一、背景(tidb8.0社区版)
信创背景下不多说好吧,从资料上查tidb和OceanBase“兼容”(这个词有意思)的比较好。
其实对比了很多数据库,有些是提供云服务的,有些“不像”mysql,综合考虑下用tidb
这种环境的特点:需要本地部署在内网环境上
二、安装
安装前说明:
mysql大多数都是单机安装,加一个主从,tidb是支持分布式部署的,本篇就说下单机部署,分布式部署不细说(其实也就是配置文件多加几个节点)
支持分布式说明对机器资源需求高,客户不差机器,本地测试差,相对于mysql来说对机器的需求还是高点的,cpu核数和内存不够容易卡死。
由于之前的机器卡死之后,我用了一台8核16G的,运行起来我发现加上系统占用内存占用3G多(还没导入数据)建议内存最低4G-8G吧,再低没法用了。
安装官方文档
https://docs.pingcap.com/zh/tidb/stable
和官方文档结合看吧,官方文档说的模式多,容易迷糊
正文开始:
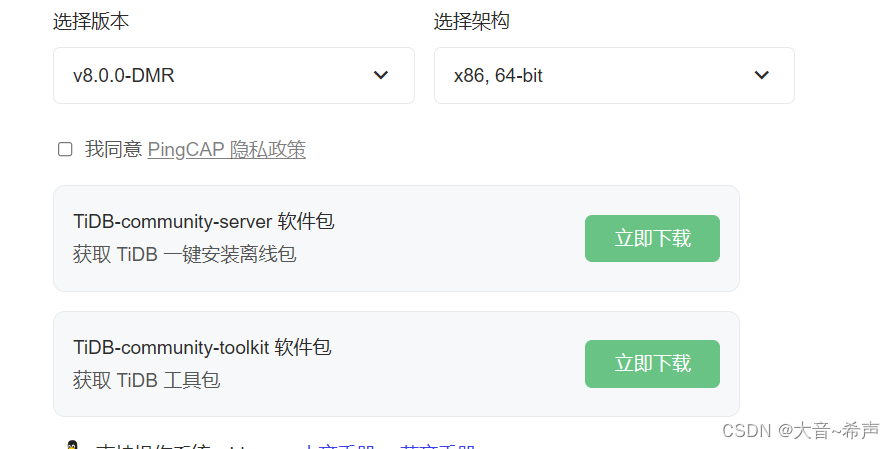
1、下载包
https://cn.pingcap.com/product-community/
tidb-community-server-v8.0.0-linux-amd64.tar.gz
tidb-community-toolkit-v8.0.0-linux-amd64.tar.gz
2、命令安装
# 创建文件,将两个包上传
mkdir -p /data/tidb
cd /data/tidb
tar xzvf tidb-community-server-v8.0.0-linux-amd64.tar.gz
# 安装
sh tidb-community-server-v8.0.0-linux-amd64/local_install.sh
#local_install.sh 脚本会自动执行 tiup mirror set tidb-community-server-${version}-linux-amd64 命令将当前镜像地址设置为 tidb-community-server-${version}-linux-amd64
# 所以需要刷新一下,官方文档是创建tidb用户进行操作,我是直接在root下装的
# 安装在root用户下,可以去bash_profile这个文件下面看下内容最后是不是多了一行
source ~/.bash_profile
tar xf tidb-community-toolkit-v8.0.0-linux-amd64.tar.gz
ls -ld tidb-community-server-v8.0.0-linux-amd64 tidb-community-toolkit-v8.0.0-linux-amd64
# 进入到文件夹下操作
cd tidb-community-server-v8.0.0-linux-amd64/
cp -rp keys ~/.tiup/
tiup mirror merge ../tidb-community-toolkit-v8.0.0-linux-amd64# 开始写配置文件
# 官网没有下面这步,会报错
tiup cluster
tiup cluster template > topology.yaml
vim topology.yaml
单机部署写一个最简配置就行,其实就是把默认的多余的那几个host删除就行,别的默认就行
user: "tidb"这个不是连接库的用户,我猜测是和注册中心有关系,这里不用关心
tidb_servers这个就是我们要连接的服务,端口默认4000,别的服务不用关心
global:user: "tidb"ssh_port: 22deploy_dir: "/tidb-deploy"data_dir: "/tidb-data"listen_host: 0.0.0.0arch: "amd64"monitored:node_exporter_port: 9100blackbox_exporter_port: 9115pd_servers:- host: 10.10.xx.xxtidb_servers:- host: 10.10.xx.xx# # SSH port of the server.# ssh_port: 22# # The port for clients to access the TiDB cluster.# port: 4000tikv_servers:- host: 10.10.xx.xxtiflash_servers:- host: 10.10.xx.xxmonitoring_servers:- host: 10.10.xx.xxgrafana_servers:- host: 10.10.xx.xxalertmanager_servers:- host: 10.10.xx.xx
#检测一下 (这两步也不知道是干啥的,应该是官方推荐,可以看到能检测出几个fail,不用管。后面这个用户就是当前ssh的用户和密码)
tiup cluster check ./topology.yaml --user root -p
# 自动修复潜在风险
tiup cluster check ./topology.yaml --apply --user root -p
# 部署(这一步注意:tidb-cmcc是你的服务名字,记住这个。)
tiup cluster deploy tidb-cmcc v8.0.0 ./topology.yaml --user root -p
# 部署成功后的提示
# Cluster `tidb-cmcc` deployed successfully, you can start it with command: `tiup cluster start tidb-cmcc --init`#部署成功后可以查看下部署的集群(这只是部署进去了)
tiup cluster list
# 可以查看状态
tiup cluster display tidb-cmcc# 启动分两种
# 1、初始化了一下,成功之后密码在提示里面,记得保存下哈, “The new password is: 'xxxxxxx'.”,后面如果关了服务重复执行也不要紧,只会启动服务,不会重置密码的,因为初始化的逻辑是密码为空的时候才会更改,之前有密码并不会修改
tiup cluster start tidb-cmcc --init
# 2、可以无密码进入root
tiup cluster start tidb-cmcc
# 可以查看状态
tiup cluster display tidb-cmcc
# 停止重启
tiup cluster stop tidb-cmcc
tiup cluster restart tidb-cmcc
3、连接
一般两种方式
服务器上连接:官方推荐用mysql客户端连接(这就是兼容的原因啊),所以需要离线安装个mysql,然后连接就行了
/usr/local/mysql/bin/mysql -h 127.0.0.1 -P 4000 -u root -p
#-h 是指定一个ip地址
#-P(大写) 是指定一个端口
#-u 是用户名
#-p(小写) 是密码
本地连接:就是你的本地电脑工具连接就行了,root默认是外部可连接的,所以只要外部支持,直接用工具连接就行,就当mysql连接,端口4000
4、增加用户
新增业务用户,禁用root用户外部访问
# 创建用户 默认的就是外部可以访问的
CREATE USER IF NOT EXISTS 'cmcc' IDENTIFIED BY 'cmcc_pwd';
# 查看用户列表
select * from user;
# 查到的是默认的root
show grants;
# 查先新建的用户权限
SHOW GRANTS FOR 'cmcc'@'%';
# 新增的用户只有登录权限,但是没有我们业务数据库的权限(已经做了数据迁移,目前示例中有两个库cmcc,cmcc_config)
grant ALL PRIVILEGES on cmcc.* to 'cmcc'@'%';
grant ALL PRIVILEGES on cmcc_config.* to 'cmcc'@'%';
# 不生效就flush privileges;一下,修改权限必须这么操作一下
flush privileges;
# 再查下,已经有数据了,可以连接下看看
SHOW GRANTS FOR 'cmcc'@'%';
# 目前看到有三个库,其中过一个是默认的,回收试一下是回收不掉的,另外两个是可以的,所以不用管
# revoke ALL PRIVILEGES ON `数据库名`.`数据库表` from 'cmcc'@'%'
revoke all privileges on `INFORMATION_SCHEMA`.* from 'cmcc'@'%';# 新账号的事结束了,我们将root限制一下,要是在外部工具操作记得最后操作这个,要不你就连不上了,在服务器操作无所谓
update user set host = "localhost" where user = "root" and host = "%";
flush privileges;5、使用技巧
除了配置之外,sql的使用你就当mysql使用就行了,有些问题搜不到就搜mysql的就行了。
tidb如多当单机使用的话,确实就是mysql,优势还是在分布式上。
三、数据迁移
看了官网的例子,其实更多的还是复杂的数据迁移。
针对mysql迁移,一些工具蛮方便的,如navicat。
或者导出成sql文件,用自带的这个工具导入进去就行了
https://docs.pingcap.com/zh/tidb/stable/migrate-from-sql-files-to-tidb
四、备份
备份还是首推官方备份的方式,用br工具备份,可以在官网看下
由于我下载的版本
# 安装 br The component `br` not found (may be deleted from repository); skipped,源里面没有br,因为是离线的环境,懒得捣鼓了
tiup install br
然后还是采用之前在mysql中备份成sql的方式操作吧(很正式的项目建议不要这么干,显得不专业,并且也不会部署在一个机器上,br分布式备份是比较好用的)并且后面不支持binlog了
# 打开下binlog日志 log_bin OFF
show variables like "log_bin";
#从 TiDB v7.5.0 开始,TiDB Binlog 组件的数据同步功能不再提供技术支持,强烈建议使用 TiCDC 作为数据同步的替代方案。