Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
提出了一个单、多视图融合深度估计系统,它自适应地集成了高置信度的单视图和多视图结果
动态选择两个分支之间的高置信度区域执行融合
提出了一个双分支网络,即一个以单目深度线索为目标,而另一个利用多视图几何结构,两个分支都预测深度图和置信度图
通过使用这样的置信度图来执行逐像素融合,可以最终实现更稳健的深度
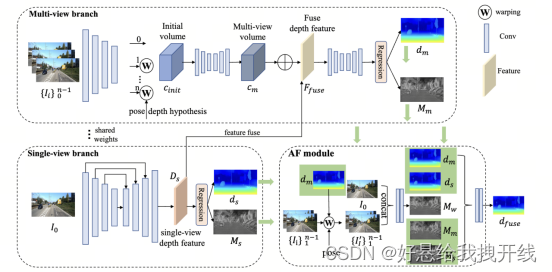
AFNet,它由三个部分组成,即单视图深度模块、多视图深度模块和自适应融合模块
Single-view branch
多尺度解码器 并获得深度特征D_s=(H/4, W/4, 257),通过对$D_s$的前256个通道使用softmax,得到深度概率P_s=(H/4 , W/4, 256)。最后一个通道作为单视图深度估计的置信度图M_s=(H/4, W/4),最后通过软加权来计算单视图深度
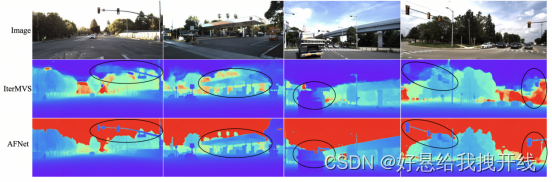
Multi-view branch
保留特征的通道维度并构建4D cost volume,然后通过两个3D卷积层将通道数量减少到1 即初始cost volume C_{init}=(H/4 , W/4, 128)使用堆叠的2D沙漏网络进行正则化 获得最终的多视图cost volume C_m=(H/4 , W/4, 256) 使用残差结构来组合单视图深度特征D_s(H/4, W/4, 257)和cost volume(H/4 , W/4, 256),以获得融合深度特征F_fuse
Adaptive Fusion Module
自适应地选择两个分支之间最准确的深度作为最终输出。单视图分支和多视图分支中的M_s和M_m反应了整体匹配歧义(reflect the overall matching ambiguity),而M_w反映了亚像素精度(subpixel accuracy)将这三个置信度图作为单视图深度d_s和多视图深度d_m融合的指导,并通过两个 2D 卷积层得到最终的融合深度d_{fuse}=(H/4 , W/4)
AFNet训练过程中的损失函数主要由深度损失和置信度损失两部分组成。深度损失使用简单的 L1 损失
对于置信度损失,为了防止异常值干扰训练,我们首先计算有效掩码如下:
最终置信度损失计算如下:
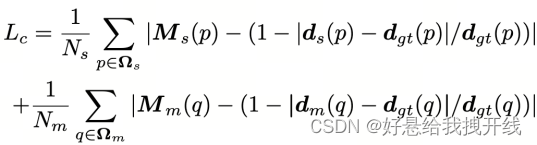
Ns和Nm分别表示Ωs和Ωm中有效点的总数。总损失是上述两个损失 Ld 和 Lc 的总和。
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
CLIP-BEVFormer框架,该框架由Ground Truth BEV (GT-BEV)模块和Ground Truth Query Interaction (GT-QI)模块组成
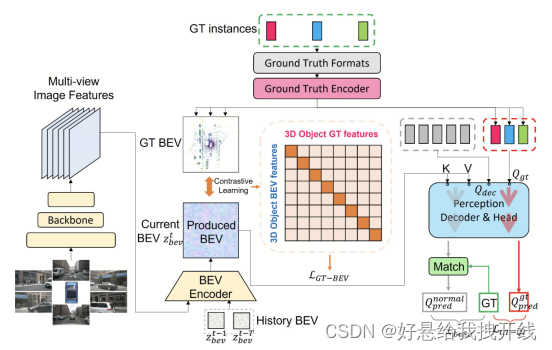
GT-BEV
GT-BEV 的核心目标是将生成的 BEV 表示与 GT-BEV 对齐,确保 BEV 元素的显式排列。为了使BEV和GT-BEV嵌入更接近,我们采用对比学习过程来优化BEV特征空间中的元素关系和距离。这种显式元素排列与 GT 引导(标签、位置和清晰边界)相结合,可以提高模型的感知能力,从而提高 BEV 地图上各种对象的检测和区分。
先前模型中先前未探索的方面在于了解GT实例如何在 BEV 图上相互交互。通过自注意力和注意力机制从空查询中恢复地面实况信息,如先前模型中使用的,本质上是有限的。这个过程充当黑盒探索,仅在端点提供监督,因此缺乏对地面实况解码的全面理解。(DETR范式在BEV上用Query的方式检测的缺陷)
因此来自 Ground Truth Encoder (GTEnc,也就是GT-BEV中从GT那一端出来的GT编码) 的 β 被引入解码器 Dec 的查询池中
GT-QI
在训练的解码阶段注入GT流,我们的 GT-QI 模块使模块能够从GT实例间交互和GT实例 BEV 通信中获得见解。注入 GT 查询的扩大查询池不仅增强了模型的鲁棒性,而且增强了它在源图上检测各种对象的能力
损失函数
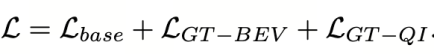
基础检测损失(空Query和BEV的Key、Value经过Decoder和Head得到的预测和GT的损失)、对比学习损失(监督BEVFormer前端和GT编码器(LLM、MLP)生成具有区分度的高质量Key、Value和Query)、Decoder损失(通过已知的Query和BEV的Key、Value,监督Decoder模块从空Query生成预测的能力)
Learning Transferable Visual Models From Natural Language Supervision (CLIP )
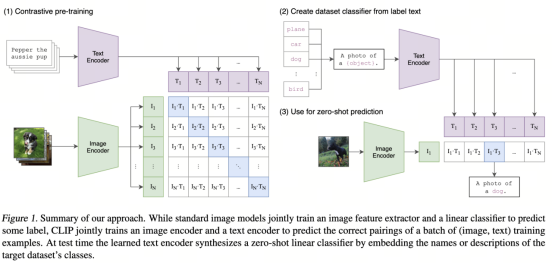
神器CLIP:连接文本和图像,打造可迁移的视觉模型 - 知乎 (zhihu.com)
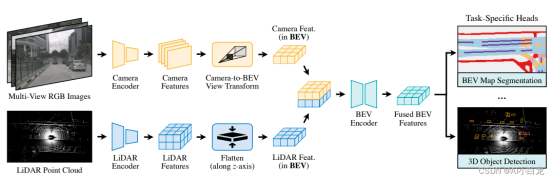
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
后融合,因为这种方案比较灵活,鲁棒性也更好 能够更好的处理单一传感器失效时对系统的影响 缺点也很多,一是信息的利用不是很充分,二是把系统链路变得更加复杂,链路越长,越容易出问题,三是当规则越堆叠越多之后维护代价会很高

前融合更好的利用神经网络端到端的特性。但是前融合的方案少有能够直接上车的,原因我们认为是目前的前融合方案鲁棒性达不到实际要求
1)雷达和相机的外参不准 2)相机噪声 3)雷达噪声
BEVFusion框架,和之前的方法不同的是雷达点云的处理和图像处理是独立进行的,利用神经网络进行编码,投射到统一的BEV空间,然后将二者在BEV空间上进行融合。这种情况下雷达和视觉没有了主次依赖,从而能够实现近似后融合的灵活性
当增加多种模态后,性能会大幅提高,但是当某一模态确实或者产生噪声,不会对整体产生破坏性结果

雷达分支我们测试了基于Voxel和基于Pillar的编码方式,Camera分支是我们对Lift-Splat-Shoot[8]进行了改造 融合模块的改进如下:

Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View
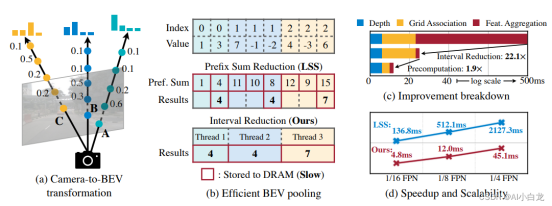
使用摄像头特征增强激光雷达点云。然而,摄像头到激光雷达的投影丢弃了摄像头特征的语义密度(semantic density),阻碍了此类方法的有效性,尤其是对于面向语义的任务(如3D场景分割)。文章特别指出:对于典型的32线激光雷达扫描,只有5%的摄像头特征与激光雷达点匹配,而其他所有特征都将被删除。对于更稀疏的激光雷达(或成像雷达),这种密度差异将变得更加剧烈
我们优化了BEV池化,解决视图转换中的关键效率瓶颈,将延迟减少了40倍。BEVFusion从根本上来说是任务无关的,无缝支持不同的3D感知任务。
BEV池化的效率和速度惊人地低,在RTX 3090 GPU上需要500毫秒以上(而模型的其余部分计算只需要100毫秒左右)。这是因为摄像头特征点云非常大,即典型的工作负载,每帧可能生成约200万个点,比激光雷达特征点云密度高两个数量级。为了消除这一效率瓶颈,建议通过预计算和间歇降低来优化BEV池化进程
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
具体的过程为:
(1)3D点云输入3D backbones获得BEV特征图
(2)初始化Object query按照下面左边的Transformer架构输出初始的边界框预测。初始化方法见3.2节
(3)上一步中的3D边界框预测投影到2D图像上,并将FFN之前的特征作为新的query features通过SMCA选择2D特征进行融合。
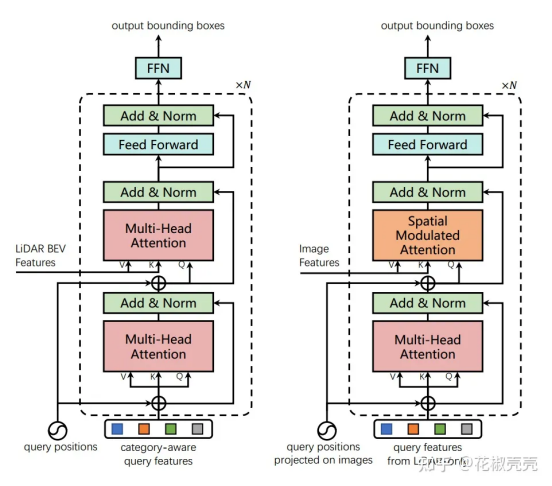
TransFusion由卷积backbone和基于Transformers解码器的检测头组成,解码器的第一层使用稀疏的object queries集预测来自LiDAR点云的初始边界框,第二层解码器自适应地将object queries与有用的图像特征融合,充分利用空间和上下文关系。Transformers的注意力机制使我们的模型能够自适应地决定从图像中获取什么信息和从什么位置获取信息
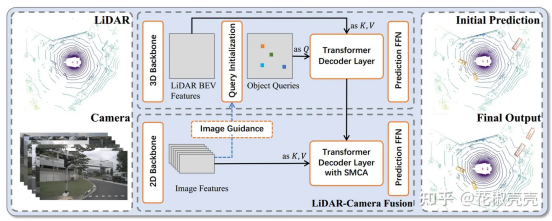
Query Initialization
通过更好的object queries初始化,可以弥补1层结构和6层结构之间的差距。受此启发,我们提出了一种基于center heatmap的输入相关初始化策略,用一个解码器实现高性能
首先预测类别热力图(X,Y,K)选择所有类别的前n个候选对象作为我们的初始object queries 选择局部最大元素作为我们的对象查询,其值大于或等于它们的8个相连的邻居 所候选对象的位置和特征用于初始化query positions和query features 我们的初始化对象查询将位于或接近潜在的对象中心,而不需要多个解码器层来细化位置
我们往每个object queries中放入一个类别嵌入 每个被选中候选的类别,我们对object query和category-embedding逐元素求和 类别嵌入通过将one-hot类别向量线性投影到维度为d的向量得到
参考DETR3D,我们采用了辅助解码机制,在每个解码层后增加了FFN和监督
Image-Guided Query Initialization
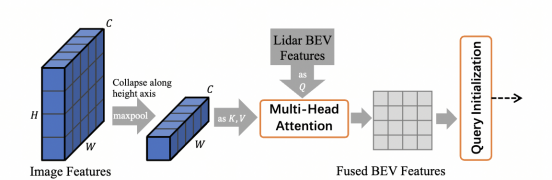
折叠操作基于我们的观察,认为BEV位置和图像列(image columns)之间的关系可以很容易地使用相机几何关系(camera geometry)建立,通常每个图像列最多有一个对象。因此沿高度折叠可以显著减少计算而不会丢失关键信息,尽管在这个过程中可能会丢失一些细粒度的图像特征,但我们只需要对潜在对象位置的提示
DeepInteracion
所有现有的将图像信息聚合到3D的空间,与3D信息聚合到2D透视空间的方法,都是将某个模态的信息聚合到另一个模态最终形成一个模态的表示方式。最新融合方案将图像和点云特征合并为一个联合鸟瞰图(BEV)表示。然而,这种融合方法在结构上受到限制,因为它的内在局限性是,由于大部分不完美的信息融合到统一的表示中,可能会降低很大一部分特定于模态的表示优势
本研究引入了一种用于多模态3D物体检测的新型模态交互策略 关键思想是,我们学习并维护两种特定于模态的表示,而不是派生一个融合的单一表示,从而实现模态间的交互,从而自发地实现信息交换和特定于模态的优势
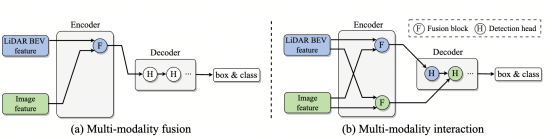
将3D点云和2D多视图图像并行映射为LiDAR BEV特征和图像透视特征,并使用两个独立的特征主干。随后,编码器以双边方式交互这两个特征以进行渐进式信息交换和表示学习。为了充分利用单模态表示,进一步设计了解码器/头,以级联方式进行多模态预测交互
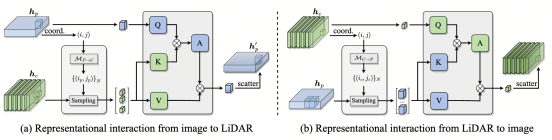
关键见解是,我们保持两种特定于模态的特征表示,并进行表征和预测交互,以最大限度地探索它们的互补优势,同时保留各自的优势
DeepInteraction 分别学习了3D激光雷达和2D图像模态的两种表示,同时通过模型编码和解码进行多模态交互
由两个主要组件组成:具有多模态表征交互的编码器(第3.1节)和具有多模态预测交互的解码器
Encoder: Multi-modal representational interaction
MMRI(交互查询注意)
第一个分支如左图(a)所示
直接利用空间预定义的点位置3D-2D得到图像上的投影点(OFT),此时以3D空间中点对应的BEV网格为Query(或者对应有网格的那个柱子是Query),图像的2D点采样出的图像像素特征是K和V(这里其实就是BEVFormer中cross-attention的方法)
第二个分支如右图(b)所示
首先将点云投影到相机坐标系3D-2D,形成稀疏的深度图,并进行深度补全(In Defense of Classical Image Processing: Fast Depth Completion on the CPU)从而得到稠密深度图。稠密的深度图覆盖了所有的图像像素,那么直接利用2D-3D原理将带有深度信息的像素点嵌入到BEV网格空间中。此时认为每个图像稠密深度图对应的图像像素特征是Query,而其投影到3D空间中的对应BEV的特征是K和V(对应柱位置的)
Decoder: Multi-modal predictive interaction
引入了具有多模态预测相互作用(MMPI)的解码器,以最大限度地提高预测中的互补效果
核心思想是在一个模态的条件下增强另一个模态的3D物体检测
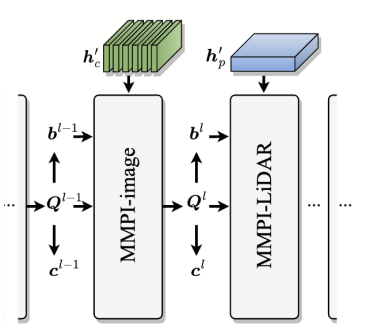
首先给定初始化的N个Query,然后开始不断refine直到m次。详细的结构如下图:

通过交互堆叠两个模态的信息来实现信息的深度交互,也就是不断去refine网络的预测\
Multi-modal predictive interaction on image representation (MMPI-image)
对于前一层网络的预测N个框b和前一层的Query,以及当前层的图像输入hc'(D),首先需要从图像中提取对应个数的感兴趣的RoI,维度就是N, C, S, S。然后对于每个边界框b,3D-2D投影到图像上得到二维凸多边形(具体来说可以是四边形和六边形)并取最小的轴向边界矩形(得到矩形框)
同时设计了一个多模态交互算子先把Query进行通道映射和RoI区域特征的维度一致然后乘积叠加,经过两层融合作为增强的信息
Multi-modal predictive interaction on LiDAR representation (MMPI-LiDAR)
对于激光雷达表示的RoI,我们将前一层的3D边界框投影到激光雷达BEV表示中,并取最小的轴向矩形。
由于自动驾驶场景中物体的尺度在BEV坐标系中通常很小,所以我们将3D边界框的尺度放大了2倍
Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
作者单位:MEGVII Technology
论文:https://arxiv.org/pdf/2301.01283.pdf
代码:https://github.com/junjie18/CM
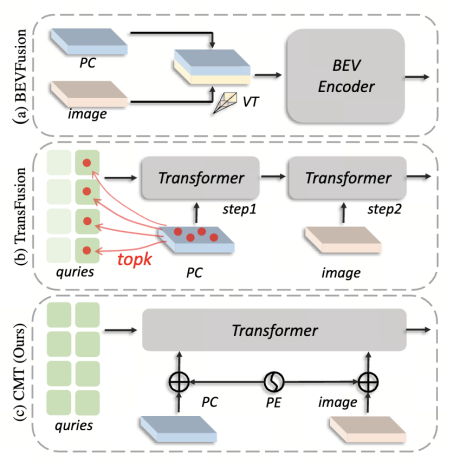
上图是本文之前的所有融合的一些范式,包括BEV直接融合,以及TransFusion的BEV热点初始化查询信息。
CMT通过空间中的锚点来显示构建查询的Query,原理基于单模态的PETR。
•我们提出了一个快速和强大的3D探测器,这是一个真正的端到端框架,没有任何后处理。它克服了传感器缺失的问题。
•3D位置被编码成多模态标记,没有任何复杂的操作,如网格采样和体素池。
•CMT在nuScenes数据集上实现了最先进的3D检测性能。它为未来的研究提供了一个简单的基准。
将多视图图像和激光雷达点馈送到两个单独的骨干中以提取多模态标记。通过坐标编码将3D坐标编码为多模态标记(图像和点云特征各自有一套编码结果并叠加到原始提取的特征中)。
Coordinates Encoding Module(CEM)
对于图像特征,采用的是PETR的相机坐标系下的一系列预定的视锥点云,通过相机内参和外参得到在BEV空间中的预定一点:N, D, H, W, 4,经过MLP层得到位置编码向量N, H, W, C
对于BEV特征, 由于使用的是VoxelNet或者PointPillar的编码方式,也就直接是BEV坐标系下的网格点坐标Z, H, W, 4
Position-guided Query Generator
Masked-Modal Training for Robustness
在本文中,我们尝试了更极端的故障,包括单摄像头脱靶、摄像头脱靶和LiDAR脱靶,如图4所示。
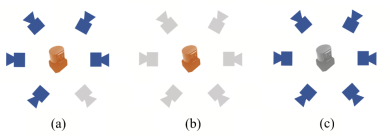
提出了一种称为掩模训练的训练策略。在训练过程中,我们随机只使用一种模式进行训练,如相机或激光雷达,其比值为η1和η2。该策略确保了模型在单模态和多模态下都得到了充分的训练。
SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
作者单位:MEGVII Technology
论文:https://arxiv.org/pdf/2403.10353.pdf
代码:https://github.com/nullmax-vision/SimPB
引入了一个用于 2D 和 3D 物体检测的混合解码器。在 3D-2D-3D 循环方案中,
采用动态查询分配和自适应查询聚合模块不断更新和细化 2D 和 3D 结果之间的交互
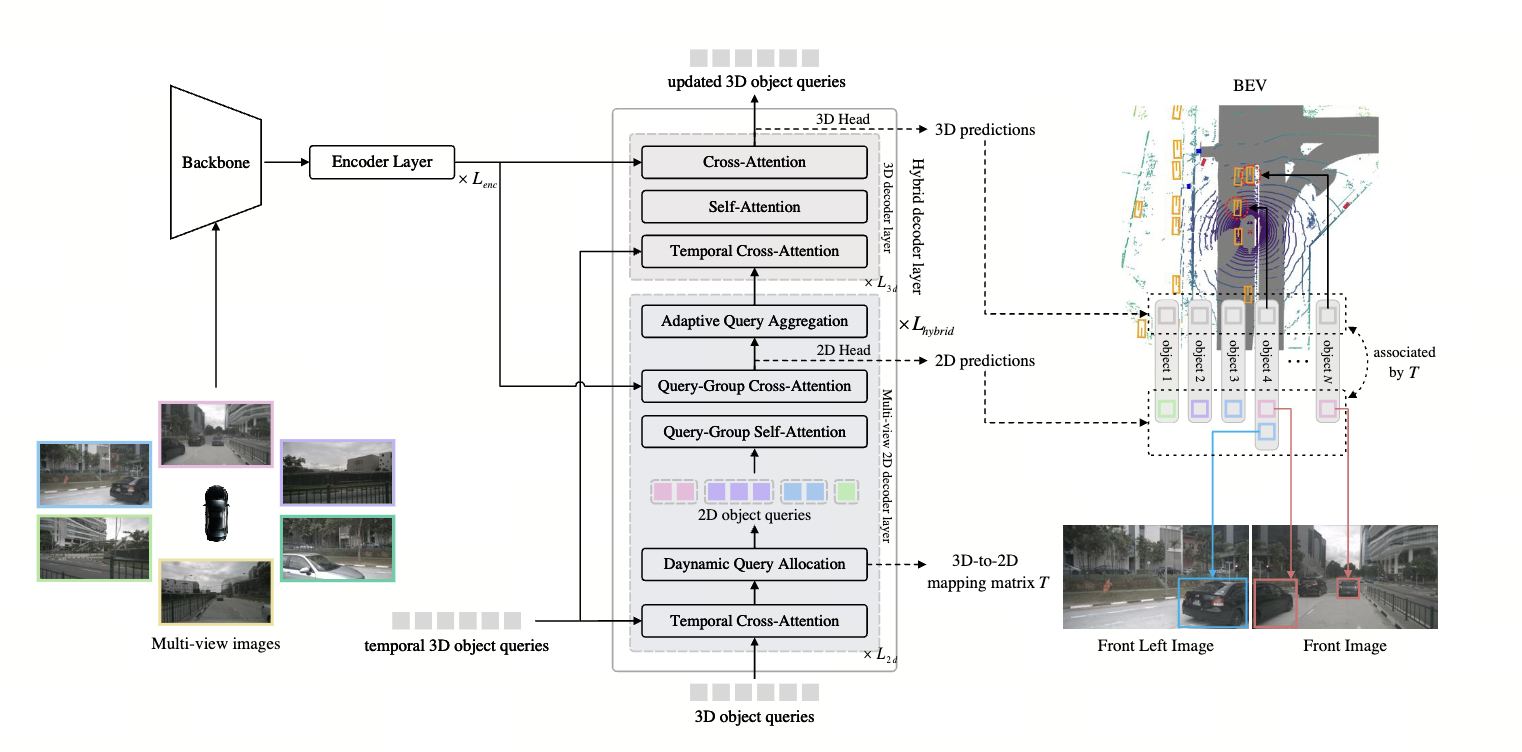 动态查询分配模块
动态查询分配模块
投影 3D 锚点: 将形状为 (N, 9) 的 3D 锚点通过相机内参 (3x3) 和外参 (4x4) 投影
到 V 个相机视图(V, Ci, Hi, Wi)上,得到每个锚点在每个视图上的投影坐标,形状为 (N,
V, K, 2), 其中 K 是投影点的数量 (论文中使用 9 个点,包括中心点和 8 个角点),N 是
3D 锚点个数,V 是相机数量,2 表示一个图像点的坐标维度
判断有效性: 根据投影坐标是否在图像范围内判断每个 3D 锚点在每个视图上的有
效性,得到形状为 (N, V) 的有效性矩阵,其中元素为 1 表示有效,0 表示无效。
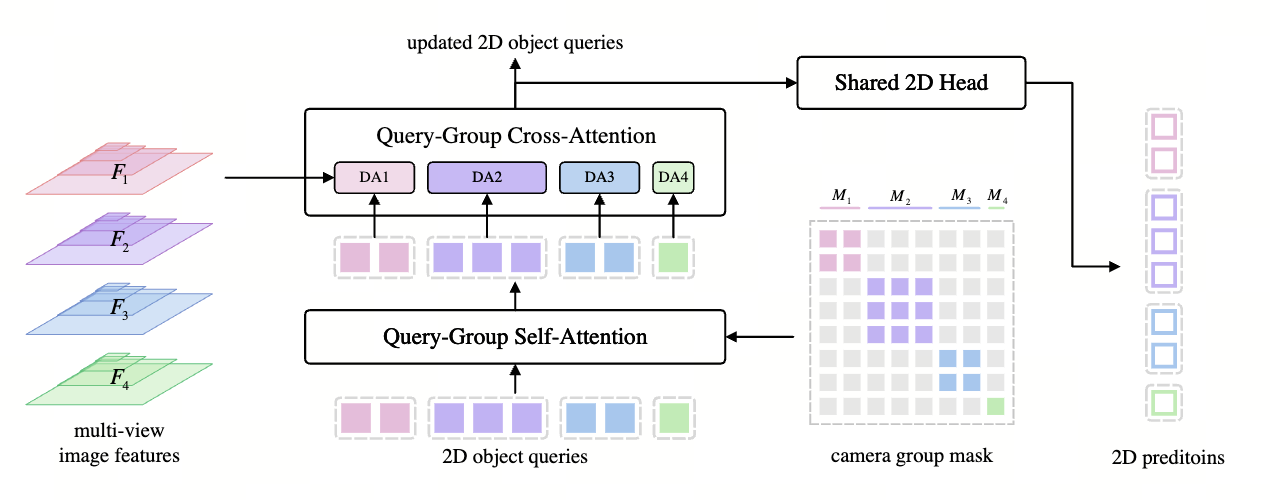
进入自适应查询聚合模块,如下图所示: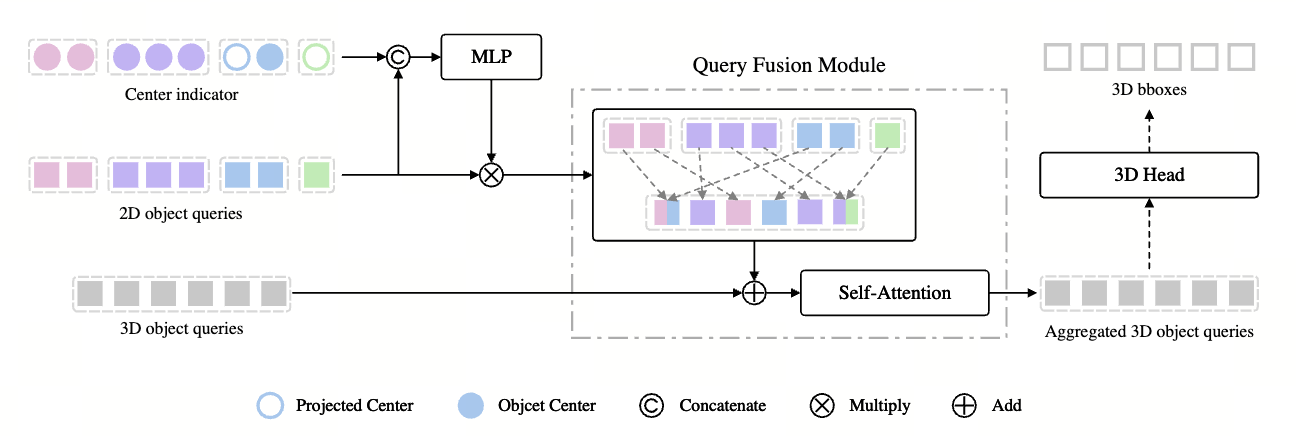
Center indicator 表示了在一个 3D 查询反投影到 2D 之后(8 点+中心点投影),是否
被截断了(同时出现在多个视图)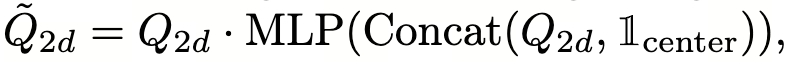
UniTR
论文:https://arxiv.org/pdf/2308.07732.pdf
代码:https://github.com/Haiyang-W/UniTR
与以前的特定于模态的编码器不同,UniTR 的 Transformer 在模态间共享,并行处理
来自多传感器的数据,并在没有额外融合步骤的情况下自动集成它们。我们设计了再
DSVT 上扩展的两个主要 transformer blocks,一种是模态内 block(intra-model
block),便于并行计算来自每个传感器的模态表示,另一种是通过考虑 2D 视角和 3D
几何关系来执行跨模态特征交互的模块(inter-model block)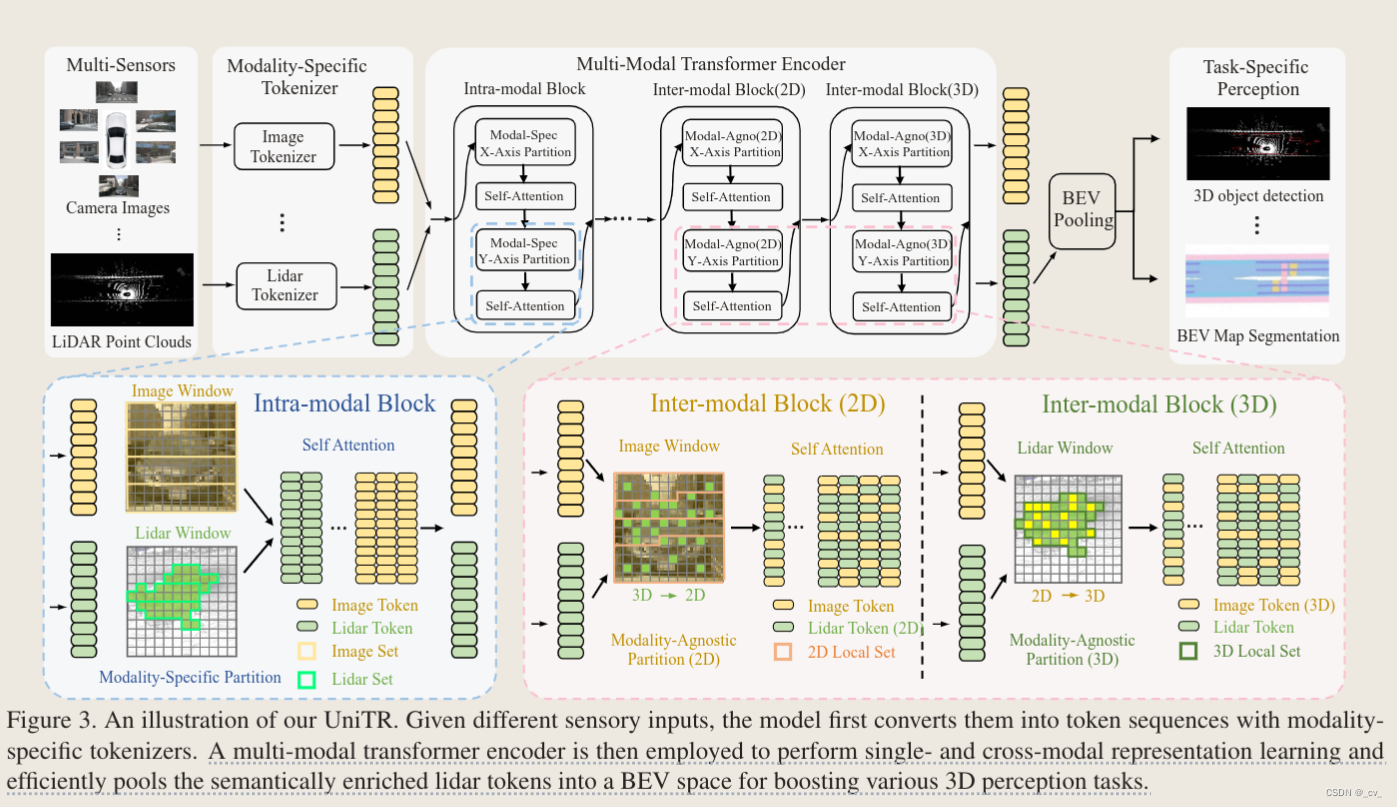 输入是 camera 和 lidar 的 token,然后在 intra-model block 里面各自做 self-
输入是 camera 和 lidar 的 token,然后在 intra-model block 里面各自做 self-
attention,做完之后在 inter-model block(2D)里面把 3D lidar 投影到 2D(这一步用的
内外参),做自注意力操作,然后在 inter-model block(3D)里面把 2d 图像投影到 3d
DSVT
论文提出了动态稀疏窗口注意力,这是一种新的基于窗口的注意力策略,用于并行有效地处理稀疏三维体素。
论文提出了一种可学习的 3D 池化操作,它可以有效地对稀疏体素进行下采样,并更好地编码几何信息
基于上述关键设计,论文介绍了一种高效但易于部署的 Transformer 3D 主干,无需任何定制 CUDA 操作。
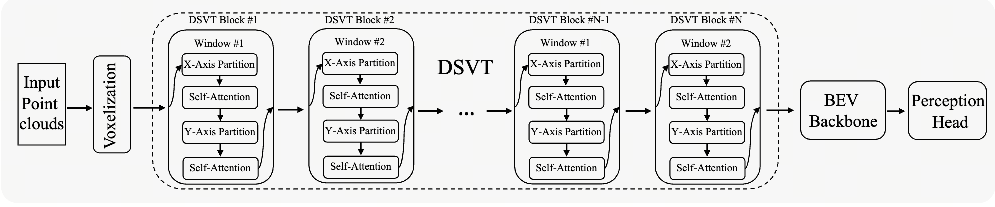 动态稀疏窗口注意力
动态稀疏窗口注意力
对于输入的一帧点云,通常是[N, 4],先经过标准的 Voxelization、VFE、Scatter 得到空间 BEVVoxel 特征[C, D, H, W],将 BEV 特征划分为 M 个窗口,其中每个窗口的大
小为[L', H', W']也就是总共有 L'*H'*W'个 Voxel。
为了方便讨论,假设使用的是 Pillar 模式,此时 D=1,在 BEV 视角下,有 BEV 特征[C,
H, W],划分为 M 个窗口,其中每个窗口大小为[H', W'],也就是每个窗口有 H'*W'个
Pillar(有些是空的,有些是有值的),如下图所示,有颜色的表示有值的 Pillar,其
余的 Pillar 为空值:
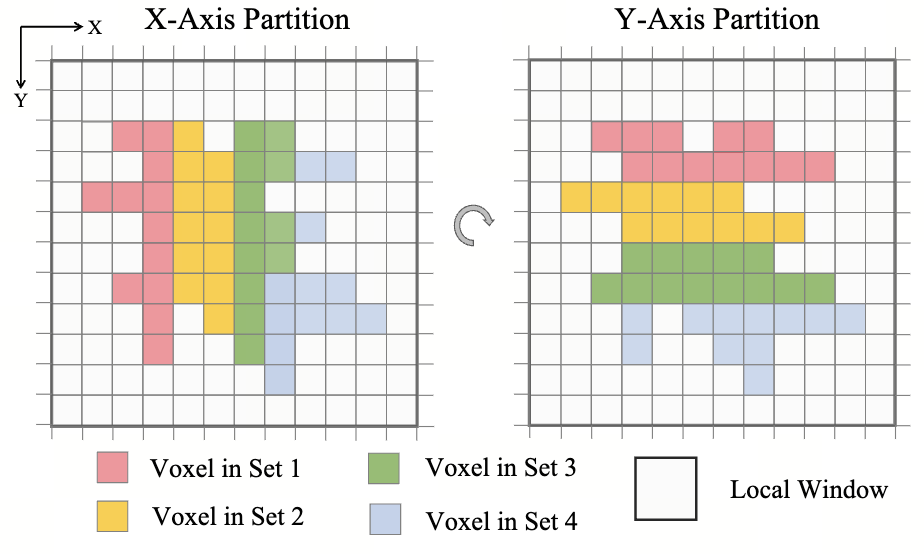
以下操作的 M 个窗口是并行处理的:
第一步:认为窗口中的所有非空的 Pillar 具有一个 Rank(0~N-1),文章定义为沿着BEV 的 X 轴和 Y 轴两种方式为非空的 Pillar 编码 Rank:然后需要将所有 N 个 Pillar 划分为认为定义的 S 个子集,其中认为给定超参数 tau,表示一个子集最多有几个 Pillar 组成,那么 N 个 Pillar 可以划分的子集个数 S 如下公式计算: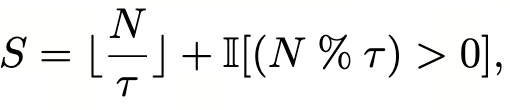
前者先把 N 先整除人为定义的 tau,由于是向下取整,如果 N 无法被 tau 整除则表示
有余数,那么直接多加一个子集,否则就刚好是 S 个子集,如上图所示可以看到按照
X 和 Y 方式划分出了 4 个子集,每个子集最大的 Pillar 数为 tau。
因此对于第 j 个子集的第 k 个 Pillar,其在整个 Rank(0~N-1)的唯一编号可以被计算
为: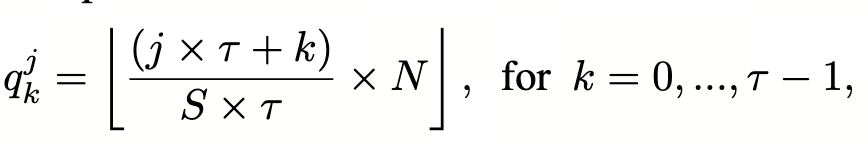
也就是说,通过改变 Rank 的排序方式(X 排和 Y 排),每个子集可以提取到 tau 长度
的 Pillar,以及 Pillar 对应的坐标
第二步,对于每个子集 j,总共 S 个子集,则有[S, tau, C]的划分 Pillar,在每个子集上
进行注意力机制。
按照文章流程图,分别进行窗口划分 -X 排序分子集 -子集内自注意力 -Y 排序分子集 -
子集内自注意力 -的形式构成一个 DSVT 块,多个 DSVT 块堆叠得到了最终结果。
平衡性能和效率: 较小的窗口可以更好地处理小物体和细节信息,而较大的窗口可
以扩大感受野并减少计算量。混合窗口划分可以在这两者之间取得平衡。
适应不同尺度的物体: 不同大小的窗口可以更好地处理不同尺度的物体,从而提高
模型的整体性能。
注意力池化
具体操作步骤:
1. 填充: 对于一个大小为[H‘, W']的窗口区域,首先将其填充为密集的格式。这意味着
将所有空的体素位置都填充为 0。
2. 最大池化: 对填充后的密集区域进行最大池化操作,得到一个大小为 1 x 1 x C 的特
征向量。
3. 构建查询、键和值:
将最大池化后的特征向量作为查询向量 (Q)。
将原始未池化的特征图作为键 (K) 和值 (V) 向量。
4. 注意力计算: 使用查询向量 Q、键向量 K 和值向量 V 进行注意力计算。具体可以使用 Scaled Dot-Product Attention 或其他注意力机制。
5. 输出: 注意力计算的结果即为池化后的特征,它包含了原始特征图中最重要的信
息,并且尺寸更小。
注意力式 3D 池化: 在部分 DSVT Block 之间插入注意力式 3D 池化模块,对体素特征
图进行下采样,并更好地编码几何信息。
DSVT 流程总结
1.
点云输入: 将原始点云数据作为模型的输入。
2. 体素化并初步提取特征: 将点云数据体素化,并提取每个体素的特征 (例如点的反射强度、颜色等) 和体素是否非空的信息。
3. 连续的多个 DSVT 块:
每个 DSVT 块内部包含两个 DSVT Layer,分别进行 X 轴排序划分和 Y 轴排序划分,并在每个子集内进行自注意力计算。部分 DSVT 块之间可能插入注意力式 3D 池化模块,对体素特征图进行下采样。
4. BEV 主干 (可选): 将提取到的体素特征投影到 鸟 瞰图 (BEV) 特征图中。这一步取决于具体的任务需求,例如 3D 目标检测通常需要 BEV 特征图。
5. 任务头: 根据不同的 3D 感知任务,添加不同的任务头,例如目标检测头或语义分割头。
DSVT 的优势:
• 高效: 通过动态集合划分和并行计算,DSVT 可以高效地处理稀疏点云数据。
• 有效: 旋转集合注意力机制和注意力式 3D 池化模块,可以帮助模型更好地捕捉空间关系和几何信息,提高模型的性能。
• 易于部署: DSVT 无需自定义 CUDA 操作,可以使用深度学习框架中的标准操作实现,因此易于部署。
Swin-Transformer
ICCV2021 - 微软研究院
论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原论文地址: https://arxiv.org/abs/2103.14030
文章中作者为了解决该问题所用的方法:
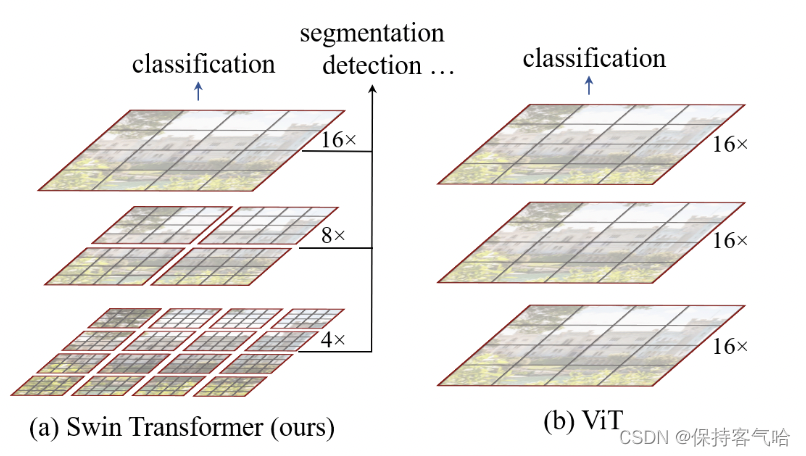
• 引入 CNN 中常用的层次化构建方式(Hierarchical feature maps)构建层次化
Transformer
• 提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此
方法能够让信息在相邻的窗口进行传递
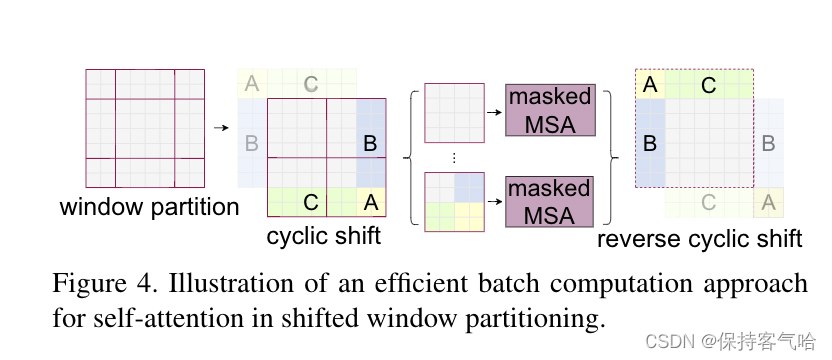
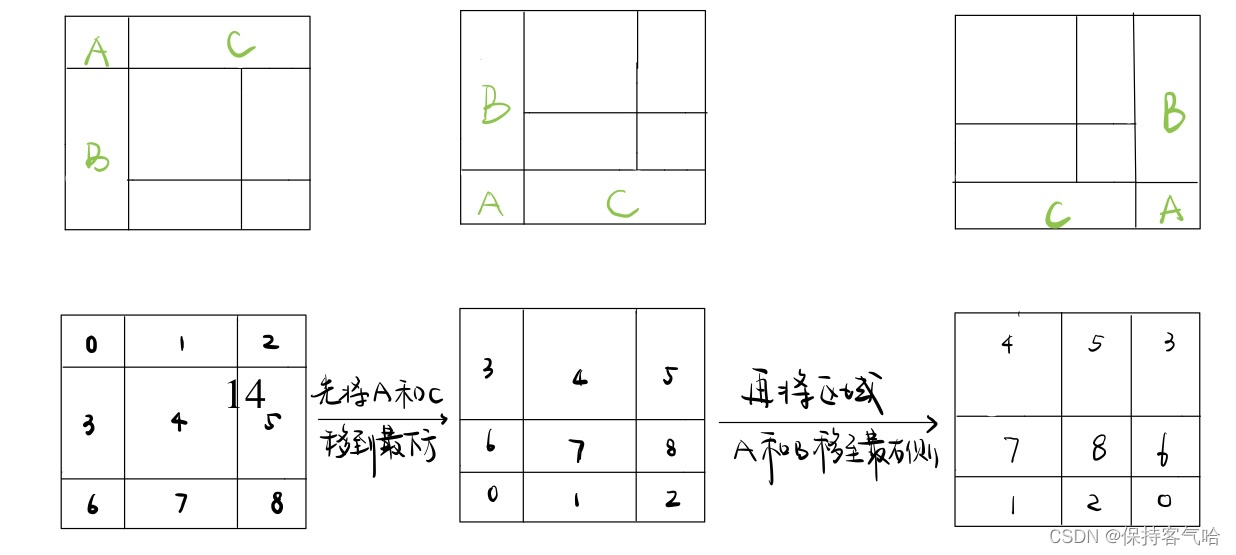
通过限制在窗口内使用自注意力,带来了更高的效率并且通过移动,使得两个窗口有
了交互,上下层之间也就有了跨窗口链接,从而变相达到一种全局建模的效果。另外
层级式的结构不仅非常灵活的去建模各个尺度的信息并且计算复杂度随着图像大小线
性增长。
Swin-Transformer 使用窗口多头自注意力,将特征图划成多个不相交的区域,然
后在每个窗口里进行自注意力计算,只要窗口大小固定,自注意力的计算复杂度也是
固定的,那么总的计算复杂度就是图像尺寸的线性倍,而不是 Vit 对整个特征图进行全
局自注意力计算,这样就减少了计算量,但是也隔绝了不同窗口之间的信息交流,随
之作者提出后文的移动窗口自注意力计算
Shifted Windows Multi-Head Self-Attention(SW-MSA)