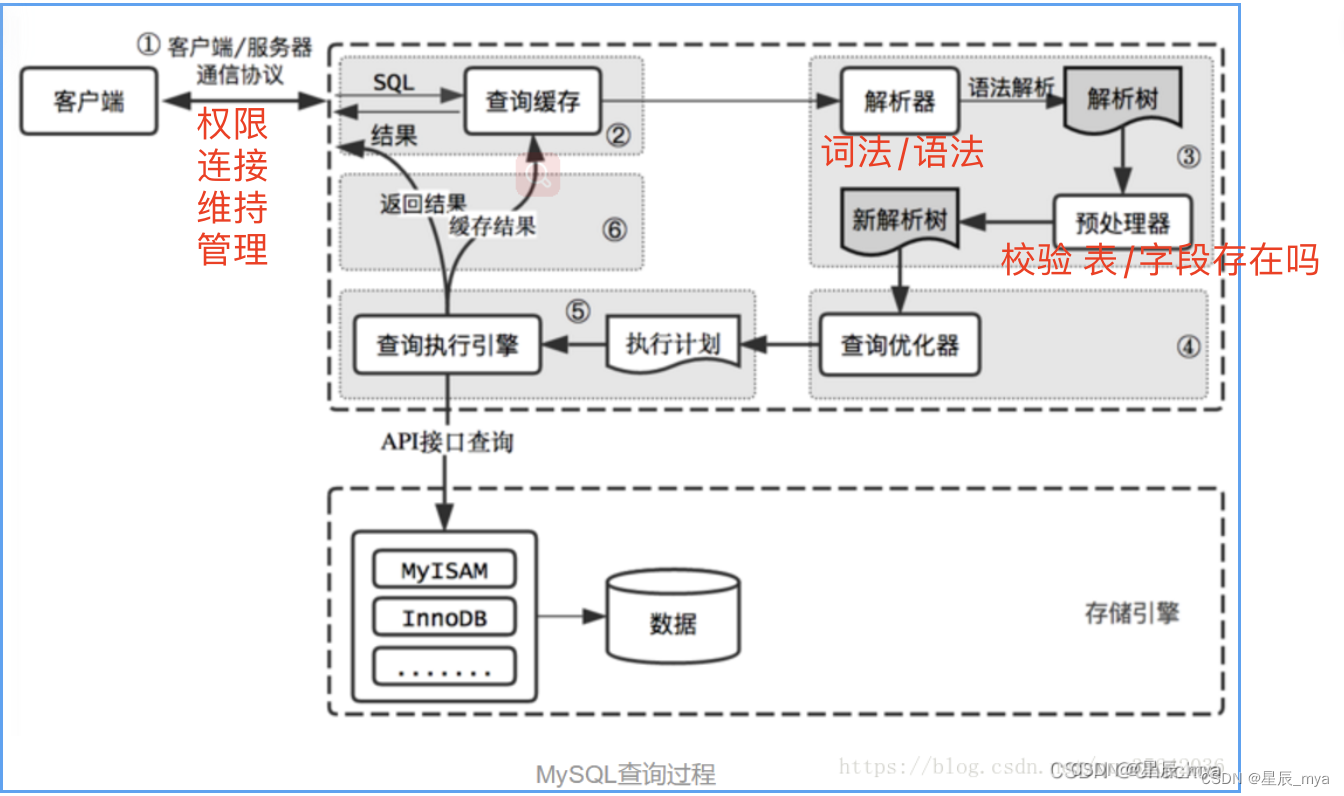
explain
id:序列号,越大优先级越高,相同从上往下执行 null最后执行
select_type简单simple 复杂的查询:primary subquery derived union
table:表
type:null > system > const > eq_ref > ref > range > index > all
- null 优化阶段分解查询语句,执行阶段不需再访问表/索引
- const/system 优化转常量
- eq_ref:primary key/ unique key部分数据被连接使用,最多返回一条符合条件的记录
- ref: 普通索引/唯一索引前缀
- range范围扫描in / between / > / < / >=
- all全表扫描,从头到尾查找需要的行
possible_keys:可能使用哪些索引
key实际使用的索引,无null 强制使用/忽略possiblekey,force index ignor index
key_len在索引使用的字节数,具体使用了哪些列
ref:关联的字段,const 字段名
rows:估计要读取 检索的行数
extra:
- using index覆盖索引
- using index condition 索引下推,索引过滤 where再过滤
- usnig where使用where处理结果 查询的列未被索引覆盖 全表扫描
- using temporary临时表,建索引
- using filesort外部排序,磁盘完成
- select tables optimized away聚合函数max min访问索引某个字段
char(n)n个字节 / varchar(n) 2n,utf-8 3n+2 / tinyint 1 / smallint 2 / int 4 / bigint 8
date 3 / timestamp 4字节 / datetime8字节 / 字段容许null 1字节记录是否为null
索引最大长度768字节,过长 截取提取字符
mysql缓冲鸡肋:语句本身稍有不同则清空;数据变化清空
优化:
避免子查询:小表 嵌 大表,可用join优化
in替换or:in中的常量存储在排好序的数组中(不宜大),连续值用between
in先执行子查询,外表大内表小
exists:外表先被访问,外表小 内表大
union all:明确没有重复数据,union结果集进行唯一性过滤(排序 cpu消耗延迟)
order by:无排序要求禁止排序order by null,排序字段无索引/分组统计 🈲️
group by: 无排序 order by null
explain无using temporary 适当调大tmp_table_size,实在太大SQL_BIG_RESULT
避免用having(检出all记录后过滤结果 需要排序分组) where提前过滤
尽量使用数字型字段:字符串需逐个对比 数字对比一次
join:
- t1 join t2,t1无索引2有 index nexted-loop join NLJ,explain什么都没写用的是NLJ
t1读取数据R 关联字段到t2查找 ,满足条件行 R组成一行 结果集
- t2无索引block nested-loop join BLJ,先读取到join_buffer内存中,t1放buffer,t2依次比较
- simple nested-loop joinSLJ,顺序去t1数据去t2全表匹配,成功作为结果集返回
被驱动表t2的join字段建索引,不能 则足够的join_buffer_size
减少left join(默认大表驱动小表 t1过滤变小t2加索引)
inner join自动的选择小表驱动大表,推荐的
临时表
排序:
待排序字段 放到sort buffer,排完返回
- 全字段排序,查询返回的字段 放入sortbuffer,排完返回
- rowid排序,需要排序的字段 放入sortbuffer 回表 返回
- max_length_for_sort_data控制哪一种
having
对返回的结构集操作
先执行where —— groupby分组 —— 聚集函数 —— having 子句
索引优化
索引列不做操作:计算 函数(5.8增加函数索引 函数计算后到值建立索引)
字符串带‘’,字符串与数字比较 字符串转为数字 进行比较
select * from user where id = CAST(“1” AS signed int) 函数作用在值可走索引
尽量使用覆盖索引
负向查询 != / <> / not in / not exists / not like 无法使用索引
is null / is not null 无法使用索引,高版本可以
少用or,where子句 or前后都是索引列 才能用索引(分别使用然合并)
mycat没有自己的数据库引擎
server.xml 、schema.xml、 rule.xml 、log4j2.xml
《深入理解mysql》
《mysql必知必会》
实践中如何优化MySQL(精)_mysql优化-CSDN博客
看一遍就理解:数据库group by详解_数据库_程序员小灰-GitCode 开源社区
explain详解和索引最佳实践-CSDN博客