软链接
我们先学习一下怎样创建软链接文件,指令格式为:ln -s 被链接的文件 生成的链接文件名
我们可以这样记忆:ln是link的简称,s是soft的简称。
我们在下面的图片中就是给test文件生成了一个软链接mytest:
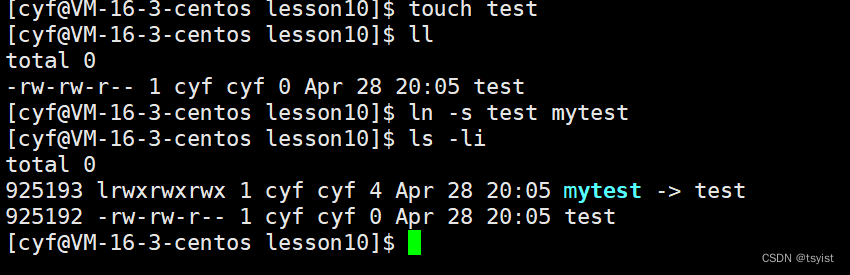
我们来解释一下图片上每一行中各部分的意义:

在使用ls命令时,加上-i的选项就可以在第一行查看文件的inode,这里我们可以看到我们的软链接文件和原本的文件的inode不同,也就是说我们的软链接文件有自己的inode,并且软链接文件和原有文件的属性也不一致,例如我们原本文件权限为0664,文件大小为0,我们的软链接文件权限则为0777,文件大小为4。这说明我们创建软链接文件时操作系统会给我们创建一个新的文件,这个文件有自己的属性和inode,但是如果我们执行这两个文件的话,二者的执行结果是一致的。例如我们将test编译成一个打印"hello world"的程序。执行两个文件得:

软链接的应用
其实软链接就类似于windows下的快捷方式,可以便利我们的使用。例如一个情况:我们在其他目录下有一个文件需要在当前目录下调用,如果不用软链接的话,我们就需要./一串路径来调用,很麻烦,如果我们使用软链接的方式连接到该可执行文件,就很方便了。例如下面的代码:
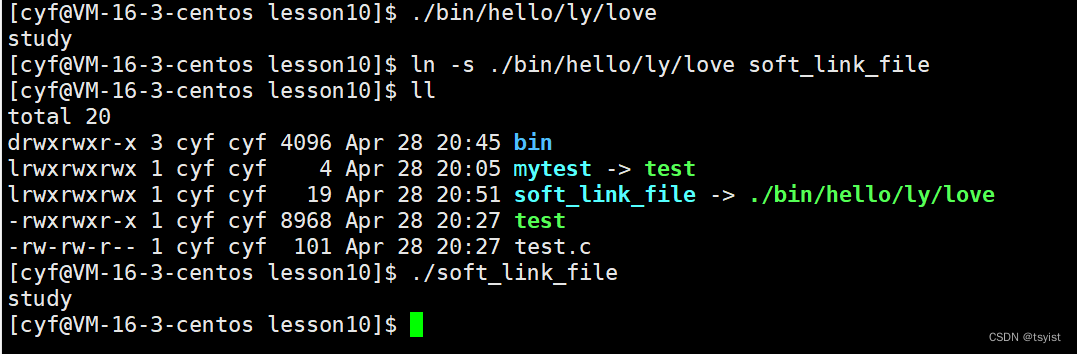
我们在当前目录下,创建一连串目录,在最里面的子目录创建了一个可执行文件love,他的功能是打印一个study。如果我们想在当前目录下执行love的话,我们就需要带上一长串路径,但是我们创建一个软链接链接到love的话,我们只需要执行链接文件即可。这就是软链接的作用。
硬链接
相比软链接,硬链接要说的知识会多很多。
我们先来看创建硬链接的操作:ln 原文件名 链接文件名
也就是我们创建链接文件时不加-s,创建的链接文件就是硬链接文件,如下图:
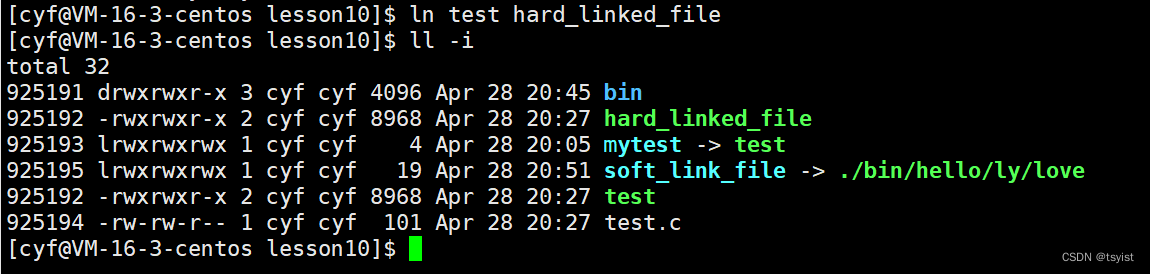
我们仔细观察会发现硬链接于与软链接的不同:
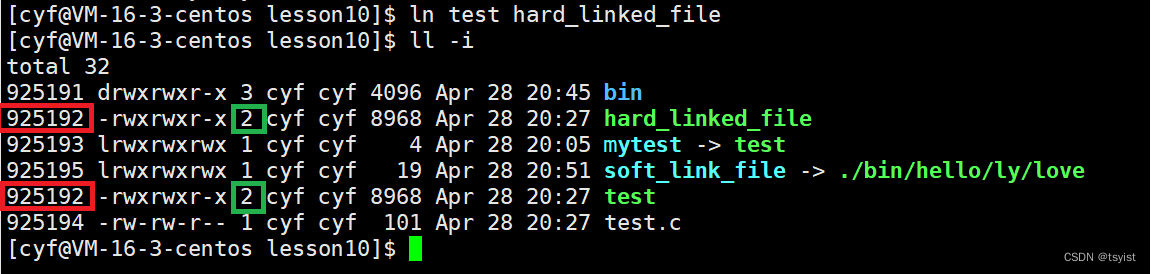
红色圈住的是文件的inode,我们可以看到原文件和硬链接文件inode一致,软硬链接最根本的区别就是:是否有各自独立的inode。绿色的是文件的硬链接数,也就是有几个文件名对应这一个inode,硬链接数为2,也就代表有两个文件名指向了这同一个inode。
我们一对比就能发现:软链接有属于自己的inode,所以软链接是一个独立的文件。而硬链接并没有独立的inode,所以他并不能被当作独立的文件看待。在创建硬链接文件时,并没有创建新文件,因为他并没有分配独立的inode,他用的是原文件的inode和内容。我们在上篇文章讲过目录的数据块记录着文件名和inode的映射关系,创建硬链接的本质就是在目录的数据块中添加一个文件名,并使这个文件名指向原文件的inode,所以一个inode可能会被多个文件名所指向。因此为了记录一个inode被多少个文件名所指,在inode内有一个计数器,当有一个文件名指向该inode时,计数器加1,这个就是我们的硬链接数,也就是我们上图中绿色圈住的部分。
既然链接文件名和原文件名都指向同一个inode,我们可以试着删除掉其中一个文件,看看会发生什么,这里我们把原文件删掉,结果如下:

我们会发现软链接文件mytest标红,一直闪烁着红色表示警告。而对硬链接文件来说,并没有受什么影响,功能及属性都没变,只有硬连接数变了,由2变为了1,也就是说我们刚才删除了原文件并不是真的删除了文件,而是将目录数据块中记录的原文件名字与inode映射关系删除了,硬链接文件名和inode的映射关系仍在。只有当一个文件的硬连接数为0才是真正的删除了一个文件,其余的只是删掉一个映射关系,计数器减一。
这也侧面说明了软链接不是通过inode找到文件的,而是通过文件名来找文件的,由于文件之间都是树状结构连接起来的,在树状结构中查找一个文件名的方式是通过绝对路径或相对路径,所以软链接文件的数据块中保存的是原文件的路径,这也就是问什么删除原文件名软链接会发警报的原因。
硬链接的补充
我们会发现创建一个普通文件时,硬连接数都是1,这很正常没问题。但是在创建一个目录文件时,硬链接数是2,而且若在目录下再创建目录文件的话,多创建一个目录文件,上层目录的硬链接数就会加1。原因就是创建目录文件时,目录文件下会自动生成 .和..两个隐藏文件。

这里bin是一个目录文件,其下就会有.和..两个文件,其中.指向目录自己,..指向目录的上层目录。
其实就是.文件映射的inode也是目录自己的inode,..文件映射的inode是上层目录的inode。所以硬连接数就会增加。
硬链接的目的
就是让多个不在同一目录下或者在同一目录下的文件,能够同时修改同一文件,其中一个修改后,所有与其硬连接的文件一起修改了。
文件的三个时间
我们可以通过 stat 文件名 的方式查看对应文件的信息:
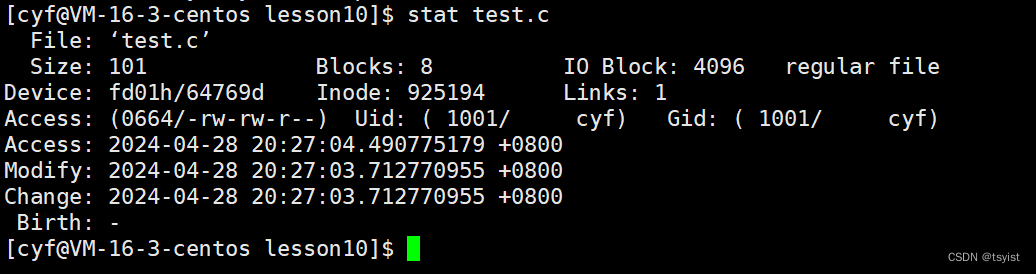
信息中包含了三个时间:
- Access: 文件最后被访问的时间。
- Modify: 文件内容最后的修改时间。
- Change: 文件属性最后的修改时间。
当我们修改文件内容时,文件属性一般也会修改,所以modify修改时也会带着change时间一起修改。至于access时间,在以前老版本的时候,是只要访问文件后,该时间就会修改。但是在实际中访问文件的场景比修改文件的场景多很多,每次访问文件都要修改时间的话就很拉低效率,例如:我们总是cat一个文件,如果每次cat后都要更新时间的话真的太浪费时间了,所以在Linux2.6以后,只有真正的有效访问或者多次访问后才会刷新。
在我们使用make和makefile的时候,make会主动检测源文件是否做了修改,如果源文件没有被修改就不会重新编译,其中make就是通过文件的modify更改时间来判断源文件是否做了修改,若做了修改,源文件的修改时间是会比可执行文件的修改时间晚的。这就是时间在make上所做的应用。