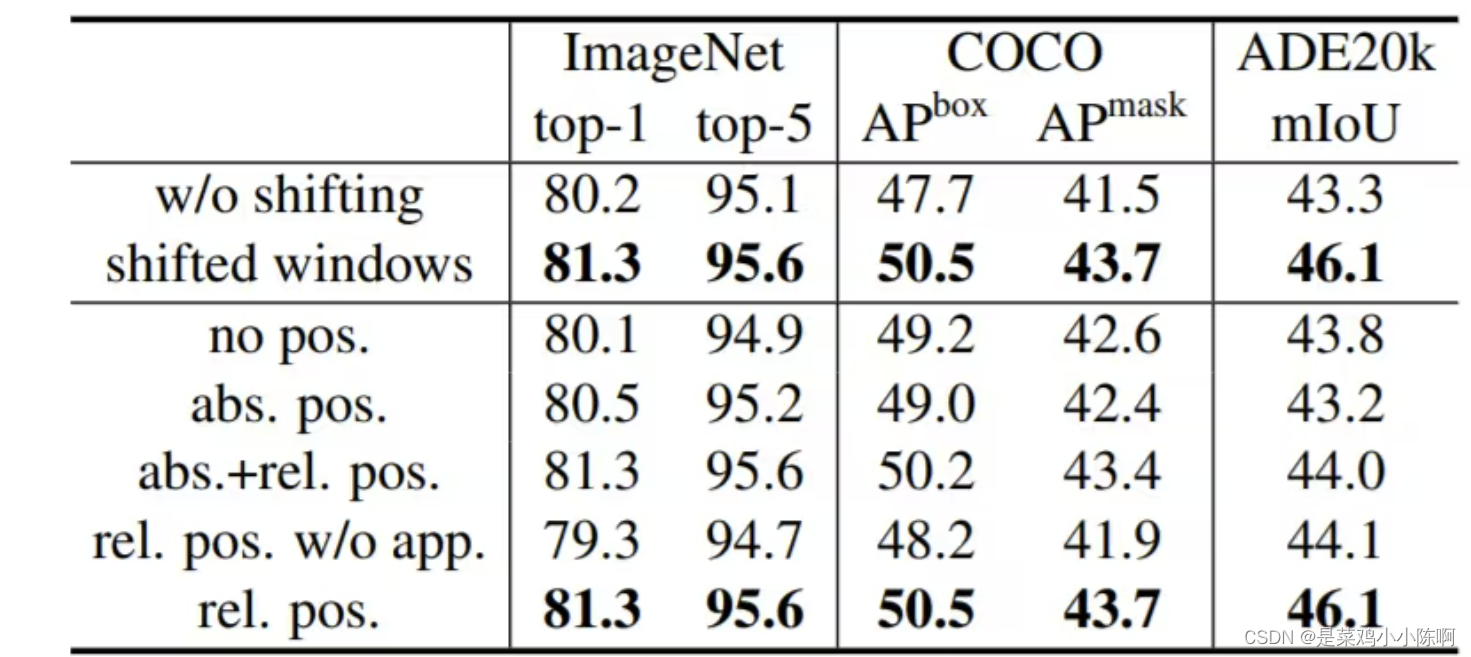
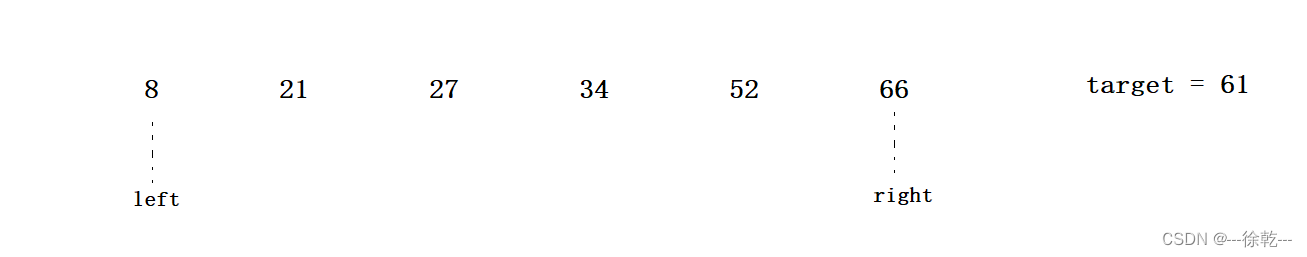前言:
【下面用到的:随机数生成测试排序性能器的代码】
快速排序
快排绝对是所有排序中最麻烦的排序之一,但又是面试中最喜欢考的一种排序算法,因为可以问的细节点很多,面试最喜欢让你手撕快排,快排考查的出现频率差不多等于其他所有排序考查的出现频率之和
总之,快排一定要认真学,争取全部吸收
已下代码讲解都默认升序排序,若暂时看不懂讲解,就多看几遍动图演示,可以帮助理解,自己也试着梳理动图的逻辑,加油!
⭐一、霍尔法快排
前言:最初的快速排序就是 名为霍尔Hoare 的大佬创造的,后人改良版本有章节后面讲解的:挖坑法和前后指针法。现在先学 霍尔法
🐻先考虑单趟
默认以区间最左边的数作为每次该区间快排的 关键字 key
关键字是基准数,最后 L 和 R 相遇后,相遇位置的数据 要和 关键字 key 的数据 a[key] 交换,看动图理解一下
int key_i = L; // key 是记录下标的// 左边找比 key 大的,右边找比 key 小的
while (L < R) { // 注意遇到相等也需要跳过,否则可能会造成死循环:找到的数据需要严格小于或大于// 相等的数据放在左边 or 右边? 在左右都行,相等的最后在一堆就好while(a[R] >= a[key_i]) R--;while(a[L] <= a[key_i]) L++;Swap(&a[L], &a[R]);
}
Swap(&a[R], &a[key_i]);
观察动图,初始以 L 作为 key
左边 L 找比 key 大的,右边 R 找比 key 小的,找到了就停下,若双方都停下就交换,若双方相遇了,则 相遇位置的数据 要和 关键字 key 的数据 a[key] 交换

代码里面两个 while循环,会出现一个极端情况:若序列 一直小于等于 或 大于等于,则 会一直 L++ 或 一直 R—,L 和 R 刹不住车,最后越界
方法:加上限制条件
while(L < R && a[R] >= a[key_i]) R--;
while(L < R && a[L] <= a[key_i]) L++;
🐻再考虑整体
外层的代码就是整体逻辑了,递归分治法解决
递归分治两部曲:1.子问题;2.返回条件
1.子问题:使整个数组区间有序 == 使左区间有序 并且 使右区间有序
2.返回条件是什么:若区间不存在或 L == R 时(即区间只有一个值时)就可以返回
(想了解递归分治的思想和运用:可以看这篇文章【二叉树】第二章:实现二叉树相关函数,感受递归分治的魅力)
排序完当前区间,就递归到 左区间 和 右区间,再进行排序,周而复始下去,这就是递归分治法
// 递归分治法
void QuickSort(int* a, int L, int R) {if (L >= R) return; // 当区间不存在或 L == R 时(即区间只有一个值时)就可以返回了:最小子问题// 因为我们递归到下一层需要传左右区间的 左右边界,则 需要先保存着 初始 L 和 Rint begin = L, end = R;// 单趟排序逻辑:///int key_i = L; // key 是记录下标的// 左边找比 key 大的,右边找比 key 小的while (L < R) { // 这里不要填等于,否则出不来了,死循环while (L < R && a[R] >= a[key_i]) R--;while(L < R && a[L] <= a[key_i]) L++;Swap(&a[L], &a[R]);}Swap(&a[R], &a[key_i]);//key_i = R; // 将当前 L == R 的位置 赋值给 key_i 只是为了使下面写法保持统一罢了// 因为我们递归到下一层需要传左右区间的 左右边界,则 前面就需要先保存着 初始 L 和 RQuickSort(a, begin, key_i - 1); // 左区间:[begin, key_i - 1]QuickSort(a, key_i +1, end); // 右区间:[key_i + 1, end]// 整个区间:[begin, key_i - 1], key_i, [key_i + 1, end]return;
}
⭐1.1.面试官爱考点(1):为什么 key 位置的数据 一定会比 相遇位置数据 更大?
⭐疑问:
回想先前讲过的思路:求升序排序时,左边找比 key 大的,右边找比 key 小的,最后 相遇的位置再 和 a[key] 交换,
要知道,交换放到后面的数据 一定是 比交换到前面的数据要 大的(才满足升序),这就意味着最后一次交换中, key 位置的数据 一定要比 最后 L 和 R 相遇的位置 的数据要大才行,那为什么 key 位置的数据 一定可以保证更大呢???🤨就不会出现更小的情况吗??🤣
⭐答案:让右边的 R 先走,就能保证 相遇位置一定比 key 要小
⭐证明如下:
首先 两者相遇 一定是 其中一个 先停下来,另一个再撞上去的
让 R 先走
则有几种情况:
第一种:R 走,撞上 L :若 R 开始时 一直找不到 比 key 小的位置,R 就会一直走,直到 和 L 在 key 的位置相遇,相当于 key 在原地不动了;
第二种:R 走和停,L走,撞上R:若 R 找到 比 key 小的位置, 则停下,L 再走,若 L 没有找到 大于key 的数,就会和 R 相遇,则相遇位置 就是 R 之前停下的位置,此时 相遇位置数据 是 小于 key 的;
第三种:R 走和停,L 走和停, R 走,撞上 L:若 R 找到 比 key 小的位置后 停下,L 找到 大于key 的数 也停下,此时 L 和 R 会交换,则使当前 L 位置的数据 变成为 小于 key 的数据,R 再走,若 中途一直找不到 比 key 小的位置,则 R 会 和 L 相遇,此时 相遇位置数据 是 小于 key 的
若 L 先走 最后是达不到目标的,自己推理试试😎
对照动图理解理解:两者相遇 就是会出现以上三种可能

⭐总结:R 先走的话,最后相遇的位置一定是 比 key 小的数据
第二种情况中,相遇位置 即 R 选择的位置,R选择的位置就是 比 key 小的数据
第三种情况中,虽然是 R 撞上 L, 但是 L 位置的数据 还是 R 原本选择的位置数据(交换过了)
⭐拓展:若有些题目要求,用 右边做 key,则 让 哪一边先走呢?
让 L 先走 可以保证 相遇位置一定比 key 要大
综上得出结论:先让 远离 key的一端做 key
⭐1.2.面试官爱考点(2):时间复杂度的计算
⭐面试官爱考点:快排的时间复杂度是多少,如何证明?
一般情况时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
最坏情况的时间复杂度为 O ( n 2 ) O(n^2) O(n2)
建议先看这个视频,非常清晰,讲解了 快排的最优情况,最坏情况,平均情况的时间复杂度的计算
D(n):对长度为 n 的数组进行一次分区需要比较的次数
T(n):对长度为 n 的数组进行快排的时间复杂度
T(L1) 和 T(L2) :分别表示对分区后两个区间快排的时间复杂度
则对于整个数组进行快速排序的时间复杂度为:T(n) = D(n) + T(L1) + T(L2)
最优情况:
每次选择的 key 最终位置在 区间二分的位置,即中间,因此 左右区间每次都是平分,元素为 n/2 个


证明:每个 T(n) 都减半后分解式子:最终 到了 $T(n/ 2^k)$ 此时元素剩下一个,就不用比较了,时间 T(1) = 0
则最终式子为: T ( n ) = D ( n ) + 2 1 ∗ D ( n / 2 1 ) + 2 2 ∗ D ( n / 2 2 ) + . . . . + + 2 k − 1 ∗ D ( n / 2 k − 1 ) T(n)=D(n)+2^1*D(n/2^1)+2^2*D(n/2^2)+....++2^{k-1}*D(n/2^{k-1}) T(n)=D(n)+21∗D(n/21)+22∗D(n/22)+....++2k−1∗D(n/2k−1)
因为 整个数组的比较次数为 D(n) = n-1 ,带入式子
化简就可以直接得出 最优情况的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
最坏情况:
即 序列有序或接近有序 ,每次分区都正好将数组分成一个长度为 0 的部分,一个长度为 n - 1的部分
证明和上面同理,详细过程可以看视频讲解

换句话说:若你区间中选择的 key 刚好为区间的 最值,就会出现最坏情况
⭐1.3.面试官爱考点(3):如何规避最坏情况,改进方法有什么?
前言:当序列为随机值顺序,是很难出现最坏情况的!但不得不提防
若你区间中选择的 key 刚好为区间的 最值,就会出现最坏情况,但在随机数中,这个几率相当小
⭐注意:快排使用递归法,当数据量过大时,容易出现栈溢出,因为开辟的函数栈帧过多了
可以试一下:
声明:先使用其他排序,将数组设置成有序的,为了使 快排 可以跑出最坏情况的 O ( n 2 ) O(n^2) O(n2)
测试十万数据量级以上时,快排 直接 栈溢出

在 待排序数据已经有序或接近有序时 ,快排甚至比 插入排序 还要垃圾得多🤣(我们测试一个 万级数据)
【上面用到的:随机数生成测试排序性能器的代码】

因此,待排序数据已经有序或接近有序时,对快排的危害非常大
但是我们又无法提前得知待排序数据是否已经有序或接近有序,
我们怎么拯救快排呢?有如下几种方法
声明:以下两种方法测试的数据量都是有序的
🐻方法一:快排的随机选 key 法
当 数据有序时,此时选择左端或右端作为 key ,会出现下面这样的分区状况,引发最坏情况(因为是最值)

为了规避 最坏情况,就不能 将左右端 作为 key
可以从区间中随机选择一个数作为 key,选不到左右端了,某种程度上规避了 最坏情况
// 选区间中的随机数做 key,将随机数 和 左端交换(模拟 key 原本就是在左边选取的情况)
// 本质还是在左右端选取key(只是key的值变成了 随机数,而不是最值)
int rand_i = rand() % (R - L);
rand_i += L;
Swap(&a[L], &a[rand_i]);int key_i = L;
总代码
// 递归分治法
void QuickSort(int* a, int L, int R) {if (L >= R) return; int begin = L, end = R;// 修改部分如下,其他代码不变///// 选区间中的随机数做 key,将随机数 和 左端交换(模拟 key 原本就是在左边选取的情况)// 本质还是在左右端选取key(只是key的值变成了 随机数,而不是最值)int rand_i = rand() % (R - L);rand_i += L;Swap(&a[L], &a[rand_i]);///int key_i = L;// 左边找比 key 大的,右边找比 key 小的while (L < R) { // 这里不要填等于,否则出不来了,死循环while (L < R && a[R] >= a[key_i]) R--;while (L < R && a[L] <= a[key_i]) L++;Swap(&a[L], &a[R]);}Swap(&a[R], &a[key_i]);key_i = R; QuickSort(a, begin, key_i - 1); // 左区间:[begin, key_i - 1]QuickSort(a, key_i +1, end); // 右区间:[key_i + 1, end]// 整个区间:[begin, key_i - 1], key_i, [key_i + 1, end]return;
}
性能测试
下面是数组已经有序情况下,测试 千万数据量级,可以看到 快排 起码不会爆栈了
【上面用到的:随机数生成测试排序性能器的代码】
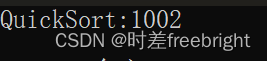
但是这个方法还有个缺点:虽然每次不会取到 最大或最小的,但是也是有不低的概率取到 次小 或 次大的,这个和最坏情况也差不多了,而且随机选数想选到中间数也是概率时间(选到中间的 就是最优情况),为了更加优化,就使用下面的第二个方法
🐻方法二:三数取中法
三数取中:指 left mid right 三个数中取大小在中间的(注意:不是位置排队在中间的,是大小)
有两种情况
1.若数据本来就是随机的,三数取中,取到的一定不是最大或最小值,则不会出现最坏情况
2.若数据是有序的,则 三数取中,取到的 一定是中位数,即出现最优情况 O ( n l o g n ) O(nlogn) O(nlogn)
代码思路:由左右下标,取中间数,比较三个数中大小中间值的
代码看起来长,但是逻辑较为简单
// 找出中间值
int GetMid(int* a, int left, int right) {int mid = (left + right) / 2;if (a[left] < a[mid]) {if (a[mid] < a[right]) return mid;else if (a[left] > a[right]) return left;else return right;}else {if (a[mid] > a[right]) return mid;else if (a[left] < a[right]) return left;else return right;}
}
主体代码修改
// 三数取中:思路一样 找出来时候还是和 左端换
int mid_i = GetMid(a, L, R);
Swap(&a[L], &a[mid_i]);
总代码
// 递归分治法
void QuickSort(int* a, int L, int R) {if (L >= R) return; int begin = L, end = R;///// 三数取中:思路一样 找出来时候还是和 左端换int mid_i = GetMid(a, L, R);Swap(&a[L], &a[mid_i]);///int key_i = L;// 左边找比 key 大的,右边找比 key 小的while (L < R) { // 这里不要填等于,否则出不来了,死循环while (L < R && a[R] >= a[key_i]) R--;while (L < R && a[L] <= a[key_i]) L++;Swap(&a[L], &a[R]);}Swap(&a[R], &a[key_i]);key_i = R; QuickSort(a, begin, key_i - 1); // 左区间:[begin, key_i - 1]QuickSort(a, key_i +1, end); // 右区间:[key_i + 1, end]// 整个区间:[begin, key_i - 1], key_i, [key_i + 1, end]return;
}
性能测试
这里还是随机生成一千万数据量,可以发现,对比上一种方法,快排性能强了一些
【上面用到的:随机数生成测试排序性能器的代码】
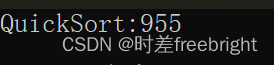
🐻方法三:小区间优化法
声明:下面测试性能数据都是随机值,数据量为 一千万,代码是release版本的,除了加入插排优化,其他代码一样
【上面用到的:随机数生成测试排序性能器的代码】
这个优化思路的使用原因:
快排是不断让序列趋向有序的,当区间数据剩下 10 个时,可以借助 插入排序优化,
由于快排递归分治法的递归展开结构类似 二叉树图,在递归展开图中,越向深处递归,递归节点越多,相应开辟函数栈帧的次数也快速增多,造成了不小的时间消耗,在之前 讲解过的 二叉树章节中提及,一棵满二叉树的最后一层的节点个数占总节点数的一半,则例如后面三层总共占了总节点数的 87%左右,我们可以思考如何优化这个过程:不进行后面这几层的递归,也能直接完成排序呢?
方案:我们就可以使用 插入排序,直接排序后面的小区间,就不用继续向下递归,减少一些因为递归过深,导致开辟的函数栈帧数量过多,产生的一些时间消耗
通常使用 插入排序,排序数据 < 10 的量
插入排序优化前:
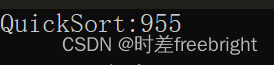
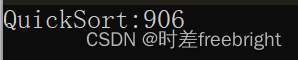
插入排序优化后:
但是注意:上面场景都是 处于release版本下的
release版本 会对一些代码运行过程中产生的,因开辟函数栈帧所产生的消耗,进行较大程度的优化,因此,我们使用 插入排序 优化掉的该部分的时间损耗,与 release版本的自动优化,效果是差不多的,因此,上面两张图片中的差别不大
该优化优点:可以减少掉 80~90%左右的递归次数
总结:可以发现,这种优化并不明显,则这个优化可加可不加,明白这个用法和思想就好
⭐二、挖坑法快排
挖坑法:选学即可,懂了上面的 Hoare法就好
该方法的本质还是 Hoare 霍尔的快排,优化在于:不用考虑左边先走,还是右边先走
优化了教学理解
动图演示:

⭐三、前后指针法快排
这个是重点
动图演示:

思路:
三个主要步骤
- cur < key:pre++,swap(cur, pre),cur++
- cur >= key :cur++
- cur 越界后,pre 和 key 交换
这种的写法优势:写法和思路较为简单,需要考虑的细节点没这么多(不像 Hoare法:还要考虑从 左端or右端开始等一系列细节点)
代码实现:
🐻先单趟
int key = L;
int pre = L;
int cur = L + 1; while (cur <= R) {if (a[cur] < a[key]) {pre++;Swap(&a[cur], &a[pre]);cur++;}else if (a[cur] >= a[key]) {cur++;}
}
Swap(&a[pre], &a[key]);
🐻后整体:
这个整体的递归写法,和章节前面讲解的一样,这里不赘诉
void QuickSort2(int* a, int L, int R) {if (L >= R) return; // L==R 说明只有一个int key = L;int pre = L;int cur = L + 1; while (cur <= R) {if (a[cur] < a[key]) {pre++;Swap(&a[cur], &a[pre]);cur++;}else if (a[cur] >= a[key]) {cur++;}}Swap(&a[pre], &a[key]);key = pre; // 这句话是为了代码好理解:不写也行,下面就用 pre代替现在的 key// 有时为了代码的可读性,没必要省几行代码QuickSort2(a, L, key - 1);QuickSort2(a, key + 1, R);// 区间:[L, key-1] key [key+1, R]
}
🐻简化写法:
观察代码,while循环核心代码处可以简化
// 简化版本:几行搞定
while (cur <= R) {if (a[cur] < a[key] && ++pre != cur)Swap(&a[cur], &a[pre]);cur++;
}
注意:
- pre处 必须先 ++
- ++pre != cur :意思是当 pre 和 cur 两指针相等时,指向同一个数,没必要进行循环中的交换步骤
🐻性能对比
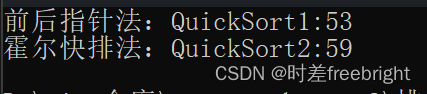
声明:下面测试性能数据都是随机值,数据量为 一百万,代码是release版本的
【上面用到的:随机数生成测试排序性能器的代码】
霍尔快排法 和 前后指针法 的性能是差不多的
学了递归法,还需学习非递归法,因为递归是有缺陷的,当递归过深,可能会爆栈,递归直接挂掉
⭐四、面试官爱考点(4):非递归写法
思路:将需要需要快排的“区间”入栈,每轮从栈顶取出一个区间,执行单趟的快排,再将该段区间分成左右区间,左右区间分别入栈,然后 while 循环进行此过程即可
仔细思考:可以发现,和上面文章讲解的 递归分治法的快排过程非常像,若能理解递归法,则 非递归法也是小问题
非递归法有两种写法:理解任意一种即可
🐻写法一:
栈的元素为 int 类型,存储 L 或 R,每次入栈都是 入栈两次(左右边界 L 和 R 入栈),每次出栈就 出栈两次(左右边界 L 和 R 出栈)
void QuickSort3(int* a, int L, int R) {Stack st;Init(&st);// 先将右边界 R 入栈,再将左边界L 入栈:先后不限,自定Push(&st, R);Push(&st, L);while (!Empty(&st)){// 将区间左右边界 L 和 R 取出来int L = Top(&st); Pop(&st);int R = Top(&st); Pop(&st);int key = L;int pre = L;int cur = L + 1; // 合法原因:这里一定保证程序有两个及以上个元素:只有一个元素的在前面已经 returnwhile (cur <= R) {if (a[cur] < a[key] && ++pre != cur) Swap(&a[cur], &a[pre]);cur++;}Swap(&a[pre], &a[key]);key = pre; // 区间:[L, key-1] key [key+1, R]// 若区间合法,就将区间入栈if (L < key - 1) {Push(&st, key - 1);Push(&st, L);}if (key + 1 < R) {Push(&st, R);Push(&st, key + 1);}}Destory(&st);
}
🐻写法二:
栈的元素为 【定义为”区间“的结构体】 类型,结构体中存储 L 或 R,每次入栈都是 入栈一次(一个区间结构体直接入栈),每次出栈就 出栈一次(一个区间结构体直接出栈)
下面展示结构体的定义与Stack栈的结构体的稍微修改,其他如Push 函数也有小修改,这里就不展示了,主要体现思路
// 定义为”区间“的结构体
typedef struct P{int L, R;
}Pair;typedef Pair STDataType; // 以 结构体Pair 为 数组元素类型
typedef struct {STDataType* a; // 以 结构体Pair 为 数组元素类型int top;int capacity;
}Stack;void QuickSort3(int* a, int L, int R) {Stack st;Init(&st);Push(&st, L, R); // 直接存入 区间:[L, R]while (!Empty(&st)){Pair t = Top(&st); // 取出栈顶的区间赋值给 结构体变量 tPop(&st);// 下面的代码就是方法一中代码的稍微改变以下,了解过结构体用法,就没问题int key = t.L;int pre = t.L;int cur = t.L + 1; // 合法原因:这里一定保证程序有两个及以上个元素:只有一个元素的在前面已经 returnwhile (cur <= R) {if (a[cur] < a[key] && ++pre != cur) Swap(&a[cur], &a[pre]);cur++;}Swap(&a[pre], &a[key]);key = pre; // 区间:[L, key-1] key [key+1, R]// 若区间合法,就将区间入栈if(t.L < key - 1) Push(&st, t.L, key - 1);if (key + 1 < t.R)Push(&st, key + 1, t.R);}Destory(&st);
}
🐻性能对比
声明:下面测试性能数据都是随机值,数据量为 一百万,代码是release版本的
【上面用到的:随机数生成测试排序性能器的代码】
非递归法 和 递归法 的性能是差不多的:就是换了种写法罢了

总结:根据这个非递归法,可以得到启发:递归法改成非递归法,可以考虑借助 栈结构,便于模拟递归返回上一层的情况
该方法常用于规避一些 有爆栈风险的递归代码优化
⭐五、快排和其他几种排序性能对比
这里快排使用 Hoare法+三数取中 的方法,和 希尔排序 、堆排序比较
下面我用代码随机生成 10000000 个数据,执行几个算法>排序算法,显示的数据为 时间,以 ms 为单位
【上面用到的:随机数生成测试排序性能器的代码】
一千万数据量:

快排还是非常猛的😎
🫡至此,第三章完结!
【若文章有什么错误或则可以改进的地方,非常欢迎评论区讨论或私信指出】