吉林大学人工智能学院研究员高一星、中国科学院计算技术研究所副研究员唐帆、中国科学院自动化研究所研究员董未名等在人工智能领域的CCF-A类顶级国际会议IJCAI上发表的工作,揭示并分析基于样本混合的数据增强方法在开放场景下存在的问题,提出了基于非对称蒸馏框架的解决方法。
论文链接:http://arxiv.org/abs/2404.19527
一、研究背景
数据增强在神经网络的训练中扮演着十分重要的作用,根据操作方式的不同,我们可以将其分为基于单个样本的数据增强(Single-Sample-based Augmentation, SSA)和基于多个样本的数据增强(Multiple-Sample-based Augmentation, MSA)。由于MSA通过线性组合训练集中的多个样本产生新数据,可以使数据集中的样本更加多样化,往往也能给模型性能带来更多收益。然而,一些研究指出了这种增强方式会牺牲模型对某些特定类的识别精度或造成模型混淆相似类的特征。
与传统的闭集识别问题不同,开集识别任务(Open-set Recognition, OSR)在要求模型准确分类训练集中所有类别的同时,要求模型能够识别训练集之外的类别。由于未知类数据在训练过程中是不可见的,所以该任务更依靠模型识别到每个已知类独有的特征,因而对上述提到的特征混淆问题也会更敏感。在图1中,我们揭示了MSA在给模型闭集分类能力带来巨大提升的同时牺牲了模型的开集性能。
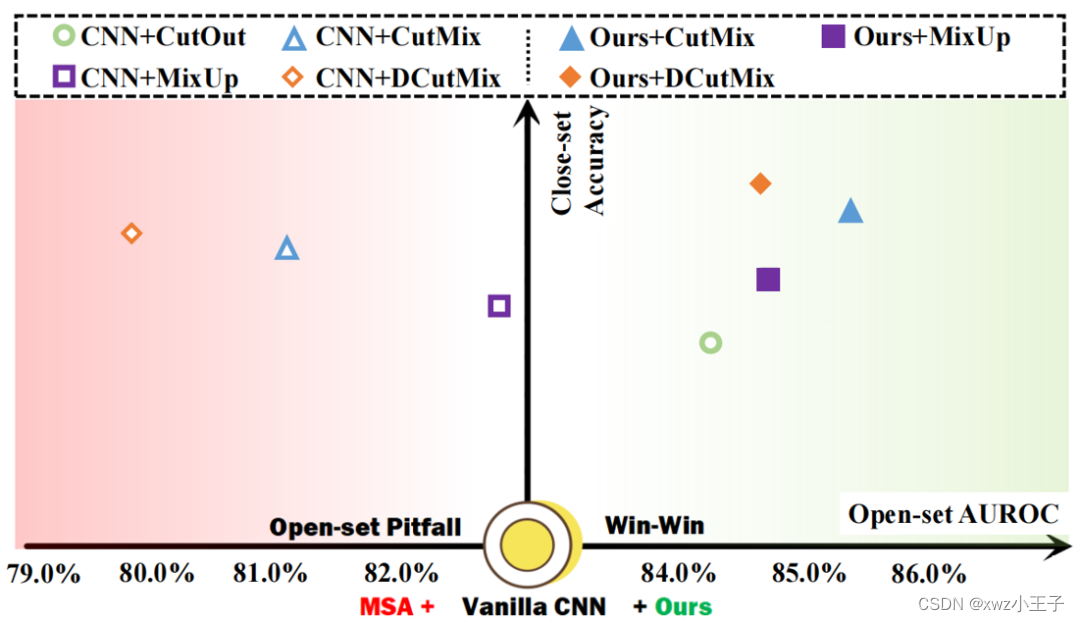
图1 数据增强的“两面性”。在带来模型闭集性能提升的同时,MSA会损害模型鉴别未知类别的能力。
通过进一步实验研究数据增强方法和开集识别任务之间的相互作用,我们观察到:(1)在开集识别任务上,由于MSA会混淆相似类的特征,其性能要比SSA差;(2)知识蒸馏(Knowledge Distillation, KD)可以提升模型的开集性能,但MSA同样会损害知识蒸馏带来的开机性能提升。通过深入分析MSA对模型行为的影响,我们发现MSA会降低模型对样本特征和最终输出的整体激活程度。由于现有方法大多通过对模型的输出设置阈值来识别开集样本,模型激活程度的降低直接导致了其更难分辨未知类样本。知识蒸馏虽然一定程度上可以缓解该问题,但由于MSA样本本身的不确定性,直接蒸馏这些样本仍然会出现上述问题。
基于上述观察,我们创新性地提出了非对称蒸馏框架以解决MSA带来闭集性能提升的同时造成模型开集能力退化的问题,达到“双赢”的效果。具体来说,经典的对称蒸馏框架将MSA样本同时输入教师模型和学生模型中,在此基础上,我们将额外的原始样本输入教师模型,通过增加原始样本与混合样本之间的互信息约束使得学生模型更关注混合样本中每个类独有的特征,从而扩大教师模型对学生模型的影响。与此同时,教师模型对一些混合样本会产生错误预测(如对于第i类和第j类的混合样本,教师模型预测其为第k类),这些被错误预测的样本往往不包含该类独特的特征,我们重新赋予这些样本一个不确定度较高的标签,使学生模型降低对这些类无关特征的激活水平,学习更具有分辨性的特征。
二、研究内容
2.1 揭示数据增强的“两面性”
我们用不同的SSA、MSA方法训练ResNet、VGG、MobileNetV2等模型以验证图1得到的结论。除此之外,参考以往的工作,我们研究了知识蒸馏对MSA的影响。实验结果表明:(1)MSA相对SSA能给模型闭集识别准确率带来更多收益,但会造成模型开集能力的显著下降;(2)知识蒸馏可以同时提升模型的开集和闭集识别性能,然而,在MSA加入蒸馏时,模型的闭集识别准确率会进一步提高,而蒸馏对模型开集性能的提升会被破坏。
2.2 MSA影响开集识别任务中模型的判别指标
OSR任务中,模型通过对测试样本输出的logits设置阈值以鉴别未知类样本。因此,模型对已知类和未知类激活水平的差异会直接影响模型鉴别未知类的能力。
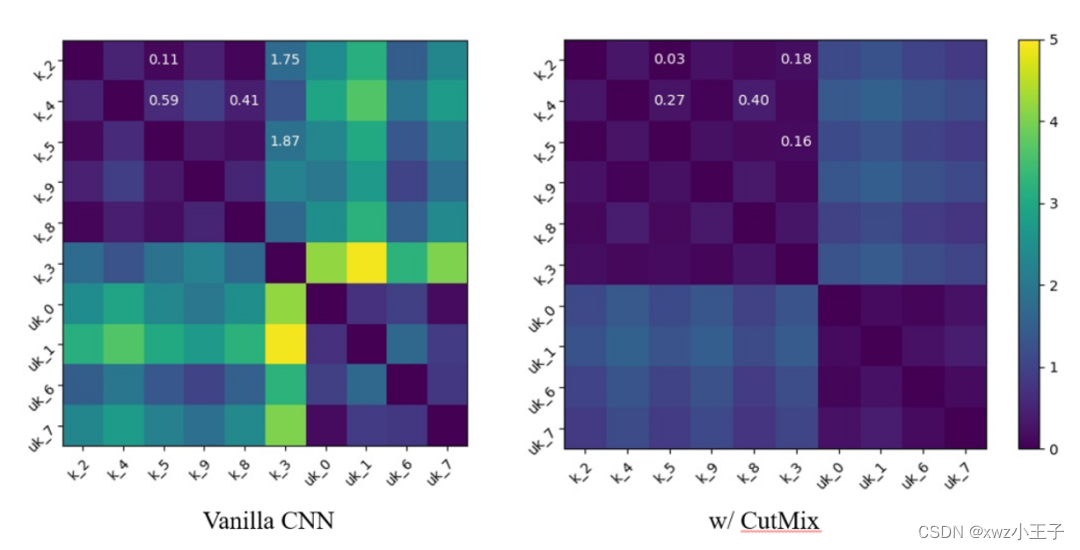
图2 MNIST数据集上不同训练方式下类间差异对比。
Choi等人提出MSA会造成模型混淆具有相似语义的类别,在图2的两幅热力图中,我们展示了在MNIST数据集上的可视化结果。图中‘k’和‘uk’分别表示已知类和未知类,下划线后的数字表示其具体类别。由于MSA会影响模型的整体激活水平,所以由MSA(CutMix)训练得到的模型热力图整体颜色更暗。对比两幅热力图,在图中所示的类别中,相似类(数字‘2’和数字‘3’,数字‘2’和数字‘5’)的差异前后变化更明显,而不相似类(数字‘4’和数字‘5’,数字‘4’和数字‘8’)的差异前后变化不大。相似类之间的这种混淆使得模型更容易将与这些类有相似特征的未知类识别为已知类,从而造成开集能力的退化。
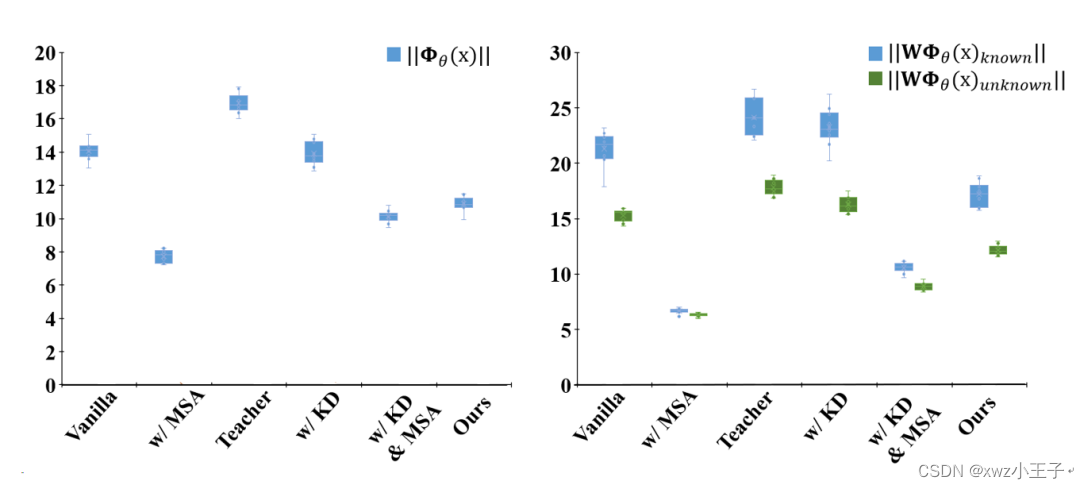
图3 不同训练方式下模型激活程度对比。
考虑到开集识别任务中模型主要依靠对最终输出的logits设置阈值来筛选未知类,在图3中,我们对比了不同训练方式下模型特征(图3左)以及模型对已知类和未知类输出的最终logits(图3右)的整体水平。如图所示,MSA造成了模型特征激活水平的下降,也缩小了已知类和未知类之间logits的差距,使模型更难分辨两者。知识蒸馏可以增大已知类和未知类之间激活水平的差距,从而提升模型的开集性能。然而,MSA在加入蒸馏过程之后,会破坏蒸馏的提升作用。
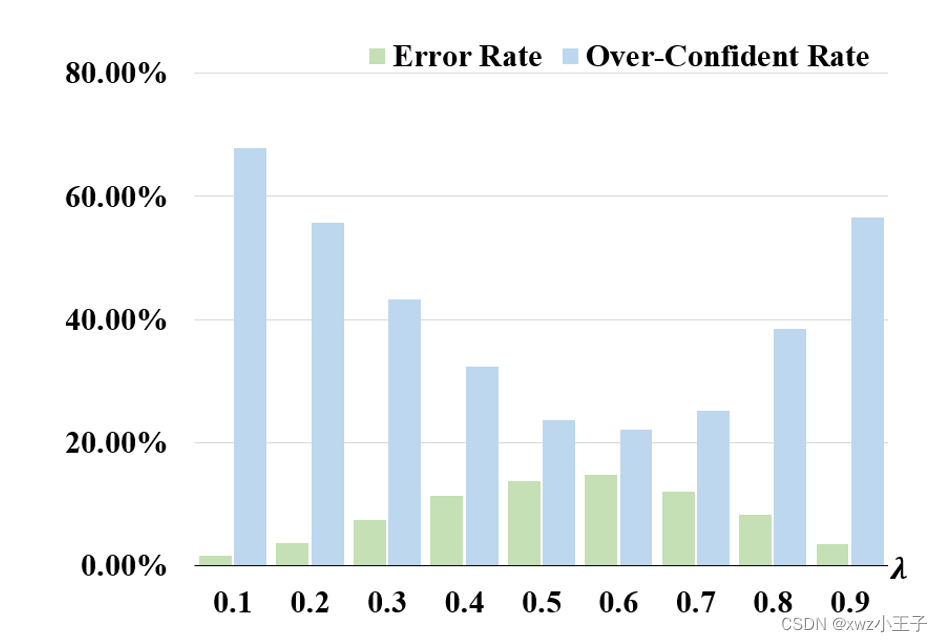
图4 教师模型对不同混合比例的混合样本做出的错误预测和过度自信预测的统计结果。
由于一些混合样本可能产生模糊的语义信息,导致即使性能强大的教师模型也容易做出错误预测。在图4中,我们统计了教师模型对不同混合比例下的样本做出过度自信预测(预测概率大于95%)和错误预测的比例,结果显示,即使在两个样本均匀混合的条件下,教师模型也会对20%以上的样本做出过度自信的预测,且被错误预测的混合样本的比例也不容忽视。
三、非对称蒸馏框架

图5 非对称蒸馏框架结构图。
3.1 交叉互信息损失
如图5所示,在传统的对称蒸馏框架中,使用第i和j类的混合样本训练时,教师模型和学生模型同时输入混合样本,利用蒸馏损失函数进行训练。在此基础上,我们提出非对称蒸馏框架,教师模型除输入混合样本外,还会接受额外的原样本作为输入。对于混合样本,我们通过最大化教师和学生输出的特征中的互信息使模型在混合样本中更关注每个类独有的特征。例如,在学习第i类独有特征时,对于学生模型产生的混合样本的特征,我们最大化其与教师模型特征中包含的第i类特征的互信息,此目标可以表达为最大化以下互信息项:
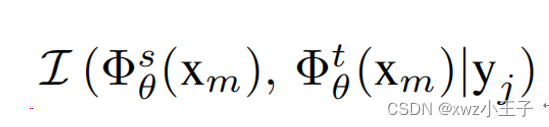
基于此目标,我们通过优化互信息损失函数:
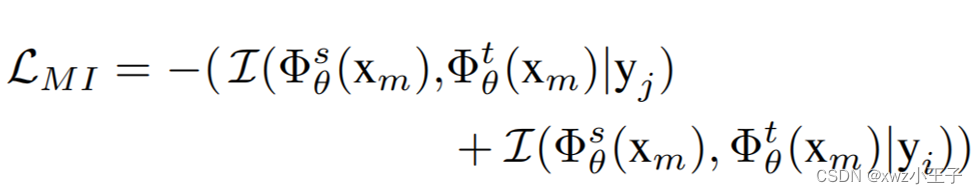
可以使学生模型更专注于混合样本中分别包含的第i和第j类独特的特征,从而减少类间混淆现象的产生。由于此目标较难直接优化,我们发现了教师模型对第i和第j类原样本输出的特征中分别包含了我们期望从混合样本中得到的每个类的独有特征,因此我们将上式重新组织为:
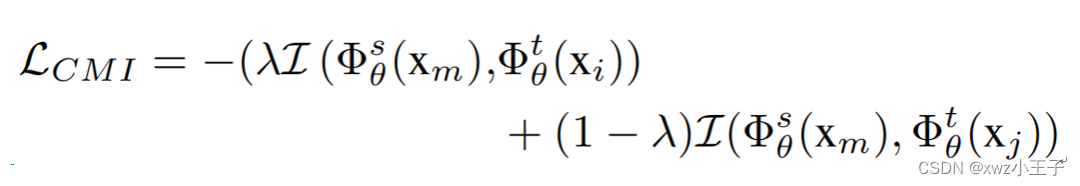
超参数为第i和j类的的混合比例。
3.2 双热标签平滑
除此之外,我们使用松弛的样本筛选策略过滤出教师模型错误预测的混合样本。具体来说,若教师模型将第i类和第j类的混合样本预测为第k类时,我们将其视为错误样本,这些错误样本往往不包含第i和j类具有分辨性的特征。我们使用重标签方法,在这些混合样本原有的双热标签的基础上加以平滑,利用这些样本学习到更多的不确定性,并降低模型对这些样本中包含的类无关特征的激活程度和预测置信度。
经过以上讨论,最终模型的训练损失为蒸馏损失、交叉互信息损失和重标签损失三部分:
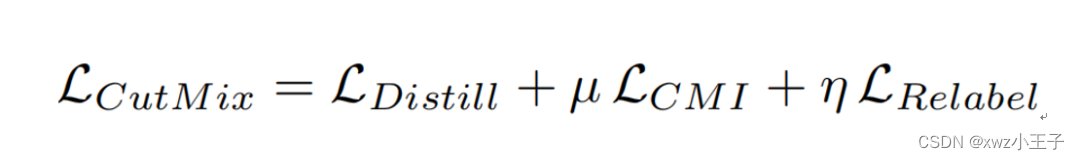
在我们的实验中,两个权重超参数均为1。
四、对比分析
在标准的开集分类基准数据集、语义偏移基准数据集(Semantic Shift Benchmark, SSB)、大规模基准数据集ImageNet-21k等数据集上的实验表明,我们提出的非对称蒸馏框架解决了混合样本带来模型开集性能下降的问题。我们的方法在模型的闭集识别准确率和开集识别性能上都超越了现有方法。
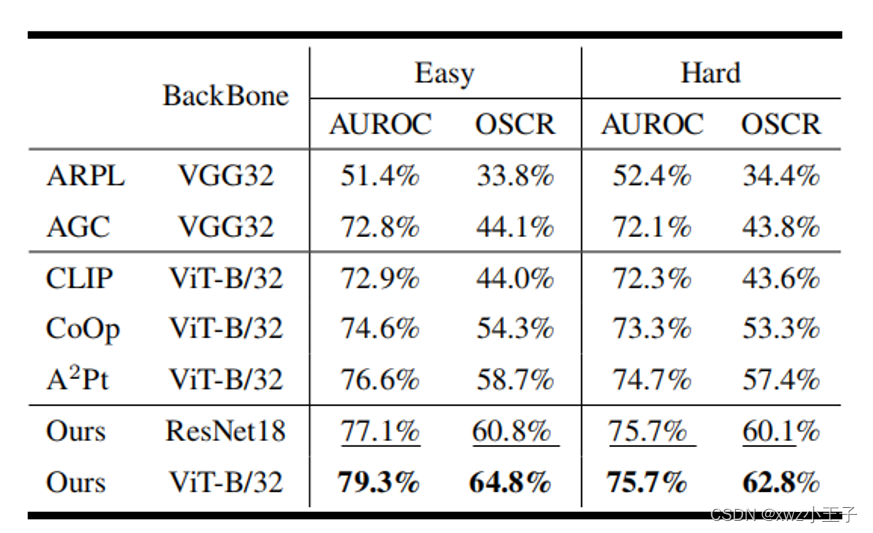
表1在大规模数据集ImageNet-21k不同困难程度的分划上的实验结果。