文章目录
- 一、什么是MongoDB
- 二、MongoDB 与关系型数据库对比
- 三、数据类型
- 四、部署MongoDB
- 1、下载二进制包
- 2、下载安装包并解压
- 3、创建用于存放数据和日志的目录,并修改权限
- 4、启动MongoDB
- 4.1前台启动
- 4.2后台启动
- 4.3、配置文件启动服务
- 4.4、配置systemd服务
- 4.5、systemctl启动MongoDB
- 5、客户端配置
- 6、关闭MongoDB
- 6.1、前台启动
- 6.2、后台启动
- 6.3、kill命令关闭
- 6.4、MongoDB函数关闭
- 五、MongoDB基本操作及增删改查
- 1、基本操作
- 1.1、登录数据库
- 1.2、查看数据库
- 1.3、查看当前正在使用的数据库
- 1.4、选择/创建数据库
- 1.5、查看集合
- 1.6、创建集合
- 1.7、删除集合
- 1.8、删除数据库
- 2、增删改查
- 2.1、插入文档
- 2.1.1、一次性插入多条数据
- 2.2、查询文档
- 2.2.1、查询集合内所有的记录数
- 2.3、修改文档
- 2.4、删除文档
- 六、MongoDB支持存储的数据类型
- 1、数字
- 2、字符串
- 3、正则表达式
- 4、数组
- 5、日期
- 6、内嵌文档
- 七、MongoDB中的索引
- 1、查看索引
- 2、需要索引的查询场景
- 2.1、创建有10000个文档的集合
- 2.2、查询`age`为`200`的文档
- 2.3、添加`limit`查询文档
- 2.4、创建索引
- 2.5、自定义索引名字
- 3、查看索引的大小
- 4、删除索引
- 4.1、按名称删除索引
- 4.2、删除所有的索引
- 5、优缺点
- 5.1、优点:
- 5.2、缺点:
一、什么是MongoDB
MongoDB 是一个开源、高性能、无模式的、基于分布式文件存储的文档型数据库,当初的设计就是用于简化开发和方便扩展,是 NoSQL 数据库产品中的一种。是最像关系型数据库(MySQL)的非关系型数据库。
它支持的数据结构非常松散,是一种类似于JSON的格式叫BSON(Binary JSON),所以它既可以存储比较复杂的数据类型,又相当的灵活。
二、MongoDB 与关系型数据库对比

| SQL 术语/概念 | MongoDB 术语/概念 | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 不支持 | 表连接,MongoDB 不支持 |
| 不支持 | 嵌入文档 | MongoDB 通过嵌入式文档来替代多表连接 |
| primary key | primary key | 主键,MongoDB 自动将_id 字段设置为主键 |
三、数据类型
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | utf8字符串都可以表示为字符串类型的数据 | {“x”:“foobar”} |
| 对象id | 对象id是文档的12字节的唯一ID | {“X”:Objectid()} |
| 布尔值 | 真或者假:true或者false | {“x”:true} |
| 数组 | 值的集合或者列表都可以表示成数组 | {“x”:[“a”,“b”,“c”]} |
| 整数 | (Int32 Int64 , 一般我们用Int32) | {“age”:18} |
| null | 表示空值或者未定义的对象 | {“x”:null} |
| undefined | 文档中也可以使用未定义类型 | {“x”:undefined} |
四、部署MongoDB
1、下载二进制包
下载地址
2、下载安装包并解压
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.6.tgz
tar xzvf mongodb-linux-x86_64-rhel70-4.4.6.tgz -C /usr/local
cd /usr/local/
ln -s /usr/local/mongodb-linux-x86_64-rhel70-4.4.6 /usr/local/mongodb
3、创建用于存放数据和日志的目录,并修改权限
# 创建存放数据的目录
mkdir -p /usr/local/mongodb/data/db
# 创建存放日志的目录
mkdir -p /usr/local/mongodb/logs
# 创建日志记录文件
touch /usr/local/mongodb/logs/mongodb.log
4、启动MongoDB
4.1前台启动
MongoDB的默认启动方式为前台启动
cd /usr/local/mongodb/bin/mongod \
--dbpath /usr/local/mongodb/data/db/ \
--logpath /usr/local/mongodb/logs/mongodb.log \
--logappend \
--port 27017 \
--bind_ip 0.0.0.0
参数解释:
--dbpath:指定数据文件存放目录--logpath:指定日志文件,注意是指定文件不是目录--logappend:使用追加的方式记录日志--port:指定端口,默认为 27017--bind_ip:绑定服务 IP,若绑定 127.0.0.1,则只能本机访问,默认为本机地址
4.2后台启动
后台启动在命令中添加–fork即可
cd /usr/local/mongodb/bin/mongod \
--dbpath /usr/local/mongodb/data/db/ \
--logpath /usr/local/mongodb/logs/mongodb.log \
--logappend \
--port 27017 \
--bind_ip 0.0.0.0 \
--fork
4.3、配置文件启动服务
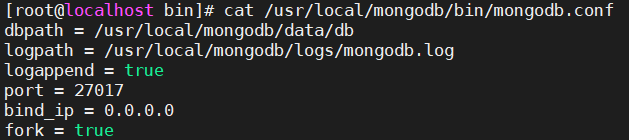
bin目录下增加一个mongodb.conf配置文件
vim /usr/local/mongodb/bin/mongodb.conf
# 数据文件存放目录
dbpath = /usr/local/mongodb/data/db
# 日志文件存放目录
logpath = /usr/local/mongodb/logs/mongodb.log
# 以追加的方式记录日志
logappend = true
# 端口默认为 27017
port = 27017
# 对访问 IP 地址不做限制,默认为本机地址
bind_ip = 0.0.0.0
# 以守护进程的方式启用,即在后台运行
fork = true
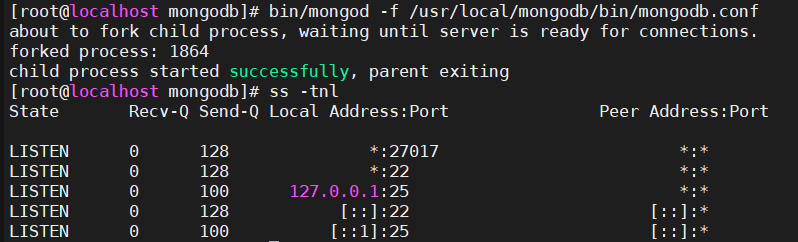
启动命令:
bin/mongod -f /usr/local/mongodb/bin/mongodb.conf
4.4、配置systemd服务
vim /usr/lib/systemd/system/mongodb.service[Unit]
Description=mongodb
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
ExecStart=/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/bin/mongodb.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/usr/local/mongodb/bin/mongod --shutdown --config /usr/local/mongodb/bin/mongodb.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.targetchmod 754 /usr/lib/systemd/system/mongodb.service
4.5、systemctl启动MongoDB
systemctl start mongodb
5、客户端配置
添加环境变量
echo "export PATH=/usr/local/mongodb/bin/:$PATH" >> /etc/profile
source /etc/profile
mongo
6、关闭MongoDB
6.1、前台启动
Ctrl + c
6.2、后台启动
# 命令启动方式的关闭
bin/mongod --dbpath /usr/local/mongodb/data/db/ --logpath /usr/local/mongodb/logs/mongodb.log --logappend --port 27017 --bind_ip 0.0.0.0 --fork --shutdown
# 配置文件启动方式的关闭
bin/mongod -f /usr/local/mongodb/bin/mongodb.conf --shutdown
6.3、kill命令关闭
不推荐使用
# 查看 mongodb 运行的进程信息
ps -ef | grep mongodb
# kill -9 强制关闭
kill -9 pid
6.4、MongoDB函数关闭
# 连接 mongodb
mongo
# 切换 admin 数据库
use admin
# 执行以下函数(2选1)即可关闭服务
db.shutdownServer()
db.runCommand("shutdown")
五、MongoDB基本操作及增删改查
1、基本操作
1.1、登录数据库
mongo
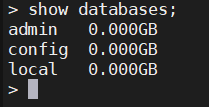
1.2、查看数据库
show databases
show dbs
1.3、查看当前正在使用的数据库
db
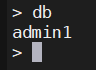
1.4、选择/创建数据库
use admin
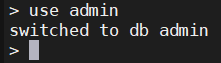
如果切换到一个没有的数据库,那么会隐式创建这个数据库。(后期当该数据库有数据时,系统自动创建)
use admin1
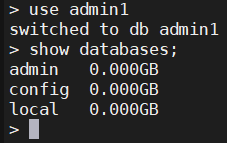
1.5、查看集合
show collections
1.6、创建集合
db.createCollection('集合名')
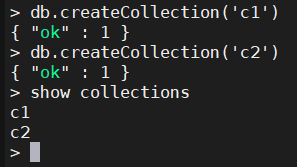
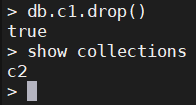
1.7、删除集合
db.集合名.drop()
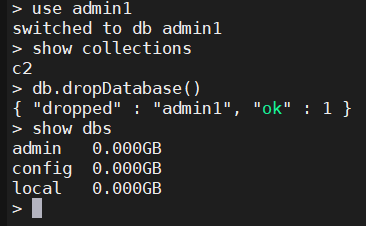
1.8、删除数据库
通过
use语法选择数据
通过db.dropDataBase()删除数据库
> use admin1
switched to db admin1
> show collections
c2
> db.dropDatabase()
{ "dropped" : "admin1", "ok" : 1 }
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
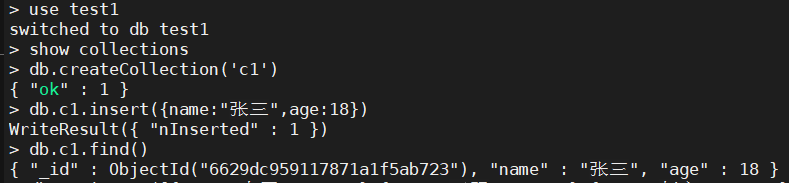
2、增删改查
2.1、插入文档
如果集合存在,那么直接插入数据。
如果集合不存在,那么会隐式创建。
db.集合名.insert(JSON数据)
- 在test1数据库的c1集合中插入文档,(姓名:张三,年龄:18)
> use test1
switched to db test1
> show collections
> db.createCollection('c1')
{ "ok" : 1 }
> db.c1.insert({name:"张三",age:18})
WriteResult({ "nInserted" : 1 })
> db.c1.find()
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
- 数据库和集合不存在都隐式创建
- 对象的键统一不加引号(方便看),但是查看集合数据时系统会自动加
mongodb会给每条数据增加一个全球唯一的_id键
2.1.1、一次性插入多条数据
- 数组中一个个写入
json数据
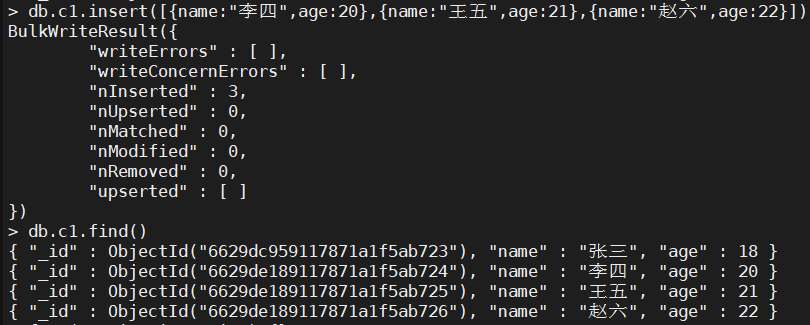
> db.c1.insert([{name:"李四",age:20},{name:"王五",age:21},{name:"赵六",age:22}])
BulkWriteResult({"writeErrors" : [ ],"writeConcernErrors" : [ ],"nInserted" : 3,"nUpserted" : 0,"nMatched" : 0,"nModified" : 0,"nRemoved" : 0,"upserted" : [ ]
})
> db.c1.find()
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四", "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五", "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六", "age" : 22 }
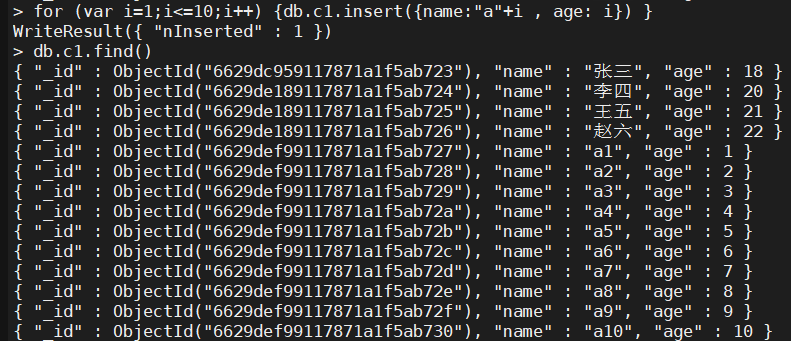
- 写for循环插入数据
> for (var i=1;i<=10;i++) {db.c1.insert({name:"a"+i , age: i}) }
WriteResult({ "nInserted" : 1 })
> db.c1.find()
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四", "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五", "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六", "age" : 22 }
{ "_id" : ObjectId("6629def99117871a1f5ab727"), "name" : "a1", "age" : 1 }
{ "_id" : ObjectId("6629def99117871a1f5ab728"), "name" : "a2", "age" : 2 }
{ "_id" : ObjectId("6629def99117871a1f5ab729"), "name" : "a3", "age" : 3 }
{ "_id" : ObjectId("6629def99117871a1f5ab72a"), "name" : "a4", "age" : 4 }
{ "_id" : ObjectId("6629def99117871a1f5ab72b"), "name" : "a5", "age" : 5 }
{ "_id" : ObjectId("6629def99117871a1f5ab72c"), "name" : "a6", "age" : 6 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7", "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "name" : "a8", "age" : 8 }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "name" : "a9", "age" : 9 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10", "age" : 10 }
2.2、查询文档
db.集合名.find(条件[,查询的列])
| 条件 | 写法 |
|---|---|
| 查询所有的数据 | {}或者不写 |
| 查询age=6的数据 | {age:6} |
| 既要age=6又要性别=男 | {age:6,sex:‘男’} |
| 查询的列(可选参数) | 写法 |
|---|---|
| 查询全部列(字段) | 不写 |
| 只显示age列(字段) | {age:1} |
| 除了age列(字段)都显示 | {age:0} |
其他语法
db.集合名.find({键:{运算符:值}})
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
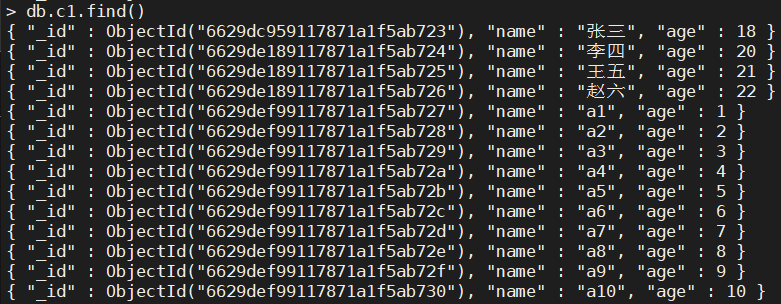
- 查看所有数据
> db.c1.find()
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四", "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五", "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六", "age" : 22 }
{ "_id" : ObjectId("6629def99117871a1f5ab727"), "name" : "a1", "age" : 1 }
{ "_id" : ObjectId("6629def99117871a1f5ab728"), "name" : "a2", "age" : 2 }
{ "_id" : ObjectId("6629def99117871a1f5ab729"), "name" : "a3", "age" : 3 }
{ "_id" : ObjectId("6629def99117871a1f5ab72a"), "name" : "a4", "age" : 4 }
{ "_id" : ObjectId("6629def99117871a1f5ab72b"), "name" : "a5", "age" : 5 }
{ "_id" : ObjectId("6629def99117871a1f5ab72c"), "name" : "a6", "age" : 6 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7", "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "name" : "a8", "age" : 8 }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "name" : "a9", "age" : 9 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10", "age" : 10 }
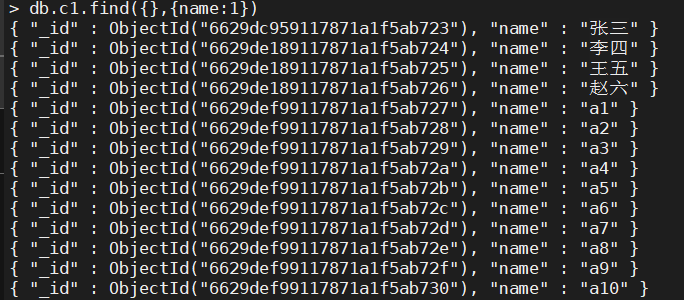
- 只看name列
> db.c1.find({},{name:1})
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三" }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四" }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五" }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六" }
{ "_id" : ObjectId("6629def99117871a1f5ab727"), "name" : "a1" }
{ "_id" : ObjectId("6629def99117871a1f5ab728"), "name" : "a2" }
{ "_id" : ObjectId("6629def99117871a1f5ab729"), "name" : "a3" }
{ "_id" : ObjectId("6629def99117871a1f5ab72a"), "name" : "a4" }
{ "_id" : ObjectId("6629def99117871a1f5ab72b"), "name" : "a5" }
{ "_id" : ObjectId("6629def99117871a1f5ab72c"), "name" : "a6" }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7" }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "name" : "a8" }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "name" : "a9" }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10" }
- 查看除了name列
> db.c1.find({},{name:0})
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "age" : 22 }
{ "_id" : ObjectId("6629def99117871a1f5ab727"), "age" : 1 }
{ "_id" : ObjectId("6629def99117871a1f5ab728"), "age" : 2 }
{ "_id" : ObjectId("6629def99117871a1f5ab729"), "age" : 3 }
{ "_id" : ObjectId("6629def99117871a1f5ab72a"), "age" : 4 }
{ "_id" : ObjectId("6629def99117871a1f5ab72b"), "age" : 5 }
{ "_id" : ObjectId("6629def99117871a1f5ab72c"), "age" : 6 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "age" : 8 }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "age" : 9 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "age" : 10 }
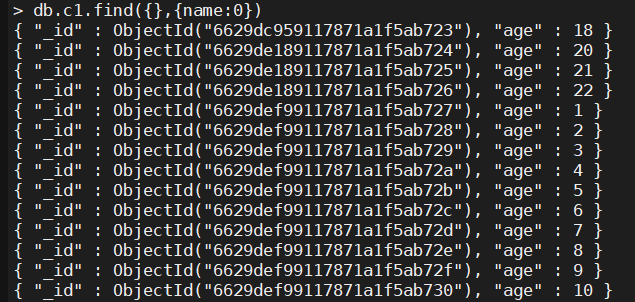
- 查询
age大于6的数据
> db.c1.find({age:{$gt:6}})
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四", "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五", "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六", "age" : 22 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7", "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "name" : "a8", "age" : 8 }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "name" : "a9", "age" : 9 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10", "age" : 10 }
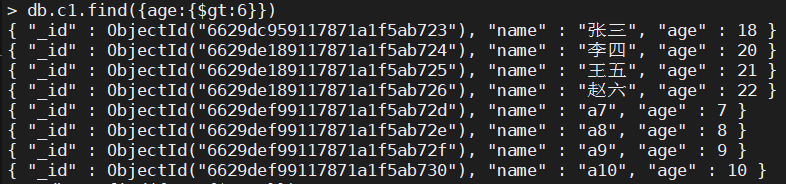
- 查询年龄为
7岁、10岁、18岁的数据
> db.c1.find({age:{$in:[7,10,18]}})
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "张三", "age" : 18 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7", "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10", "age" : 10 }

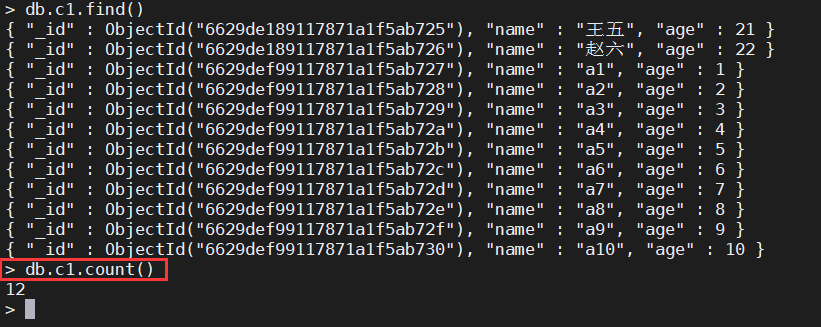
2.2.1、查询集合内所有的记录数
db.集合名.count()
2.3、修改文档
db.集合名.update(<filter>, // 查询条件(筛选待更新的文档)<update>, // 更新操作定义(如何修改文档){upsert: <boolean>, // 可选,如果无匹配文档则插入,默认为 falsemulti: <boolean>, // 可选,是否更新所有匹配的文档,默认为 false(仅更新第一条)collation: <object>, // 可选,指定比较选项(如大小写敏感等)arrayFilters: <array>, // 可选,用于处理嵌套数组中的条件匹配hint: <string|document>, // 可选,提供索引来指导查询writeConcern: <document>, // 可选,指定写关注级别let: <object> // 可选,用于与聚合管道更新相关的变量定义}
)
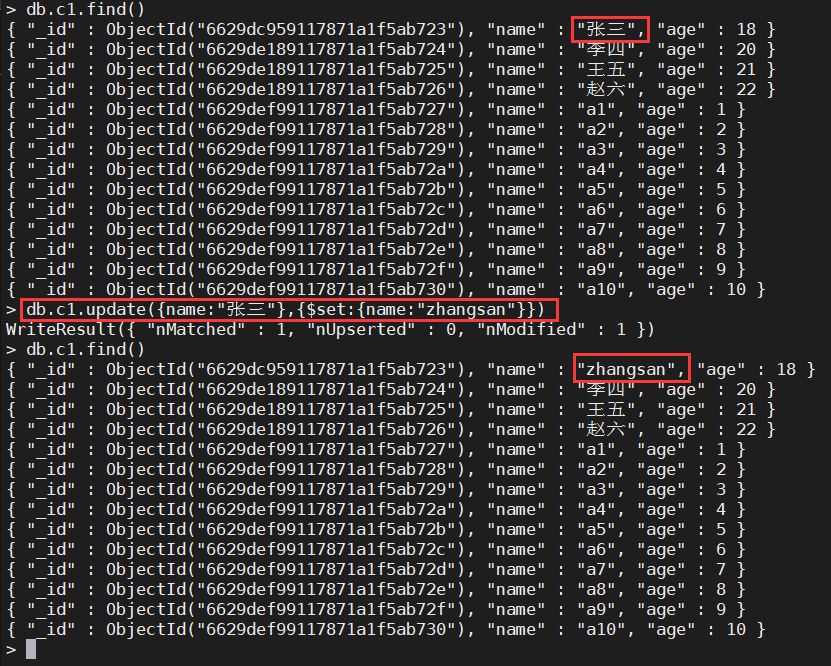
- 将
{name:"张三"}修改为{name:"zhangsan"}
> db.c1.update({name:"张三"},{$set:{name:"zhangsan"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.c1.find()
{ "_id" : ObjectId("6629dc959117871a1f5ab723"), "name" : "zhangsan", "age" : 18 }
{ "_id" : ObjectId("6629de189117871a1f5ab724"), "name" : "李四", "age" : 20 }
{ "_id" : ObjectId("6629de189117871a1f5ab725"), "name" : "王五", "age" : 21 }
{ "_id" : ObjectId("6629de189117871a1f5ab726"), "name" : "赵六", "age" : 22 }
{ "_id" : ObjectId("6629def99117871a1f5ab727"), "name" : "a1", "age" : 1 }
{ "_id" : ObjectId("6629def99117871a1f5ab728"), "name" : "a2", "age" : 2 }
{ "_id" : ObjectId("6629def99117871a1f5ab729"), "name" : "a3", "age" : 3 }
{ "_id" : ObjectId("6629def99117871a1f5ab72a"), "name" : "a4", "age" : 4 }
{ "_id" : ObjectId("6629def99117871a1f5ab72b"), "name" : "a5", "age" : 5 }
{ "_id" : ObjectId("6629def99117871a1f5ab72c"), "name" : "a6", "age" : 6 }
{ "_id" : ObjectId("6629def99117871a1f5ab72d"), "name" : "a7", "age" : 7 }
{ "_id" : ObjectId("6629def99117871a1f5ab72e"), "name" : "a8", "age" : 8 }
{ "_id" : ObjectId("6629def99117871a1f5ab72f"), "name" : "a9", "age" : 9 }
{ "_id" : ObjectId("6629def99117871a1f5ab730"), "name" : "a10", "age" : 10 }
- 将
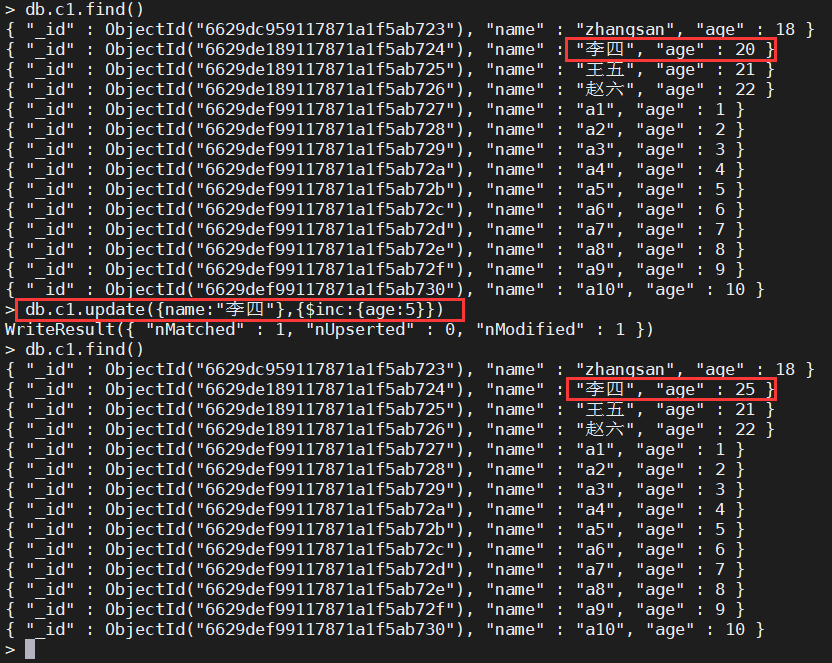
{name:"李四"}的年龄加/减5
年龄加5
db.c1.update({name:"李四"},{$inc:{age:5}})
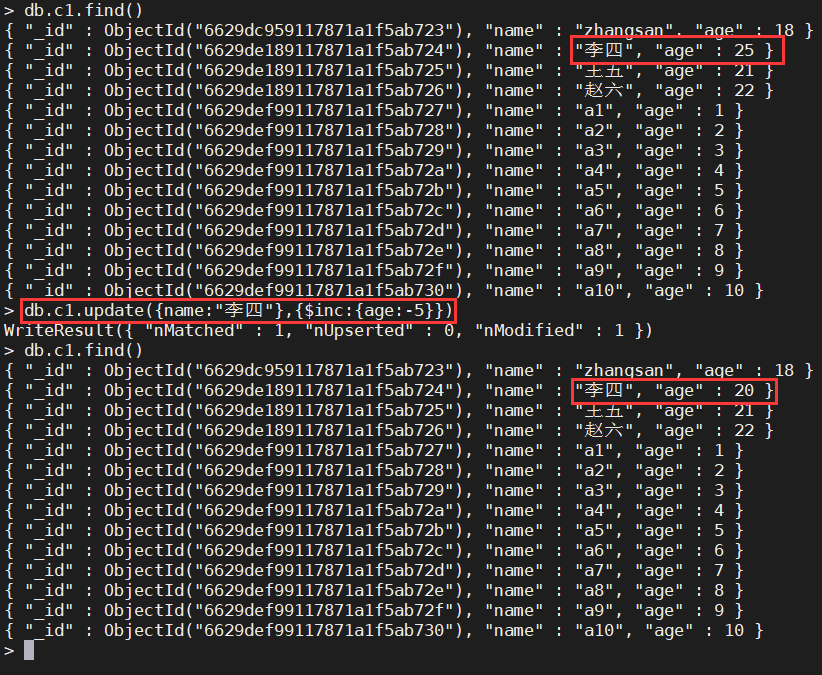
年龄减5
db.c1.update({name:"李四"},{$inc:{age:-5}})
2.4、删除文档
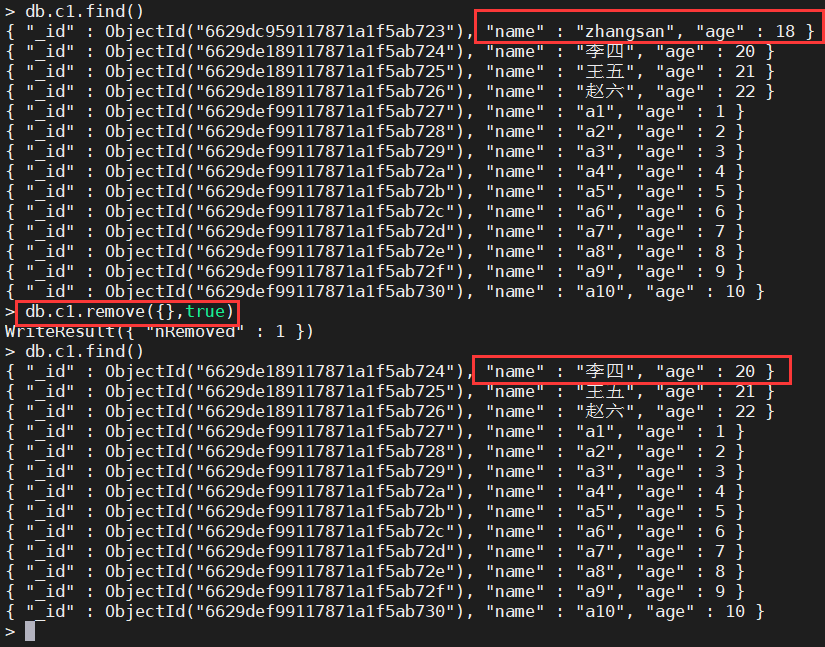
db.集合名.remove(条件[,是否删除一条])
-
删除一条数据
-
db.c1.remove({},true)默认删除的第一条数据
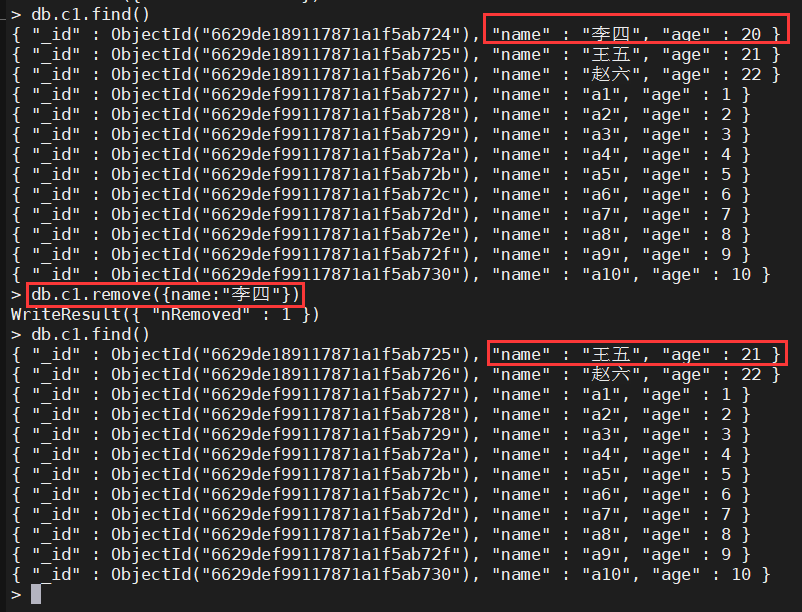
-
db.c1.remove({name:"李四"})删除指定数据
-
六、MongoDB支持存储的数据类型
1、数字
shell默认使用64位浮点型数值
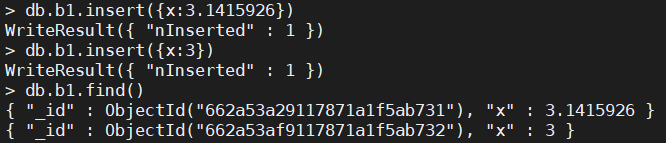
db.b1.insert({x:3.1415926})
db.b1.insert({x:3})
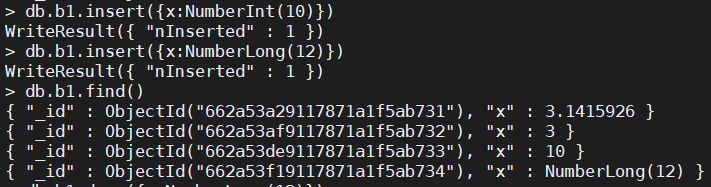
- 整型值,可以用
NumberInt或者NumberLong表示
db.b1.insert({x:NumberInt(10)})
db.b1.insert({x:NumberLong(12)})
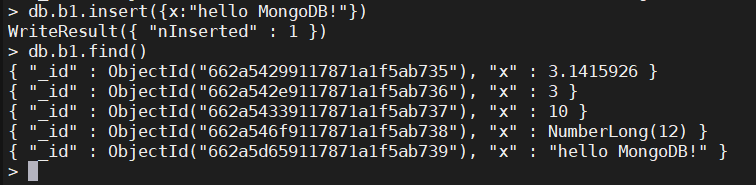
2、字符串
db.b1.insert({x:"hello MongoDB!"})
3、正则表达式
查询所有
key为x,value以hello开头的文档且不区分大小写
db.b1.find({x:/^(hello).(.[a-zA-Z0-9])+/i})

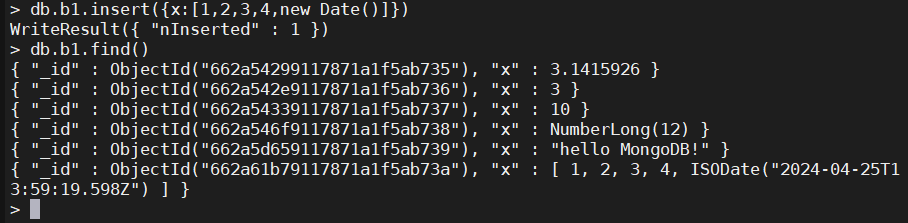
4、数组
数组中的数据类型可以是多种多样的
db.b1.insert({x:[1,2,3,4,new Date()]})
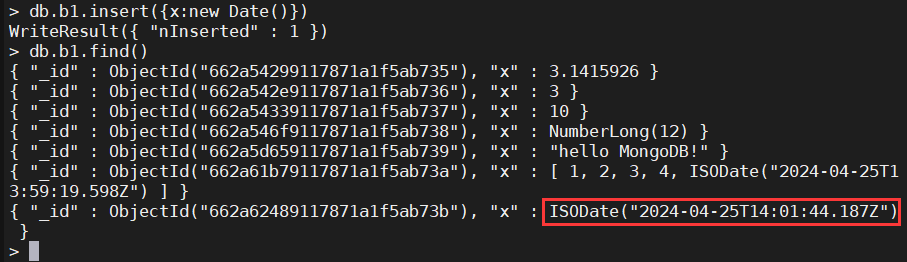
5、日期
db.b1.insert({x:new Date()})
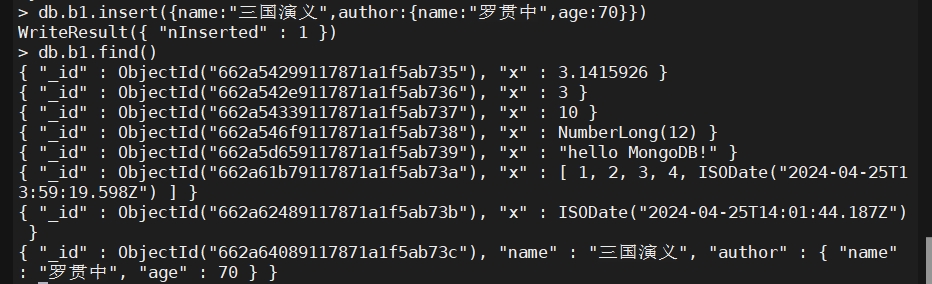
6、内嵌文档
一个文档也可以作为另一个文档的
value
db.b1.insert({name:"三国演义",author:{name:"罗贯中",age:70}})
七、MongoDB中的索引
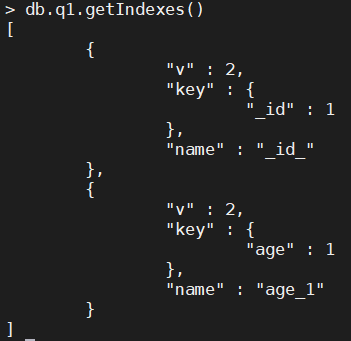
1、查看索引
默认情况下,集合中的
_id字段就是索引,我们可以通过getIndexes()方法来查看一个集合中的索引:
db.b1.getIndexes()

v: 表示索引版本。在这个例子中,值为2,表示这是一个版本 2 的索引。索引版本通常由 MongoDB 内部管理,用户通常不需要直接关心。key: 描述了索引的键(即排序依据)。键是一个对象,键名为字段名,键值为排序方向。在给出的例子中,{ "_id" : 1 }表示索引基于字段_id,且按升序(1)排序。在 MongoDB 中,每个集合都默认有一个名为_id的主键索引,它是唯一的,并且总是按升序排列。name: 指定索引的名称。这里为"name" : "_id_",表示这是一个针对_id字段的索引,其名称默认为_id_。在 MongoDB 中,主键索引的名称通常是固定的,即_id_。
2、需要索引的查询场景
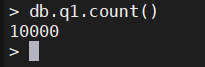
2.1、创建有10000个文档的集合
for (var i=1;i<=10000;i++) {db.q1.insert({name:"test"+i , age: i})}
db.q1.count()
2.2、查询age为200的文档
db.q1.find({age:200})

这种查询默认情况下会做全表扫描,可以用
explain()来查看一下查询计划
db.q1.find({age:200}).explain("executionStats")
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test3.q1","indexFilterSet" : false,"parsedQuery" : {"age" : {"$eq" : 200}},"winningPlan" : {"stage" : "COLLSCAN","filter" : {"age" : {"$eq" : 200}},"direction" : "forward"},"rejectedPlans" : [ ]},"executionStats" : {"executionSuccess" : true,"nReturned" : 1,"executionTimeMillis" : 2,"totalKeysExamined" : 0,"totalDocsExamined" : 10000,"executionStages" : {"stage" : "COLLSCAN","filter" : {"age" : {"$eq" : 200}},"nReturned" : 1,"executionTimeMillisEstimate" : 0,"works" : 10002,"advanced" : 1,"needTime" : 10000,"needYield" : 0,"saveState" : 10,"restoreState" : 10,"isEOF" : 1,"direction" : "forward","docsExamined" : 10000}},"serverInfo" : {"host" : "localhost.localdomain","port" : 27017,"version" : "4.4.6","gitVersion" : "72e66213c2c3eab37d9358d5e78ad7f5c1d0d0d7"},"ok" : 1
}
queryPlanner 部分
- plannerVersion: 表示查询优化器的版本。
- namespace: 查询涉及的集合名,即
test3.q1。 - indexFilterSet: 若为
true,表示查询使用了索引过滤器;此处为false,说明没有使用。 - parsedQuery: 显示解析后的查询条件,即查找
age字段等于200的文档。 - winningPlan: 描述被选择的执行计划。在这个案例中,执行计划的 stage 是
"COLLSCAN",意味着进行了全集合扫描(Collection Scan)。这意味着为了找到匹配的文档,MongoDB 需要遍历整个q1集合,对每个文档应用 filter 中指定的条件(age: { $eq: 200 })。 - rejectedPlans: 空数组,表示没有其他备选执行计划被否决。如果有多个可行计划,MongoDB 会选择成本最低的一个作为 winningPlan,其余的则记录在此处。
executionStats 部分
这部分提供了实际执行查询时的统计信息:
- executionSuccess: 指示查询是否成功完成,
true表示成功。 - nReturned: 返回的文档数量,这里是
1,说明找到了一个年龄为200的文档。 - executionTimeMillis: 执行查询所花费的时间(毫秒),本例中为
2毫秒。 - totalKeysExamined: 查看的索引键数量。由于未使用索引,此处为
0。 - totalDocsExamined: 查看的文档数量,即全集合扫描过程中检查过的文档总数,这里为
10000,表明集合中有 10000 个文档被逐一检查以找出符合age: 200的文档。 - executionStages: 提供了更多关于执行阶段的细节,与 winningPlan 相对应。这里再次确认了进行了全集合扫描(
COLLSCAN),并且实际查看了 10000 个文档 (docsExamined) 才找到 1 个匹配的文档 (nReturned).
serverInfo 部分
- 提供了运行 MongoDB 服务器的主机名、端口、版本号以及 Git 版本信息。
ok
- 值为
1,表示命令执行成功。
2.3、添加limit查询文档
db.q1.find({age:10}).limit(20)db.q1.find({age:10}).limit(20).explain("executionStats")
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test3.q1","indexFilterSet" : false,"parsedQuery" : {"age" : {"$eq" : 10}},"winningPlan" : {"stage" : "LIMIT","limitAmount" : 20,"inputStage" : {"stage" : "COLLSCAN","filter" : {"age" : {"$eq" : 10}},"direction" : "forward"}},"rejectedPlans" : [ ]},"executionStats" : {"executionSuccess" : true,"nReturned" : 1,"executionTimeMillis" : 4,"totalKeysExamined" : 0,"totalDocsExamined" : 10000,"executionStages" : {"stage" : "LIMIT","nReturned" : 1,"executionTimeMillisEstimate" : 1,"works" : 10002,"advanced" : 1,"needTime" : 10000,"needYield" : 0,"saveState" : 10,"restoreState" : 10,"isEOF" : 1,"limitAmount" : 20,"inputStage" : {"stage" : "COLLSCAN","filter" : {"age" : {"$eq" : 10}},"nReturned" : 1,"executionTimeMillisEstimate" : 1,"works" : 10002,"advanced" : 1,"needTime" : 10000,"needYield" : 0,"saveState" : 10,"restoreState" : 10,"isEOF" : 1,"direction" : "forward","docsExamined" : 10000}}},"serverInfo" : {"host" : "localhost.localdomain","port" : 27017,"version" : "4.4.6","gitVersion" : "72e66213c2c3eab37d9358d5e78ad7f5c1d0d0d7"},"ok" : 1
}
可以明显感受到加了
limit后查询速度变快了很多但是如果我们查询
age为9999的文档那么还是得全表扫描一遍此时我们就可以给该字段加上索引
2.4、创建索引
db.collection.createIndex(keys, options)
参数:
-
keys:
- 包含字段和值对的文档,其中字段是索引键,描述该字段的索引类型
- 对于字段的上升索引,请指定为1,对于降序指定为-1
-
options:
- 可选,包含一组控制索引创建的选项的文档
选项 类型 描述 background 布尔 是否在后台执行创建索引的过程,不阻塞对集合的操作false【默认】 unique 布尔 是否创建具有唯一性的索引 false【默认】 name 字符串 自定义索引名称,如果不指定,mongodb将通过 下划线 连接 索引字段的名称和排序规则 生成一个索引名称。一旦创建不能修改,只能删除再重新创建 partialFilterExpression Document 仅为集合中符合条件的文档建立索引,降低创建和维护成本 sparse 布尔 仅为集合中具有指定字段的文档建立索引 false 【默认】 expireAfterSeconds integer单位 秒 用于 TTL 索引中 控制 文档保存在集合中的时间 storageEngine Document 指定存储引擎配置
db.q1.ensureIndex({age:1})
查看查询计划
db.q1.find({age:200}).explain("executionStats")
> db.q1.find({age:200}).explain("executionStats")
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test3.q1","indexFilterSet" : false,"parsedQuery" : {"age" : {"$eq" : 200}},"winningPlan" : {"stage" : "FETCH","inputStage" : {"stage" : "IXSCAN","keyPattern" : {"age" : 1},"indexName" : "age_1","isMultiKey" : false,"multiKeyPaths" : {"age" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"age" : ["[200.0, 200.0]"]}}},"rejectedPlans" : [ ]},"executionStats" : {"executionSuccess" : true,"nReturned" : 1,"executionTimeMillis" : 1,"totalKeysExamined" : 1,"totalDocsExamined" : 1,"executionStages" : {"stage" : "FETCH","nReturned" : 1,"executionTimeMillisEstimate" : 0,"works" : 2,"advanced" : 1,"needTime" : 0,"needYield" : 0,"saveState" : 0,"restoreState" : 0,"isEOF" : 1,"docsExamined" : 1,"alreadyHasObj" : 0,"inputStage" : {"stage" : "IXSCAN","nReturned" : 1,"executionTimeMillisEstimate" : 0,"works" : 2,"advanced" : 1,"needTime" : 0,"needYield" : 0,"saveState" : 0,"restoreState" : 0,"isEOF" : 1,"keyPattern" : {"age" : 1},"indexName" : "age_1","isMultiKey" : false,"multiKeyPaths" : {"age" : [ ]},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2,"direction" : "forward","indexBounds" : {"age" : ["[200.0, 200.0]"]},"keysExamined" : 1,"seeks" : 1,"dupsTested" : 0,"dupsDropped" : 0}}},"serverInfo" : {"host" : "localhost.localdomain","port" : 27017,"version" : "4.4.6","gitVersion" : "72e66213c2c3eab37d9358d5e78ad7f5c1d0d0d7"},"ok" : 1
}
executionTimeMillis:执行耗时 1 毫秒。
totalKeysExamined 和 totalDocsExamined:分别检查了 1 个索引键和 1 个文档。由于使用了覆盖索引(即索引包含了查询所需的所有字段),这里的两个值相等,意味着无需额外查询文档。
查看索引
> db.q1.getIndexes()
[{"v" : 2,"key" : {"_id" : 1},"name" : "_id_"},{"v" : 2,"key" : {"age" : 1},"name" : "age_1"}
]
2.5、自定义索引名字
db.q1.ensureIndex({name:1},{name:"MyNameIndex"})
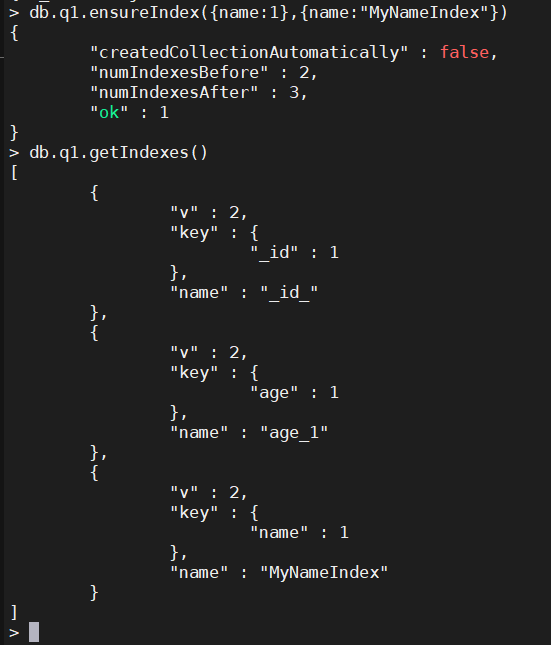
3、查看索引的大小
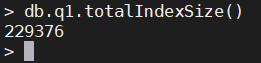
默认单位是字节
db.q1.totalIndexSize()
4、删除索引
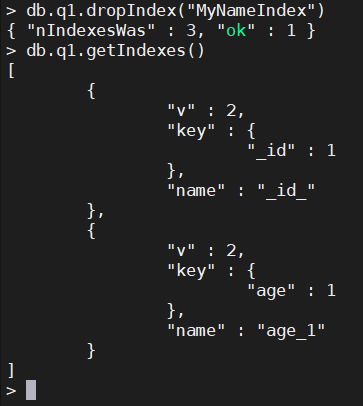
4.1、按名称删除索引
db.q1.dropIndex("MyNameIndex")
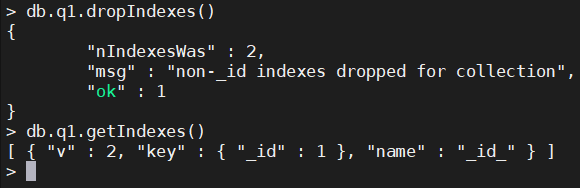
4.2、删除所有的索引
db.q1.dropIndexes()
5、优缺点
5.1、优点:
- **提高查询性能:**索引能够大大加快数据查询速度,特别是对于含有复杂查询条件、排序、分组或聚合操作的查询。
- 支持高效排序:当查询需要对特定字段进行排序时,如果该字段有索引,MongoDB可以直接利用索引来完成排序,避免了大量数据的内部排序操作,显著提升性能。
- 覆盖查询:如果一个索引包含了查询所需的全部字段,称为“覆盖索引”。在这种情况下,MongoDB可以直接从索引中获取所有数据,而无需访问实际文档,从而减少磁盘I/O操作,提高查询效率。
- 唯一性约束:创建唯一索引可以确保指定字段的值在整个集合中唯一,防止插入重复数据,确保数据完整性。
5.2、缺点:
- 占用存储空间:索引需要额外的存储空间来保存索引数据结构。随着数据量的增长和索引数量的增加,存储开销会逐渐增大。需要根据实际业务需求权衡查询性能与存储成本。
- 写操作性能影响:插入、更新和删除文档时,不仅要修改原数据,还要同步更新相关索引。对于写密集型应用,大量的索引可能导致写操作性能下降,尤其是当索引较多或索引字段频繁变动时。
- 索引维护成本:随着数据的变化,索引需要不断维护和更新。对于大型数据集,索引重建可能需要消耗较长时间和系统资源。此外,随着业务发展,可能需要定期评估和调整索引策略,以适应新的查询模式。