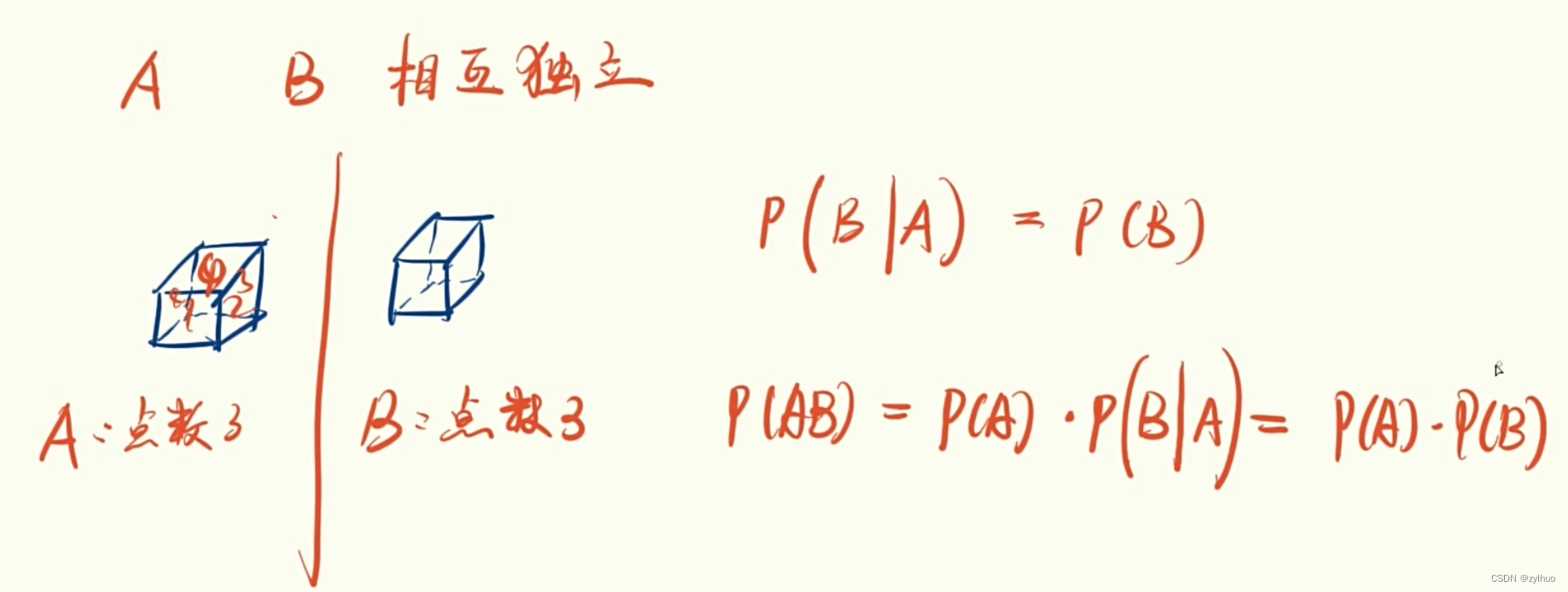redis集群中为了防止主机宕机导致集群瘫痪,引入了哨兵集群,哨兵集群通过实时监控主机是否正常运行,并且在主机出现故障时及时将另一个满足条件的从机变为新的主机以保证redis集群正常运转,那这一过程具体发生了什么呢?
首先,哨兵集群是如何对redis集群的主机实现监控的呢?
哨兵集群的每个节点会固定周期的向主机发送ping指令,等待主机相应,一旦主机超过既定时间未响应,则该哨兵节点则认定该主机为主观下线(主观下线的意思是,当前节点主观认为该主机故障无法响应,但仍然不能确定是否真的是主机故障,也有可能是当前哨兵节点所处网络环境不好,或者其他原因),当认为主机为主观下线的哨兵节点数量达到quorum数量时(quorum是哨兵配置文件中配置的,通常设置为所有哨兵节点数量的一半以上),则认为该主机为客观下线(客观下限是达到配置文件中既定数量的哨兵节点认为该主机为下线状态,则判定主机确实是出故障了),这时候就会开始选举新的主机。
在挑选新的主机之前,首先哨兵集群要先选举一个老大来负责发送命令选举新的主机,选举过程中,哨兵集群会进行投票,哨兵节点会观察哪个节点的票最多,如果有一个节点的票最多,则会投票给该节点,如果没有得票的节点,则会投票给自己,换句话说,谁先投票,谁就会被选举为哨兵集群的老大,而最先发起投票的通常是最先发现主机客观下线的,这样来说,其实就是第quorum个发现主机主观下线的哨兵节点,会当选哨兵集群老大。
选举完哨兵集群老大后,该节点会继续根据一些规则选举新的主机
1. 首先判断主机与从机断开时间长短,如果超过指定值( down-after-milliseconds * 10 )则会
排除该从机
2. 然后在判断从机配置中的 slave-priority 值,越小优先级越高,如果是 0 则永不参与选举(通常这个值是相等的)
3. 如果 slave-prority 一样,则判断 slave 节点的 offset 值,越大说明数据越新,优先级越高
4. 如果依然相等,则是判断 从机的 id 大小,越小优先级越高。
其实这些条件都在保证从机的数据尽可能的新,最后通过id是确保能够选出来一个作为主机(并不是id越小,数据越新)
当确认新主机后,哨兵集群老大会首先向新主机发送 slaveof no one 命令让其脱离从机身份变成主机,然后在向其他从机发送 slaveof 新主机ip 命令让其他从机跟随新的主机同数据,最后将之前的主机ip标记为从机,当旧主机正常运行时则会变为新主机的从机。
这样一个主机发生故障,哨兵集群发挥作用的流程就结束了。