一、什么是Zookeeper
Zookeeper 是一个分布式应用程序的协调服务,它提供了一个高性能的分布式配置管理、分布式锁服务和分布式协调服务。它是 Apache 软件基金会的一个项目,被设计用来处理大规模的分布式系统中的一些关键问题。
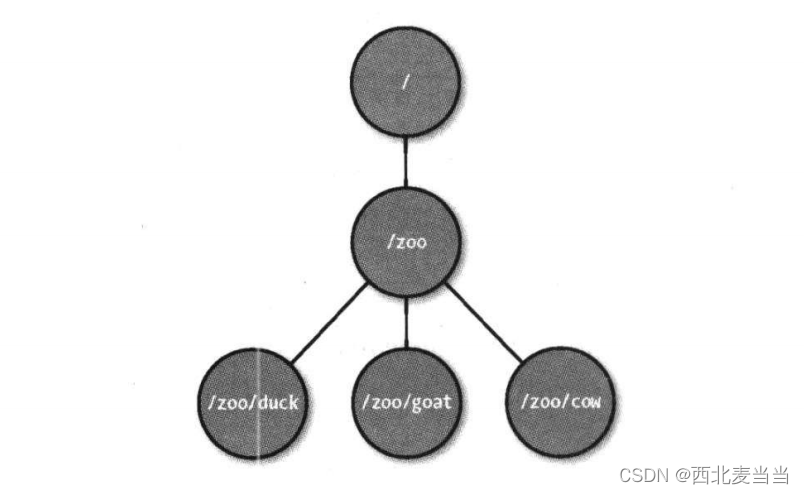
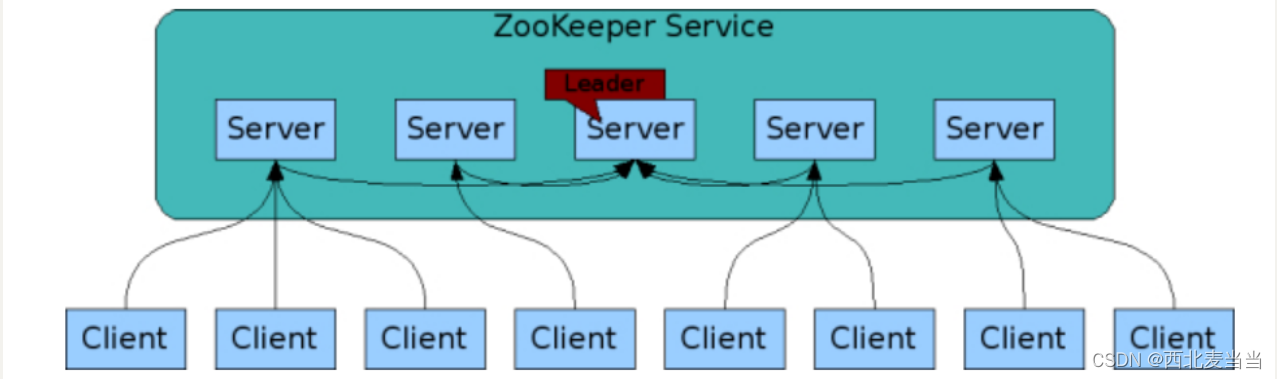
Zookeeper的组成员关系:
二、Zookeeper重要特性和功能
-
分布式配置管理:Zookeeper 允许开发人员存储和管理应用程序的配置信息,这些配置信息可以在分布式环境中共享和同步。
-
命名服务:Zookeeper 提供了一个层次化的命名空间,开发人员可以利用这个命名空间来注册、查找和管理分布式系统中的各种资源。
-
分布式队列:Zookeeper 提供了一些原语,使得开发人员可以基于 Zookeeper 实现分布式队列,用于协调和通信。
-
集群管理:Zookeeper 本身就是一个高可用、高可靠的分布式系统,可以用于监控和管理集群中的节点状态和健康状况。
-
Watch 机制:Zookeeper 提供了 Watch 机制,允许客户端在节点状态发生变化时得到通知,从而可以实现事件驱动的编程模型。
-
原子性操作:Zookeeper 提供了一些原语,如创建、删除节点等操作都是原子性的,保证了分布式系统的一致性。
-
高性能:Zookeeper 的设计目标之一是提供高性能的服务,它采用了一些优化手段,如内存中数据的存储和快速的数据同步算法,以提供低延迟和高吞吐量。
三、Zookeeper运行机制
-
集群模式:ZooKeeper 以集群的形式运行。一个 ZooKeeper 集群通常由多个服务器节点组成,这些节点分布在不同的机器上,它们通过网络进行通信和协作。
-
Leader-Follower 架构:ZooKeeper 集群中的服务器节点采用 Leader-Follower 架构。在集群启动时,会选举出一个节点作为 Leader,其他节点则成为 Followers。Leader 负责处理客户端的写操作,并将更新操作复制给 Followers,而 Followers 则负责处理客户端的读操作。
-
数据存储:ZooKeeper 使用内存数据库来存储数据,并将数据持久化到磁盘上的事务日志中,以确保数据的持久性和一致性。数据存储在树状的命名空间中,每个节点称为 ZNode。
-
原子性操作:ZooKeeper 提供了一系列原子性的操作,如创建节点、删除节点、读取节点、更新节点等。这些操作要么全部成功,要么全部失败,从而确保了数据的一致性。
-
Watch 机制:ZooKeeper 提供了 Watch 机制,允许客户端注册 Watcher 来监视节点状态的变化。当节点状态发生变化时,ZooKeeper 会通知客户端,从而实现了事件驱动的编程模型。
-
客户端与服务器交互:客户端与 ZooKeeper 服务器之间通过 TCP 连接进行通信。客户端可以向任意一个 ZooKeeper 服务器发送请求,该服务器将请求转发给 Leader,Leader 处理请求后将结果返回给客户端。
-
快速的数据同步算法:ZooKeeper 使用了一种快速的数据同步算法,使得数据在集群中的复制和同步非常迅速,从而保证了系统的高性能和可用性。

四、Zookeeper操作细节
4.1、Zookeeper服务的操作
-
连接到 ZooKeeper 服务:在使用 ZooKeeper 之前,首先需要建立与 ZooKeeper 服务的连接。这可以通过 ZooKeeper 客户端库提供的连接函数来实现。连接函数通常包括 ZooKeeper 服务器的主机名和端口号等参数。
-
创建节点:可以使用 ZooKeeper 提供的 create() 函数来创建一个新的节点(ZNode)。在创建节点时,可以指定节点的路径、数据和节点类型等参数。
-
读取节点:可以使用 ZooKeeper 提供的 getData() 函数来读取指定节点的数据。通过这个函数可以获取节点的数据内容以及节点的元数据信息。
-
更新节点:可以使用 ZooKeeper 提供的 setData() 函数来更新指定节点的数据。通过这个函数可以修改节点的数据内容,同时还可以指定版本号来实现乐观并发控制。
-
删除节点:可以使用 ZooKeeper 提供的 delete() 函数来删除指定节点。删除节点时,可以选择是否递归删除其所有子节点。
-
检查节点是否存在:可以使用 ZooKeeper 提供的 exists() 函数来检查指定节点是否存在。通过这个函数可以判断节点是否存在以及节点的元数据信息。
-
获取子节点列表:可以使用 ZooKeeper 提供的 getChildren() 函数来获取指定节点的子节点列表。通过这个函数可以遍历和查看节点的子节点。
-
监听节点变化:可以使用 ZooKeeper 提供的 Watch 机制来监听指定节点的状态变化。通过注册 Watcher,客户端可以在节点状态发生变化时得到通知。
-
释放连接:在使用完 ZooKeeper 服务后,需要调用 ZooKeeper 客户端库提供的关闭函数来释放与 ZooKeeper 服务的连接。


4.2、Zookeeper服务一致性
ZooKeeper 通过实现强一致性来保证数据的一致性。这意味着在任何给定时间点,所有连接到 ZooKeeper 的客户端都会看到相同的数据视图。以下是 ZooKeeper 服务一致性的几个关键点:
-
原子性操作:ZooKeeper 提供了一系列原子性的操作,如创建节点、删除节点、更新节点等。这些操作要么全部成功,要么全部失败,从而确保了数据更新的原子性。
-
顺序一致性:ZooKeeper 提供了顺序一致性的保证,即对于每个更新操作,都可以按照相同的顺序被所有客户端观察到。这意味着在 ZooKeeper 中,操作的执行顺序是确定的,不会出现数据的乱序问题。简要来说就是:来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将znodez的值更新为a,在之后的操作中,它又将z的值更新为b,则没有客
户端能够在看到z的值是b之后再看到值a(如果没有其他对z的更新)。 -
单一系统映像:一个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有状态滞后于故障服务器的服务器都不会接受该连接请求,除非这些服务器将状态更新至故障服务器的水平。
-
持久性:ZooKeeper 使用事务日志来持久化数据更新操作。所有的写操作都会先写入事务日志,然后再应用到内存数据库中。通过这种方式,即使节点故障或重启,数据也不会丢失。
-
多数派原则:ZooKeeper 集群中的写操作必须得到大多数节点的确认才算成功。这种多数派原则保证了数据的一致性和可靠性,即使集群中的部分节点出现故障,仍然能够保证数据的一致性。
-
及时性:任何客户端所看到的滞后系统视图都是有限的,不会超过几十秒。这意味着与其允许一个客户端看到非常陈旧的数据,还不如将服务器关闭,强迫该客户端连接到一个状态较新的服务器。