’ Vertical tab (VT, Control-K).‘\ooo’ 值为ooo的8位字节,它是反斜杠之后1到3个八进制数字的最长序列。为了可移植性,ooo应该表示一个能装进8位的值。作为POSIX的GNU扩展,如果值不能容纳,则只使用ooo的前两位数字,例如,' \400 '等同于' \0400 ',表示两个字节的序列。‘\\’ 一个反斜杠。如果未转义的反斜杠后面没有字符,则为错误。作为一个GNU扩展,反斜杠后跟一个未在上面列出的字符会被解释为该字符,删除任何特殊意义;这可以用于转义字符'['和'-',当它们是特殊字符时。范围符号'm-n'按升序扩展到从m到n的字符。m不应排在n之后;如果是,就会导致错误。例如,`0-9`等同于`0123456789`。GNU tr不支持使用方括号将范围括起来的System V语法。这种格式指定的翻译有时会按预期工作,因为括号经常被音译为它们自己。但是,应该避免使用它们,因为它们有时表现得出乎意料。例如,`tr -d '[0-9]'`会同时删除括号和数字。许多历史上常见的甚至是被接受的范围的使用都不是完全可移植的。例如,在EBCDIC主机上使用`A-Z`范围将不会实现大多数人所期望的效果,因为`A`到`Z`在ASCII中是不连续的。解决这个问题的一种方法是使用字符组(见下文)。否则,枚举范围的成员是最可移植的(也是最难看的)方式。重复字符string2中的表示法'[c*n]'扩展为字符c的n个副本。因此,'[y*6]'与'yyyyyy'相同。string2中的'[c*]'表示法可以扩展为使array2和array1一样长的c的副本。如果n以'0'开头,则以八进制解释,否则以十进制解释。0值的n被视为不存在。字符类符号`[:class:]`扩展到(预定义的)类class中的所有字符。当同时提供--delete (-d)和--squeeze-repeats (-s)选项时,可以在string2中使用任何字符类。否则,string2只接受lower和upper字符组,而且只有在string1中相同的相对位置指定了对应的字符组(upper和lower)时才接受。这样做指定了大小写转换。除了大小写转换之外,类中的字符没有特定的顺序。类名如下。当类名无效时,将导致错误。alnum 字母和数字。alpha 字母。blank 水平空白。cntrl 控制字符。digit 位数。graph 可打印字符,不包括空格。lower 小写字母。print 可打印字符,包括空格。punct 常用的标点符号。space 水平或垂直空白。upper 大写字母。xdigit 十六进制数字。等价类语法`[=c=]`展开为与c相等的所有字符,没有特定的顺序。只有同时给出--delete (-d)和--squeeze-repeats -s时,string2中才允许使用这些等价类。虽然等价类旨在支持非英语字母,但似乎没有标准的方法来定义它们或确定它们的内容。因此,它们在GNU tr中没有完全实现。每个字符的等价类只包含该字符,没有特殊用途。9.1.2转换当string1和string2都给定且没有指定--delete (-d)选项时,tr将执行转换。tr将其输入中array1中的每个字符转换为array2中的相应字符。不在array1中的字符会原原不动地传递。作为POSIX的GNU扩展,当一个字符在array1中出现多次时,只使用最后一个实例。例如,下面两个命令是等价的:tr aaa xyztr a ztr的一个常见用途是将小写字符转换为大写字符。这可以通过多种方式实现。下面是其中的三个:tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZtr a-z A-Ztr '[:lower:]' '[:upper:]'但是,像a-z这样的范围在C语言环境之外是不可移植的。在tr执行转换时,array1和array2通常具有相同的长度。如果array1比array2短,则忽略array2末尾的额外字符。另一方面,让array1比array2长是不可移植的;POSIX表示结果未定义。在这种情况下,BSD tr根据需要多次重复array2的最后一个字符,从而将array2补全到array1的长度。System V tr将array1截断为array2的长度。默认情况下,GNU tr像BSD tr一样处理这种情况。当给出--truncte -set1 (-t)选项时,GNU tr会像System V tr一样处理这种情况。对于除转换之外的操作,该选项将被忽略。在这种情况下,类似于System V tr的做法打破了相对常见的BSD惯用法:tr -cs A-Za-z0-9 '\012'因为它只将0字节(array1补码中的第一个元素)转换为换行符,而不是将所有非字母数字转换为换行符。顺便说一下,上面的用法是不可移植的,因为它使用了范围,而且它假定newline的八进制代码为012。下面是一种更好的写法:tr -cs '[:alnum:]' '[\n*]'
9.1.3压缩重复和删除如果只提供--delete (-d)选项,tr会删除array1中的所有输入字符。当只给出--squeeze-repeats (-s)选项而不进行translate时,tr将array1中重复字符的每个输入序列替换为该字符的一次出现。当同时给出--delete和--squeeze-repeats时,tr首先使用array1执行任何删除操作,然后使用array2从任何剩余字符中挤压重复。翻译时也可以使用--squeeze-repeats选项,在这种情况下,tr首先执行翻译,然后使用array2从任何剩余字符中挤压重复。下面是一些示例来说明各种选项组合:删除所有0字节:tr -d '\0'将所有单词单独连成一行。该函数将所有非字母数字字符转换为换行符,然后将每个包含重复换行符的字符串压缩为一个换行符:tr -cs '[:alnum:]' '[\n*]'将每个重复的换行符序列转换为一个换行符。例如,删除空行:tr -s '\n'查找文档中出现重复的单词。例如,人们经常写“the the”,重复的单词之间用换行符分隔。下面的Bourne shell脚本首先将每个标点符号和空白字符序列转换为一个换行符。这会将每个“单词”单独放在一行上。接下来,它将所有大写字符映射为小写,最后使用-d选项运行uniq,只打印出重复的单词。#!/bin/shcat -- "$@" \| tr -s '[:punct:][:blank:]' '[\n*]' \| tr '[:upper:]' '[:lower:]' \| uniq -d删除一小部分字符通常很简单。例如,要删除所有的`a`、`x`和`M`,你可以这样做:tr -d axM然而,当`-`是这些字符之一时,它可能会很棘手,因为`-`有特殊的含义。执行与上面相同的任务,但同时删除所有的`-`字符,我们可以尝试tr -d -axm,但这会失败,因为tr会尝试将-a解释为命令行选项。或者,我们可以尝试在字符串中放入连字符tr -d a-xm,但这也不起作用,因为这会让tr将a-x解释为字符范围'a'…'x',而不是三个字符。解决这个问题的一种方法是把连字符放在字符列表的末尾:tr -d axM-或者你可以使用`--`来终止选项处理:tr -d -- -axM【busybox】【tr】指令介绍
linux%E3%80%91%E3%80%90tr%E3%80%91%E6%8C%87%E4%BB%A4%E4%BB%8B%E7%BB%8D" style="margin-left:.0001pt;">【linux】【tr】指令介绍
[root@localhost bin]# tr --help
用法:tr [选项]... SET1 [SET2]
Translate, squeeze, and/or delete characters from standard input,
writing to standard output.-c, -C, --complement use the complement of SET1-d, --delete delete characters in SET1, do not translate-s, --squeeze-repeats replace each sequence of a repeated characterthat is listed in the last specified SET,with a single occurrence of that character-t, --truncate-set1 first truncate SET1 to length of SET2--help 显示此帮助信息并退出--version 显示版本信息并退出SET 是一组字符串,一般都可按照字面含义理解。解析序列如下:\NNN 八进制值为NNN 的字符(1 至3 个数位)\\ 反斜杠\a 终端鸣响\b 退格\f 换页\n 换行\r 回车\t 水平制表符\v 垂直制表符字符1-字符2 从字符1 到字符2 的升序递增过程中经历的所有字符[字符*] 在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度[字符*次数] 对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数[:alnum:] 所有的字母和数字[:alpha:] 所有的字母[:blank:] 所有呈水平排列的空白字符[:cntrl:] 所有的控制字符[:digit:] 所有的数字[:graph:] 所有的可打印字符,不包括空格[:lower:] 所有的小写字母[:print:] 所有的可打印字符,包括空格[:punct:] 所有的标点字符[:space:] 所有呈水平或垂直排列的空白字符[:upper:] 所有的大写字母[:xdigit:] 所有的十六进制数[=字符=] 所有和指定字符相等的字符Translation occurs if -d is not given and both SET1 and SET2 appear.
-t may be used only when translating. SET2 is extended to length of
SET1 by repeating its last character as necessary. Excess characters
of SET2 are ignored. Only [:lower:] and [:upper:] are guaranteed to
expand in ascending order; used in SET2 while translating, they may
only be used in pairs to specify case conversion. -s uses the last
specified SET, and occurs after translation or deletion.GNU coreutils 在线帮助:<https://www.gnu.org/software/coreutils/>
请向 <http://translationproject.org/team/zh_CN.html> 报告 tr 的翻译错误
完整文档请见:<https://www.gnu.org/software/coreutils/tr>
或者在本地使用:info '(coreutils) tr invocation'使用示例:
转换字符 - 默认
把1-9转化成a-g,不足的以末尾字符为准
指令: tr 1-9 a-g

转换字符 - 不翻译指定字符数组
-d 选项
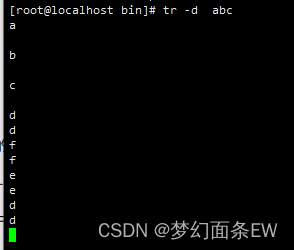
示例: 不翻译abc
指令: tr -d abc
此指令目前接触少,用得少,把精力放到其他常用指令上
NA
常用组合指令:
NA