查找算法
二分查找 (要求熟练)
// C// 二分查找法(递归实现)
int binarySearch(int *nums, int target, int left, int right) // left代表左边界,right代表右边界
{if (left > right) return -1; // 如果左边大于右边,那么说明找不到,直接返回-1int mid = (left + right) / 2; // 计算出中间位置的下标if (nums[mid] == target) return mid; // 如果刚好相等,就返回下标if (nums[mid] > target) return binarySearch(nums, target, left, mid - 1); // 如果大于,说明肯定不在右边,直接去左边找else return binarySearch(nums, target, mid + 1, right); // 如果小于,说明肯定不在左边,直接去右边找
}
更多内容
七大查找算法 (C语言实现):https://www.cnblogs.com/maybe2030/p/4715035.html
排序算法
基础排序
| 排序算法 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(1) | 稳定 |
| 插入排序 | O(n) | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(1) | 不稳定 |
冒泡排序 (要求熟练)
基本介绍
-
冒泡排序的核心就是交换,通过不断地进行交换,一点一点将大的元素推向一端,每一轮都会有一个最大的元素排到对应的位置上,最后形成有序。
-
动画演示:https://visualgo.net/zh/sorting
代码实现
// C#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 冒泡排序
void bubbleSort(int* arr, int size)
{int temp;bool ordered = true; // 我们先假设传进来的数组是有序的for (int i = 0; i < size - 1; i++){for (int j = 0; j < size - 1 - i; j++){if (arr[j] > arr[j + 1]) // 如果没有执行if语句,说明数组确实是本来就有序{ordered = false;temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}if (ordered){printf("该数组本来就有序!\n");return;}}
}// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{// int arr[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };int arr[] = { 7, 3, 5, 9, 2, 0, 6, 1, 4, 8 };int arrSize = 10;show(arr, arrSize);// 冒泡排序bubbleSort(arr, arrSize);show(arr, arrSize);getchar();return 0;
}
插入排序
基本介绍
-
我们默认第一个是有序状态,剩余的部分我们会挨着遍历,然后将其插到前面对应的位置上去
-
每轮排序会从后面依次选择一个元素,与前面已经处于有序的元素,从后往前进行比较,直到遇到一个不大于当前元素的的元素,将当前元素插入到此元素的前面
-
动画演示:https://visualgo.net/zh/sorting
代码实现
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 插入排序
void insertSort(int* arr, int size)
{int current, j;for (int i = 1; i < size; i++){current = arr[i];j = i;while (j > 0 && arr[j - 1] > current){arr[j] = arr[j - 1]; // 找的过程中需要不断进行后移操作,把位置腾出来j--;}arr[j] = current;}
}// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = { 7, 3, 5, 9, 2, 0, 6, 1, 4, 8 };int arrSize = 10;show(arr, arrSize);// 插入排序insertSort(arr, arrSize);show(arr, arrSize);getchar();return 0;
}
选择排序
基本介绍
-
每轮排序会从后面的所有元素中寻找一个最小的元素出来,然后与已经排序好的下一个位置进行交换
-
动画演示:https://visualgo.net/zh/sorting
代码实现
// C#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 选择排序
void selectSort(int* arr, int size)
{for (int i = 0; i < size - 1; i++){int min = i; // arr[min]能访问最小元素// 内部循环for (int j = i + 1; j < size; j++){if (arr[min] > arr[j]) min = j; // 更新下标}// 经过内部循环后,此时 arr[min] 访问的一定是最小元素int temp = arr[i];arr[i] = arr[min];arr[min] = temp;}
}// 选择排序优化版:双选择排序
// 1. 交换函数
void swap(int* a, int* b)
{int temp = *a;*a = *b;*b = temp;
}// 2. 双选择排序
void twoSelectSort(int* arr, int size)
{// 设定最开始的范围为[0, size - 1], 每循环一轮后,left++, right--,缩小范围int left = 0, right = size - 1;// 每循环一轮,就缩小范围while (left < right){int min = left, max = right; // 假定当前范围内,最小数的下标为左边界的那一个,最大数的下标为右边界的那一个for (int i = left; i <= right; i++) // 从当前的左边界一直遍历到当前的有边界,遍历过程中,记录最小数和最大数的下标{if (arr[i] < arr[min]) min = i; // arr[i] 在不断变化的过程中,如果小于我们最开始假定的 arr[min] 最小值,就马上更新当前最小值的下标 min,从而记录了当前最新的最小值 arr[min]if (arr[i] > arr[max]) max = i; // arr[i] 在不断变化的过程中,如果小于我们最开始假定的 arr[max] 最大值,就马上更新当前最小值的下标 max,从而记录了当前最新的最大值 arr[max]}// for 循环一轮过后,当前 arr[min] 和 arr[max] 存放的就是,这一轮 [left, right] 范围中的最小值和最大值swap(&arr[max], &arr[right]); // 让当前最大值 arr[max] 和 我们假定的最大值 arr[right] 进行交换if (min == right) min = max; // 如果上面的要被交换的 arr[right] 刚好是本轮的最小值 arr[min],那么发生交换后,arr[max] 里面存放的才是我们最开始的 arr[min],所以我们需要更新 minswap(&arr[min], &arr[left]); // 让当前最小值 arr[min] 和 我们假定的最小值 arr[left] 进行交换left++; // 缩小范围right--; // 缩小范围}
}// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = { 7, 3, 5, 9, 2, 0, 6, 1, 4, 8};int arrSize = 10;show(arr, arrSize);// 选择排序// selectSort(arr, arrSize); // 选择排序twoSelectSort(arr, arrSize); // 双选择排序show(arr, arrSize);getchar();return 0;
}
进阶排序
| 排序算法 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | 不稳定 |
| 希尔排序 | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
快速排序 (要求熟练)
基本概念
-
快速排序是冒泡排序的进阶版本
-
在冒泡排序中,进行元素的比较和交换是在相邻元素之间进行的,元素每次交换只能移动一个位置,所以比较次数和移动次数较多,效率相对较低
-
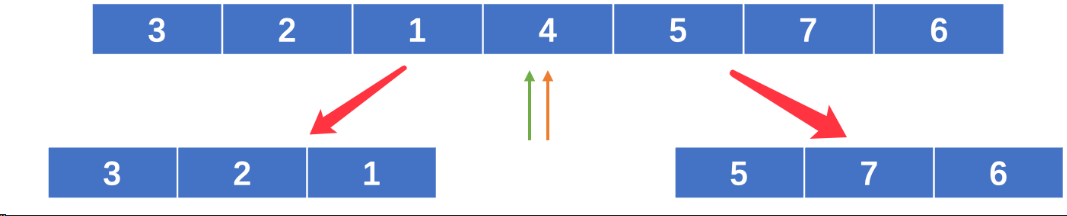
而在快速排序中,元素的比较和交换是从两端向中间进行的,较大的元素一轮就能够交换到后面的位置,而较小的元素一轮就能交换到前面的位置,元素每次移动的距离较远,所以比较次数和移动次数较少,就像它的名字一样,速度更快
代码实现
图1:
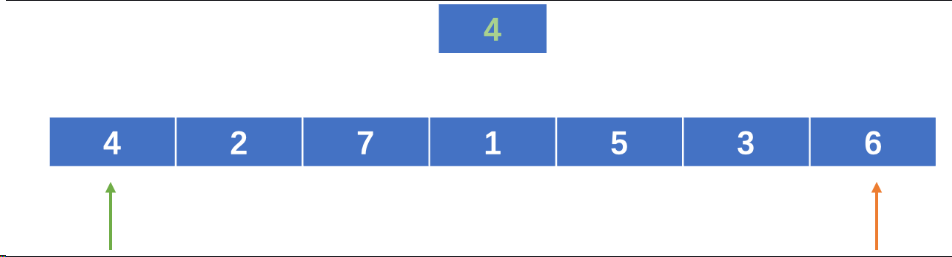
图2:
代码:
// C#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 快速排序
void quickSort(int* arr, int start, int end)
{// 结束递归if (start >= end) return;// ------------------------ 快速排序算法逻辑主体 ------------------------int leftPointer = start, rightPointer = end; // 定义一对左右指针,方便待会标记int reference = arr[leftPointer]; // 选定参考值while (leftPointer < rightPointer) // 两个指针不相遇才能进行循环{// 从右边开始,一直向左边寻找,直到找到比参考值小的数,将这个数移动到 arr[leftPointer]while (leftPointer < rightPointer && arr[rightPointer] >= reference) rightPointer--;arr[leftPointer] = arr[rightPointer];// 从左边开始,一直向右边寻找,直到找到比参考值大的数,将这个数移动到 arr[rightPointer]while (leftPointer < rightPointer && arr[leftPointer] <= reference) leftPointer++;arr[rightPointer] = arr[leftPointer];}// 退出循环,说明两个指针相遇,说明此时 leftPointer = rightPointerarr[leftPointer] = reference; // 或者 arr[rightPointer] = reference; 两个都一样// 继续递归下去quickSort(arr, start, leftPointer - 1);quickSort(arr, rightPointer + 1, end);
}// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = { 7, 3, 5, 9, 2, 0, 6, 1, 4, 8 };int arrSize = 10;show(arr, arrSize);// 快速排序quickSort(arr, 0, arrSize - 1);show(arr, arrSize);getchar();return 0;
}
希尔排序
基本介绍
-
希尔排序又叫缩小增量排序
-
希尔排序是插入排序的进阶版本
-
希尔排序对插入排序进行改进,它会对整个数组按照步长进行分组,优先比较距离较远的元素
-
这个步长是由一个增量序列来定的,这个增量序列十分重要
代码实现
// C#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 希尔排序
void shellSort(int arr[], int size) {int delta = size / 2;while (delta >= 1) {// 这里依然是使用之前的插入排序,不过此时需要考虑分组了for (int i = delta; i < size; ++i) { // 我们需要从delta开始,因为前delta个组的第一个元素默认是有序状态int j = i, tmp = arr[i]; // 这里依然是把待插入的先抽出来while (j >= delta && arr[j - delta] > tmp) {// 注意这里比较需要按步长往回走,所以说是j - delta,此时j必须大于等于delta才可以,如果j - delta小于0说明前面没有元素了arr[j] = arr[j - delta];j -= delta;}arr[j] = tmp;}delta /= 2; // 分组插排完事之后,重新计算步长}
}// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = { 7, 3, 5, 9, 2, 0, 6, 1, 4, 8 };int arrSize = 10;show(arr, arrSize);// 快速排序shellSort(arr, arrSize);show(arr, arrSize);getchar();return 0;
}
堆排序
基本认识
- 堆排序也是选择排序的一种,但是它能够比直接选择排序更快
- 对于一棵完全二叉树,树中父亲结点都比孩子结点小的我们称为小根堆(小顶堆),树中父亲结点都比孩子结点大则是大根堆
- 得益于堆是一棵完全二叉树,我们可以很轻松地使用数组来进行表示
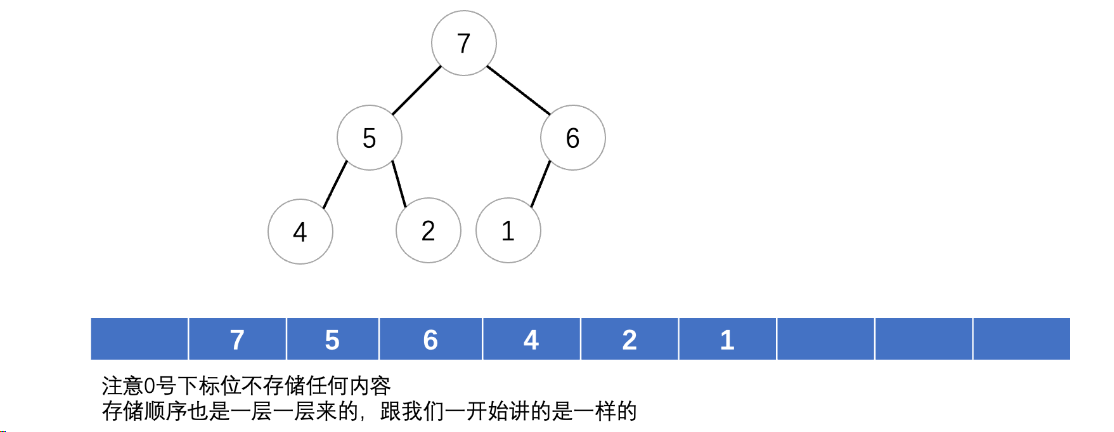
// C#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>// 输出数组中的内容
void show(int* arr, int size)
{for (int i = 0; i < size; i++){printf("%d ", arr[i]);}printf("\n");
}// 堆
typedef int E;
typedef struct MinHeap {E* arr;int size;int capacity;
} *Heap;// 初始化堆
bool initHeap(Heap heap) {heap->size = 0;heap->capacity = 10;heap->arr = (E*)malloc(sizeof(E) * heap->capacity);return heap->arr != NULL;
}// 插入元素
bool insert(Heap heap, E element) {if (heap->size == heap->capacity) return false;int index = ++heap->size;while (index > 1 && element < heap->arr[index / 2]) {heap->arr[index] = heap->arr[index / 2];index /= 2;}heap->arr[index] = element;return true;
}// 删除元素
E remove(Heap heap) {E max = heap->arr[1], e = heap->arr[heap->size--];int index = 1;while (index * 2 <= heap->size) {int child = index * 2;if (child < heap->size && heap->arr[child] > heap->arr[child + 1])child += 1;if (e <= heap->arr[child]) break;else heap->arr[index] = heap->arr[child];index = child;}heap->arr[index] = e;return max;
}int main() {int arr[] = { 3, 5, 7, 2, 9, 0, 6, 1, 8, 4 };int arrSize = 10;show(arr, arrSize);struct MinHeap heap; // 创建堆initHeap(&heap); // 初始化堆for (int i = 0; i < 10; ++i){insert(&heap, arr[i]); // 直接把乱序的数组元素挨个插入}for (int i = 0; i < 10; ++i){arr[i] = (int)remove(&heap); // 然后再一个一个拿出来,就是按顺序的了}show(arr, arrSize);getchar();return 0;
}