论文:Generate rather than Retrieve: Large Language Models are Strong Context Generators
⭐⭐⭐⭐
ICLR 2023
Code: github.com/wyu97/GenRead
一、论文速读
该工作发现:由 LLM 生成的文档中,往往比 retrieved documents 更可能包含正确的答案。于是,该工作尝试走一条与 retrieve-then-read pipeline 不同的思路:generate-then-read pipeline(GenRead)。
generate-then-read 的基本思路是:
- Generate:首先 prompt LLM(如 InstructGPT)根据 question 生成相关的上下文文档
- Read:把 question 和生成的上下文文档交给 LLM 来获得最终的 answer
注意,Generate 步骤和 Read 步骤所使用的 LLM 可以不同,Read 步骤可以使用一个较小的、针对特定数据集训练的模型(如 FiD)
二、如何让 LLM 生成更加丰富多样的上下文文档?
论文指出:如何让 LLM 生成多样的、高质量的上下文文档是一个具有挑战性的任务。这里介绍一下论文的一些做法。
2.1 Diverse Human Prompts
由于单一的 prompt 会产生相似的 token distribution,所以这里让 human annotators 去提供多个不同的 prompt,从而引导 LLM 去生成多样化的上下文 documents。
论文指出,这个做法虽然简单,但是很有效。
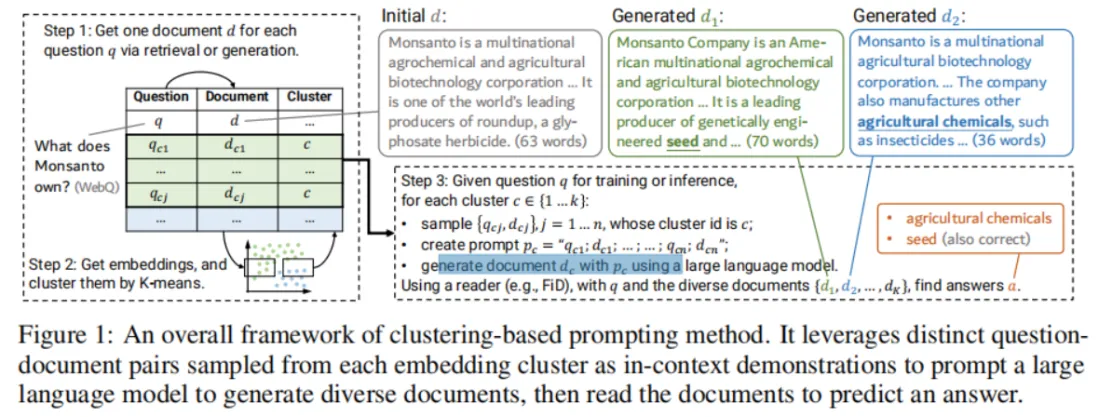
2.2 Clustering-based Prompts
Generate 步骤中,在引导 LLM 去生成文档时,可以使用 In-Context Learning 来引导其生成多样化的文档,为了达成这一目的,可以在提供给 LLM 的 few-shot exemplars 中尽量放一些多样化的 question-doc 示例。
具体做法如下:
- 针对数据集的每一个 question,使用 retriever(如 BM25)检索出一个对应的 document。由此获得一堆 question-document pairs。
- 使用 LLM(如 GPT-3)去对 pairs 中的每一个 document 进行编码,得到一个 12288 维度的 vector。然后对这些 vectors 做 K-means 聚类。
- 在每个聚类的 cluster 中,随机选出 n 个 question-document pair,作为 exemplars。
通过以上方法,就可以拿到用于 in-context learning 的 in-context demostrations 来引导 LLM 生成多样化的上下文文档。
如下图展示了 clustering-based prompting 方法的整体架构:
四、gen-read 与 retrieve-read 结合
论文指出,将本文提出的 generative-then-read 与已有的 retrieve-then-read 结合,可以达到更好的效果。
结合的方式就是:将 generatived 的上下文文档与 retrieved 的文档合并起来,再交给 reader 去阅读。
因此,本文提出的 generative-then-read 方法可以与目前已有的任何 reader 机制进行结合,并将 generated context documents 插入到目前任何知识密集型 NLP 任务中。
五、实验结果
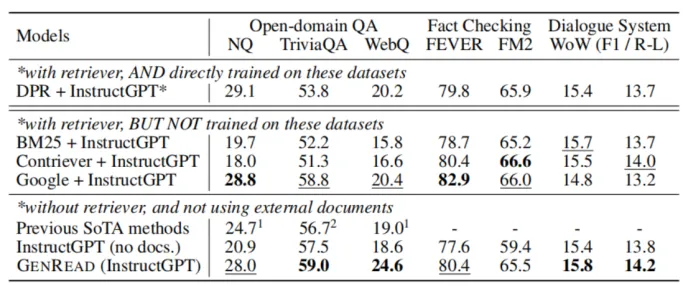
实验表明,GenRead 方法能够有效地利用大型语言模型的生成能力来解决知识密集型任务,并且多个任务上在不引入任何外部数据的情况下达到了或超过了现有 RAG 方法的性能。
六、总结
这篇论文提出了 Generative-Read 的思路,其实验表明,在不引入外部知识的情况下,其表现就可以达到甚至超过当前的 RAG 的方法。这说明了:当前对 LLM 的内部知识的利用还远远不足。
当然,本文也提出,将 Gen-Read 与 Retrivee-Read 进行结合可以达到更好的表现,所以如何在 RAG 系统中更加充分利用 LLM 内部知识,是一个值得研究的挑战。



