G1收集器
属性
G1(Garbage-First Garbage Collector)在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为了默认的垃圾收集器。G1 有五个属性:分代、增量、并行、标记整理、STW。
分代
G1收集器 将内部分为多个大小相等的区域,另外每个区域都可以是新生区,老年区,幸存者区。如图:
我们也可以设置大小,可以通过 -XX:G1HeapRegionSize=n 来设置 Region 的大小,可以设定为 1M、2M、4M、8M、16M、32M(不能超过)。
在G1中,有专门分配大对象的区域,叫做大对象区,当对象的大小超过设定大小的百分之五十时,这个时候,就可以将对象放入大对象区域。而且一个大对象如果太大,可能会横跨多个 Region 来存放。
增量
G1收集器不必一次性将所有区域的垃圾都进行一次回收,只需要以增量的方式,循序渐进即可。这样做可以有效地控制停顿时间,尤其是处理大对象区的时候。
并行
G1收集器可以让多个CPU执行垃圾收集的过程。可以使垃圾收集的时间变短,这一特性在年轻代的垃圾回收中更加明显,因为年轻代多数都是朝生夕死的,所以需要更高的回收效率。
标记整理
G1收集器在进行老年代垃圾回收的时候是基于 标记整理算法的。它可以将内存碎片进行整理,来提高内存利用率。
但是要注意年轻代使用的是 标记复制算法,因为年轻代大部分都是朝生夕死,没有几个能存活下来,所以用标记复制算法效率更高。
STW
在上篇文章,就进行了对STW的解释,具体可以看上篇文章。
G1收集器在垃圾回收的时候仍然需要STW,因为Young GC、Mixed GC 都是基于标记复制,标记复制算法有个转移的过程,这个过程是需要STW,而Full GC基于标记整理,标记整理的过程也需要STW。不过,G1 在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
垃圾回收模式
G1有三种清理模式 : Young GC、Mixed GC 和 Full GC。
Eden 区的内存空间无法支持新对象的内存分配时,G1 会触发 Young GC。
当分配对象到大对象区或者堆中的占比超过参数-XX:G1HeapWastePercent 所设置的值InitiatingHeapOccupancyPercent 时,会触发一次concurrent Marking。作用是计算老年代中有多少对象需要回收。当占比超过-XX:G1HeapWastePercent 所设置的老年代中的G1HeapWastePercent 比例时,会触发一次Mixed GC.
Mixed GC 是指回收年轻代的 Region 以及一部分老年代中的 Region。Mixed GC 和 Young GC 一样,采用的也是复制算法。
此外,我们可以借助 -XX:MaxGCPauseMillis 来设置期望的停顿时间(默认 200ms),G1 会根据这个值来计算出一个合理的 Young GC 的回收时间,然后根据这个时间来制定 Young GC 的回收计划。
G1收集器到底是怎么控制停顿时间的?
我们在增量中写到,G1收集器不必一次性回收整个堆区或者整个新生代等,他的回收是基于所分配的最小region区域,使回收的部分每次都是region的整数倍,这样可以更好控制停顿时间。
可能大家又问,为什么控制垃圾回收区域是region整数倍就能指定停顿时间?
具体来讲,在G1收集器内部,会设置个优先级队列。他会跟踪各个region里面垃圾堆积的价值,价值也就是回收所获得的空间大小以及回收所需要的时间,然后根据这个价值,在优先级队列之中排好序。这样就可以每次根据用户指定的停顿时间,来控制垃圾回收,到底回收多少,并且回收的是价值最高的垃圾,这也就是为什么叫做Garbage first 收集器。
G1收集器如何运作
G1收集器和CMS收集器过程是类似的,分为四个步骤
初始标记:仅仅只是标记一下与GCRoot直接关联的对象,并且修改TAMS指针的值。( 并发分配的新对象的指针值在TAMS上),这个过程需要短暂的暂停用户线程。
并发标记:从GCRoot 开始对所有对象进行可达性分析,找出要回收的对象,这个过程耗时长,但是可以与用户进程并发进行。
最终标记:对用户做一个短暂暂停,用于处理并发结束后仍遗留的少量的STAB记录,STAB是快照。
筛选回收:更新Region数据,并进行垃圾回收,进行对象移动,对各个Region的区域进行价值排序。因为要进行对象移动,所以暂停用户进程。
ZGC收集器
ZGC(The Z Garbage Collector)是 JDK11 推出的一款低延迟垃圾收集器,适用于大内存低延迟服务的内存管理和回收,SPEC jbb 2015 基准测试,在 128G 的大堆下,最大停顿时间才 1.68 ms,停顿时间远胜于 G1 和 CMS。
ZGC收集器和CMS的Young GC、Mixed GC类似,基于标记复制算法。但是为什么ZGC停顿时间更短?
ZGC 在标记、转移和重定位阶段几乎都是并发的,这是 ZGC 实现停顿时间小于 10ms 的关键所在。
那ZGC 怎么做到的?
它基于两个特性:
- 指针染色(Colored Pointer):一种用于标记对象状态的技术。
- 读屏障(Load Barrier):一种在程序运行时插入到对象访问操作中的特殊检查,用于确保对象访问的正确性
指针染色
指针上面不只有对象的地址,还有对象的状态(是否存活),是否被移动了(在转移的过程中,别的线程又调用对象),还有对象是否有某种特殊状态或者是否被锁定.
通过在指针中嵌入这些信息,ZGC 在标记和转移阶段会更快,因为通过指针上的颜色就能区分出对象状态,不用额外做内存访问。因为如果没有指针颜色的话,需要根据地址访问内存,才能查看状态。
读屏障
当程序尝试读取一个对象时,读屏障会触发以下操作:
- 检查指针染色:读屏障首先检查指向对象的指针的颜色信息。
- 处理移动的对象:如果指针表示对象已经被移动(例如,在垃圾回收过程中),读屏障将确保返回对象的新位置。
- 确保一致性:通过这种方式,ZGC 能够在并发移动对象时保持内存访问的一致性,从而减少对应用程序停顿的需要。
ZGC 的工作过程
ZGC 周期由三个 STW 暂停和四个并发阶段组成:标记/重新映射( M/R )、并发引用处理( RP )、并发转移准备( EC ) 和并发转移( RE )。
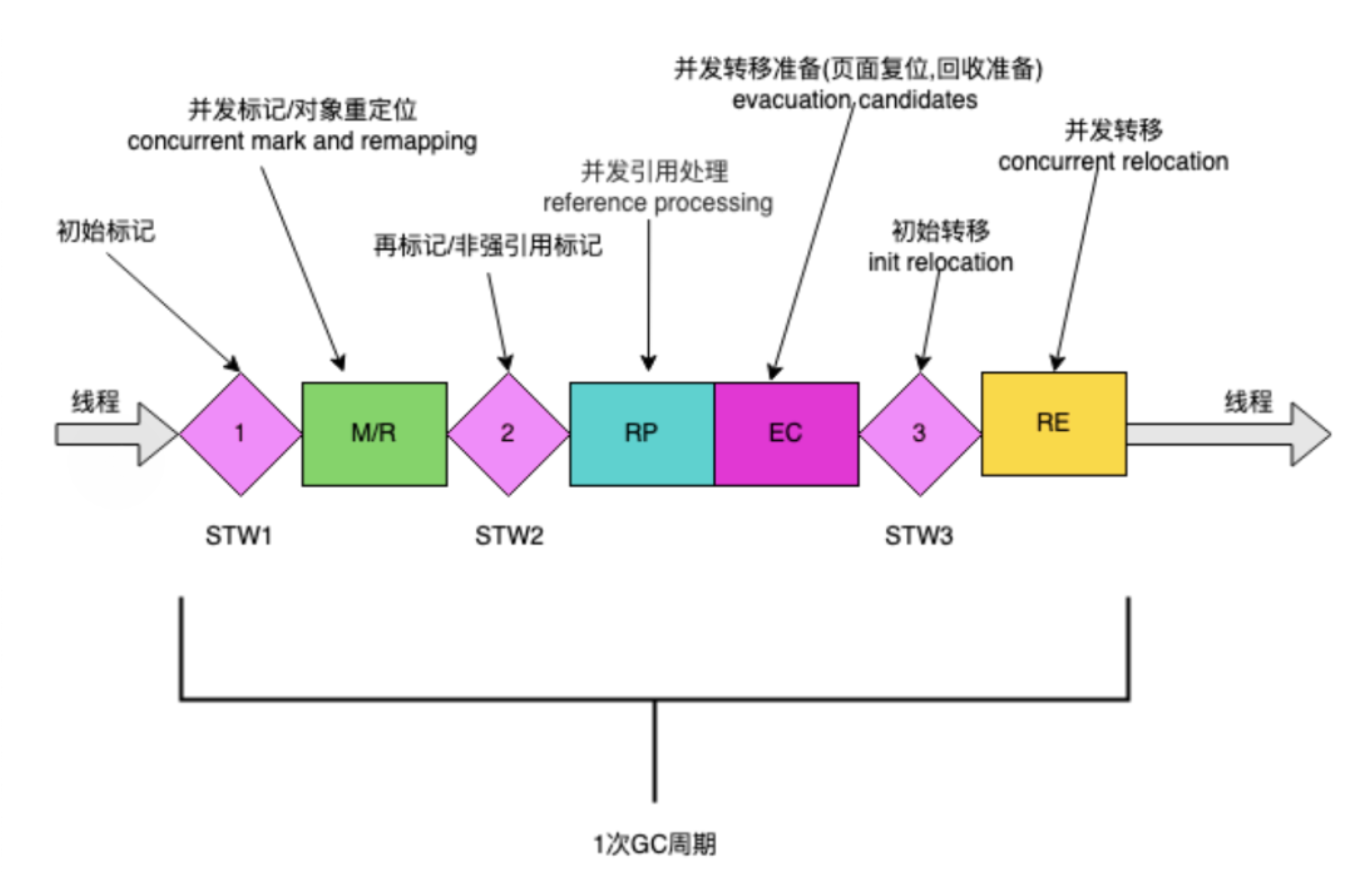
Stop-The-World 暂停阶段
-
标记开始(Mark Start)STW 暂停:这是 ZGC 的开始,进行 GC Roots 的初始标记。在这个短暂的停顿期间,ZGC 标记所有从 GC Root 直接可达的对象。
-
重新映射开始(Relocation Start)STW 暂停:在并发阶段之后,这个 STW 暂停是为了准备对象的重定位。在这个阶段,ZGC 选择将要清理的内存区域,并建立必要的数据结构以进行对象移动。
-
暂停结束(Pause End)STW 暂停:ZGC 结束。在这个短暂的停顿中,完成所有与该 GC 周期相关的最终清理工作。
并发阶段
-
并发标记/重新映射 (M/R) :这个阶段包括并发标记和并发重新映射。在并发标记中,ZGC 遍历对象图,标记所有可达的对象。然后,在并发重新映射中,ZGC 更新指向移动对象的所有引用。
-
并发引用处理 (RP) :在这个阶段,ZGC 处理各种引用类型(如软引用、弱引用、虚引用和幽灵引用)。这些引用的处理通常需要特殊的考虑,因为它们与对象的可达性和生命周期密切相关。
-
并发转移准备 (EC) :这是为对象转移做准备的阶段。ZGC 确定哪些内存区域将被清理,并准备相关的数据结构。
-
并发转移 (RE) :在这个阶段,ZGC 将存活的对象从旧位置移动到新位置。由于这一过程是并发执行的,因此应用程序可以在大多数垃圾回收工作进行时继续运行。
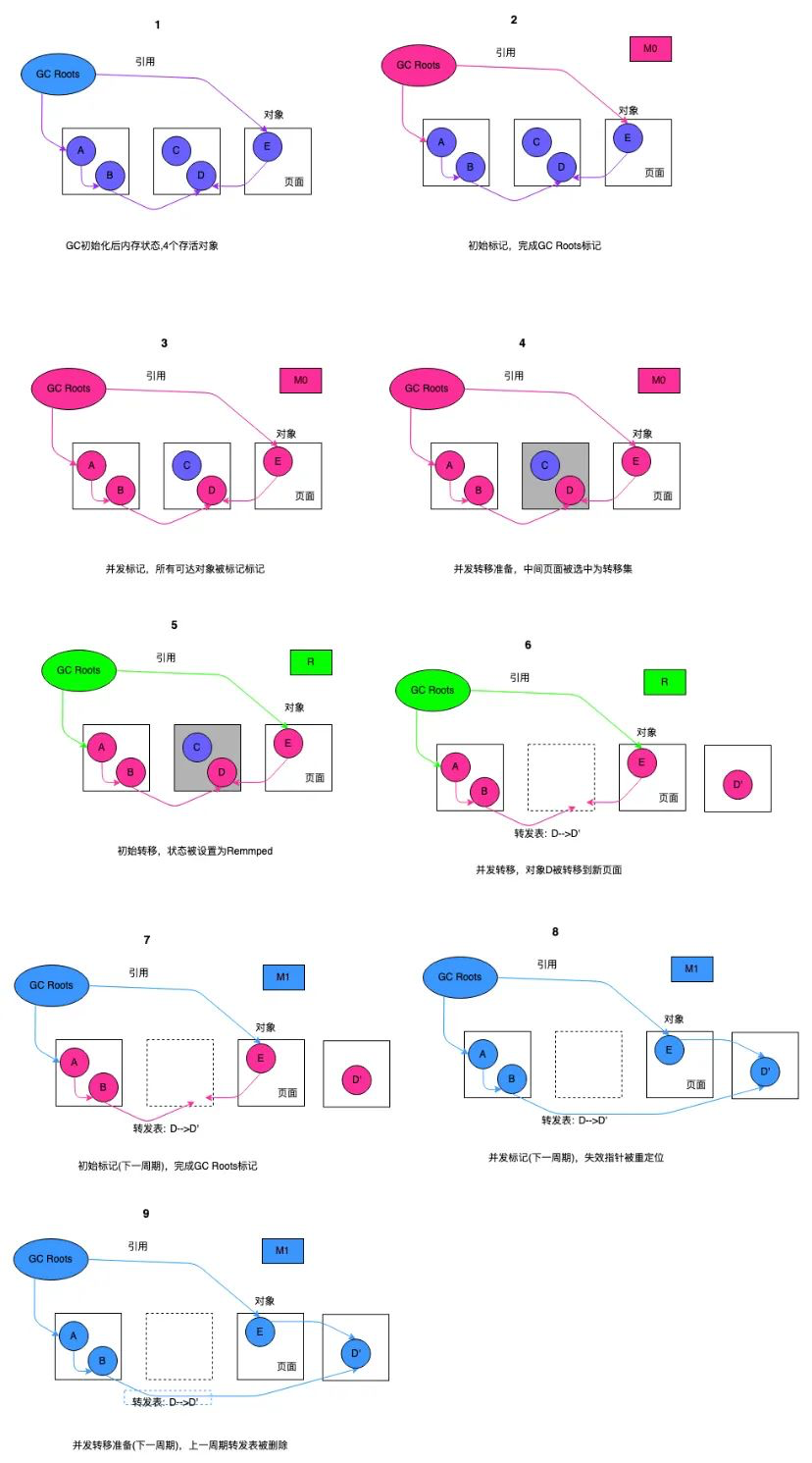
ZGC 的两个关键技术:指针染色和读屏障,不仅应用在并发转移阶段,还应用在并发标记阶段:将对象设置为已标记,传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;而在ZGC中,只需要设置指针地址的第42-45位即可,并且因为是寄存器访问,所以速度比访问内存更快。
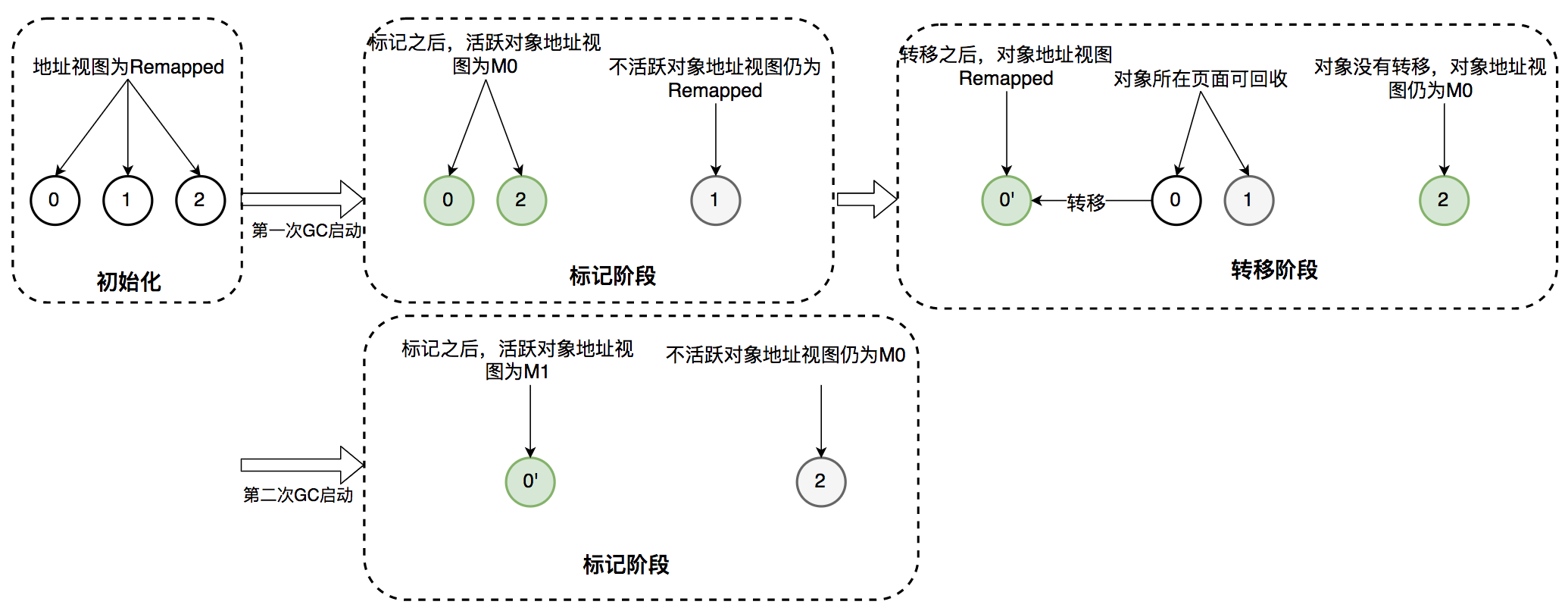
注:ZGC工作流程部分内容来自 javabetter.cn



