论文地址:https://arxiv.org/pdf/2404.08189
原文地址:rag-hallucination-structure-research-by-servicenow
在灾难性遗忘和模型漂移中,幻觉仍然是一个挑战。
2024 年 4 月 18 日
灾难性遗忘: 这是在序列学习或连续学习环境中出现的问题,其中一个模型被训练来执行多个任务,但是学习新任务时会导致模型在先前学习的任务上的性能显著下降。这种情况通常发生在神经网络等参数化模型中,因为模型在训练新任务时调整了其参数,从而破坏了之前学习的知识。灾难性遗忘是终身学习和持续学习的一个重要挑战。
模型漂移: 这是指模型在部署后,由于输入数据的分布发生变化,模型的性能随时间下降的现象。这种分布变化可能是由于真实世界的变化(例如,季节性变化、经济波动、社会行为变化等)或数据收集过程的变化(例如,传感器校准问题、数据来源变化等)。模型漂移要求模型能够适应新的数据分布,否则模型的预测可能变得不准确或不相关。

介绍
这项研究之所以如此有趣,是因为 ServiceNow 有一个他们想要解决的实际问题,他们通过这篇论文分享了他们的发现。
其次,本文考虑了LLMs创建结构化输出的挑战,这些输出实际上是为了创建非结构化会话输出。
在某种程度上,这种方法强烈地让人想起OpenAI的JSON模式输出,或者OpenAI的函数调用。
ServiceNow 希望部署企业应用程序,将自然语言的用户需求转换为工作流程。他们制定了一项计划,通过利用 RAG 来提高生成的结构化流程的质量。
这种方法减少了幻觉并允许out-of-domain设置。
ServiceNow 希望根据自然语言输入创建准确的工作流程,以尝试简化用于创建工作流程并为新手提供支持的用户界面。
虽然可以为每个企业微调大型语言模型(LLM),但由于微调大型语言模型所需的基础设施成本高昂,这可能是过于昂贵的。在部署大型语言模型时,还需要考虑它们的占用空间,使得部署能够完成任务的最小型大型语言模型更为可取。
《剑桥词典》选择“hallucinate”作为 2023 年年度词汇。
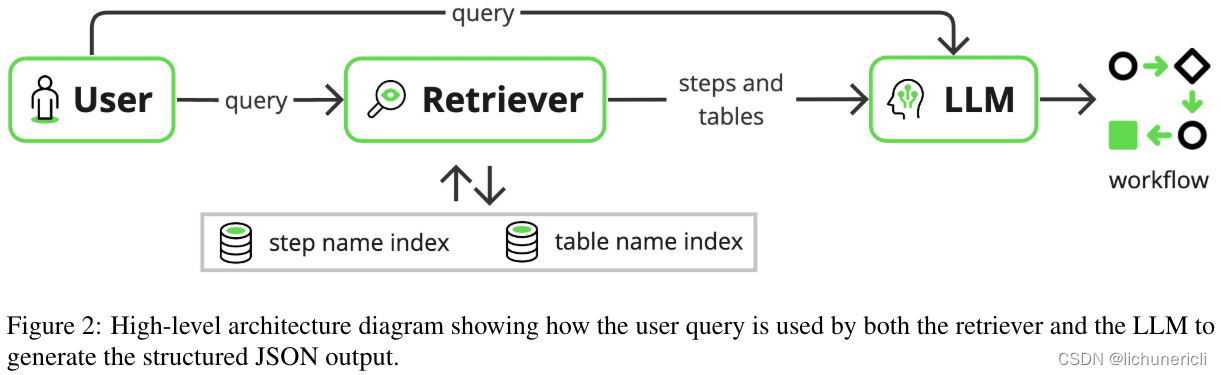
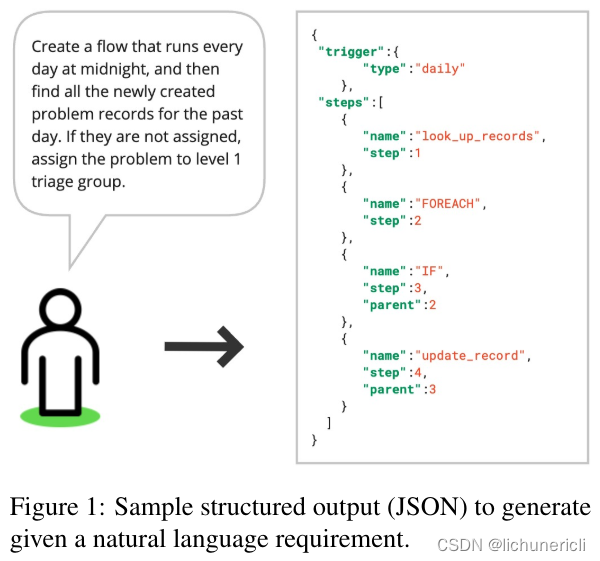
如下图所示,输出工作流表示为 JSON 文档,其中每个步骤都是一个 JSON 对象。
该研究展示了 RAG 如何允许在使用非常小的检索器模型的同时部署较小的LLM,而不会损失性能。
RAG 用于结构
这项研究的不同之处在于,利用 RAG 以 JSON 的形式创建结构化输出。在某种程度上,这种方法强烈地让人想起OpenAI的JSON模式输出,或者OpenAI的函数调用。
然而,这种实现的挑战在于,即使输入是开放的,并且通过图形用户界面提示进行了高度指定,输出也只能形成有限的、有限的步骤池的一部分。
- 在创建此工作流程时,ServiceNow 首先必须训练检索器编码器以使自然语言与 JSON 对象保持一致。
- 其次,他们通过将检索器的输出包含在其提示中,以 RAG 方式训练LLMs。
因此,需要检索器将自然语言映射到现有步骤和数据库表名称。
该研究的重点是微调检索器模型,原因有两个:改进文本和 JSON 对象之间的映射,以及创建应用程序域的更好表示。
方法论
- 检索器训练:训练一个检索器模型,使其能够将自然语言查询映射到现有的工作流步骤和数据库表名。使用对比损失和不同的负采样策略来优化检索器的性能。
- LLM训练:独立训练LLM,将检索器的输出作为LLM的输入提示的一部分,以便LLM在生成过程中可以复制相关的JSON对象。
- 系统架构:描述了RAG系统的高层架构,包括初始化步骤和用户请求的处理流程。
- 评估指标:触发器精确匹配(EM)、步骤袋(BofS)和幻觉步骤/表格(HS/HT)。
注意事项
为未来的工作提出了一些考虑因素:
- 将结构化输出格式从 JSON 更改为 YAML 以减少令牌数量。
- 利用推测解码
- 逐步向用户回传流,而不是整个生成的工作流程。这与 LlamaIndex 最近的代理发展是一致的,其中对代理采取了逐步的方法。采用“human-in-the-loop”方法有很多优点,在代理上下文中的 HITL 部分中,人可以与其他工具一起被视为代理工具。
最后
该研究提出了一种使用检索增强语言模型(RAG)来解决人工智能中的两个关键挑战的策略:
- 减少幻觉(产生不正确或不相关的信息)
- 在结构化输出任务中实现泛化(将知识应用到新情况的能力)。
该研究强调了减少现实世界人工智能系统的幻觉以获得用户接受的重要性。
他们强调,RAG 方法允许在资源受限的环境中部署人工智能系统,因为即使是小型检索器和紧凑的语言模型,它也可以有效地工作。
这意味着系统的硬件和计算要求可以最小化,这对于资源有限的环境中的实际应用至关重要。
此外,该研究还指出了未来研究的领域,表明可以通过加强检索器和语言模型之间的协作来进一步改进。
这可以通过联合训练方法来实现,即两个组件一起训练以改善它们的交互,或者通过设计一个模型架构来促进两个组件之间更好的集成和合作。