1.文件是什么
所谓的"文件"是一个广义的概念.
可以代表很多的东西.
操作系统里,会把很多的 硬件设备 和 软件资源 都抽象成"文件",统一进行管理,但是大部分情况下,谈到的文件,都是指硬盘的文件.
文件就相当于是针对"硬盘"数据的一种抽象,
- 机械硬盘 (HDD):适合顺序读写,不适合随机读写
- 固态硬盘(SSD):效率更高->里面就都是集成程度很高的芯片了(类似于 cpu, 内存)
服务器开发中,涉及到的硬盘,有的是机械硬盘有的固态硬盘~~尤其是一些用来存储大规模数据的机器,仍然是机械硬盘为主.
当然,即使是固态硬盘,读写速度,还是比 内存 要低很多的~~
总结:内存 vs 硬盘
1.内存的速度快, 硬盘速度慢
2.内存空间小,硬盘空间大
3.内存贵, 硬盘便宜
4.内存的数据,断电就丢失,硬盘的数据断电还在
2.树型结构组织 和 目录
我们是用文件的方式操作硬盘。
一台计算机上,有很多的文件,这些文件是通过"文件系统"(操作系统提供的模块)来进行组织的
操作系统,使用"目录(其实就是文件夹directory)"这样的结构,来组织文件的. 树形结构.
找到文件的部分就是根节点
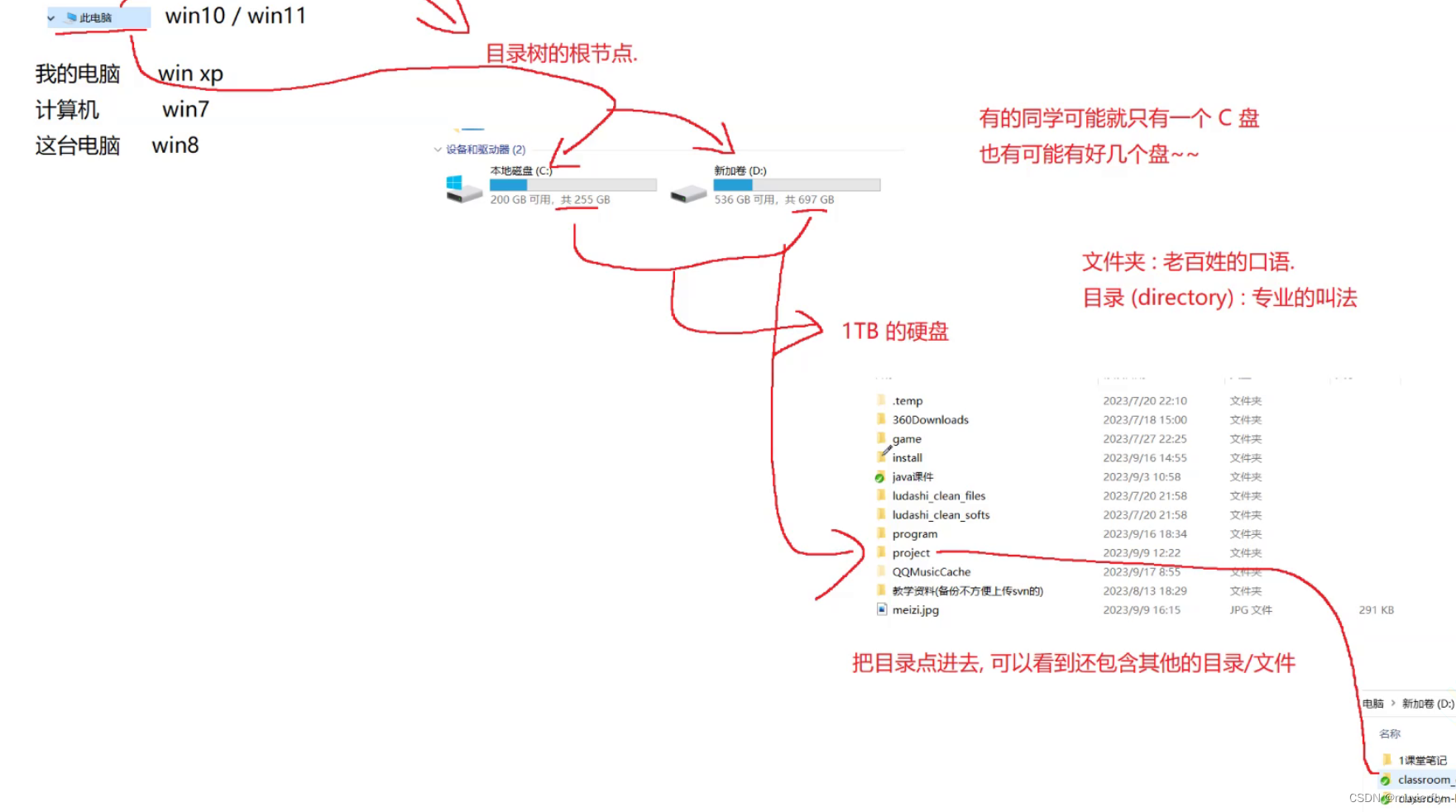
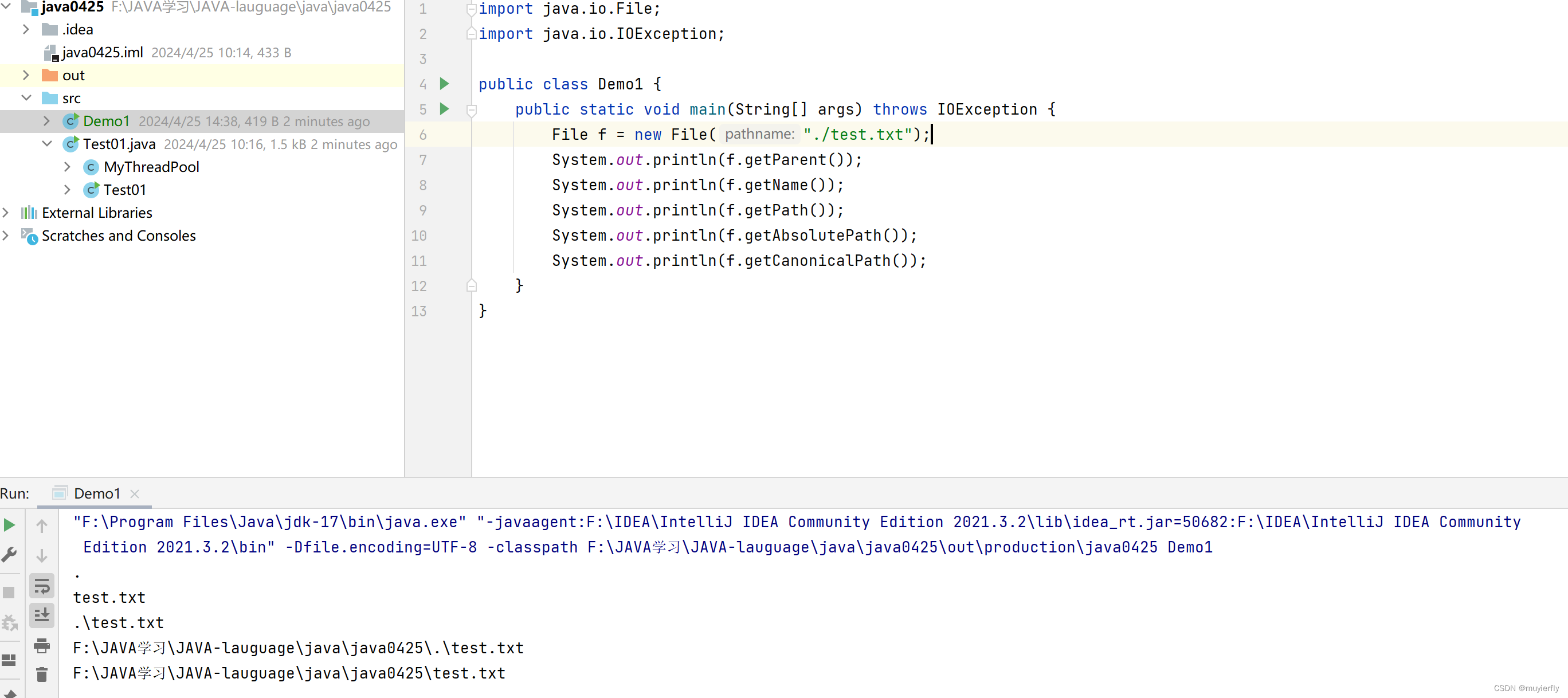
3.文件路径(Path)
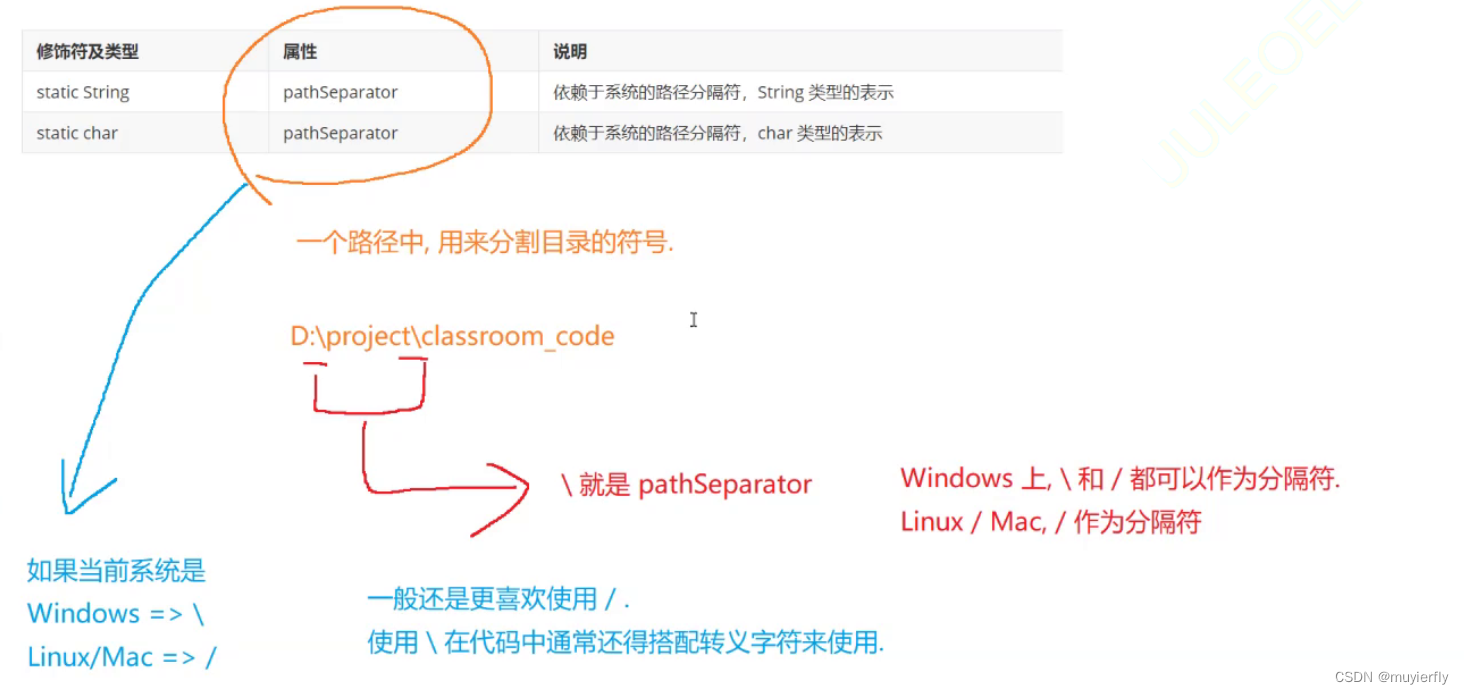
就可以使用 目录的 层次结构,来描述,文件所在的位置."路径"
D:\project\1课堂笔记yjava109 0917 多线程.png
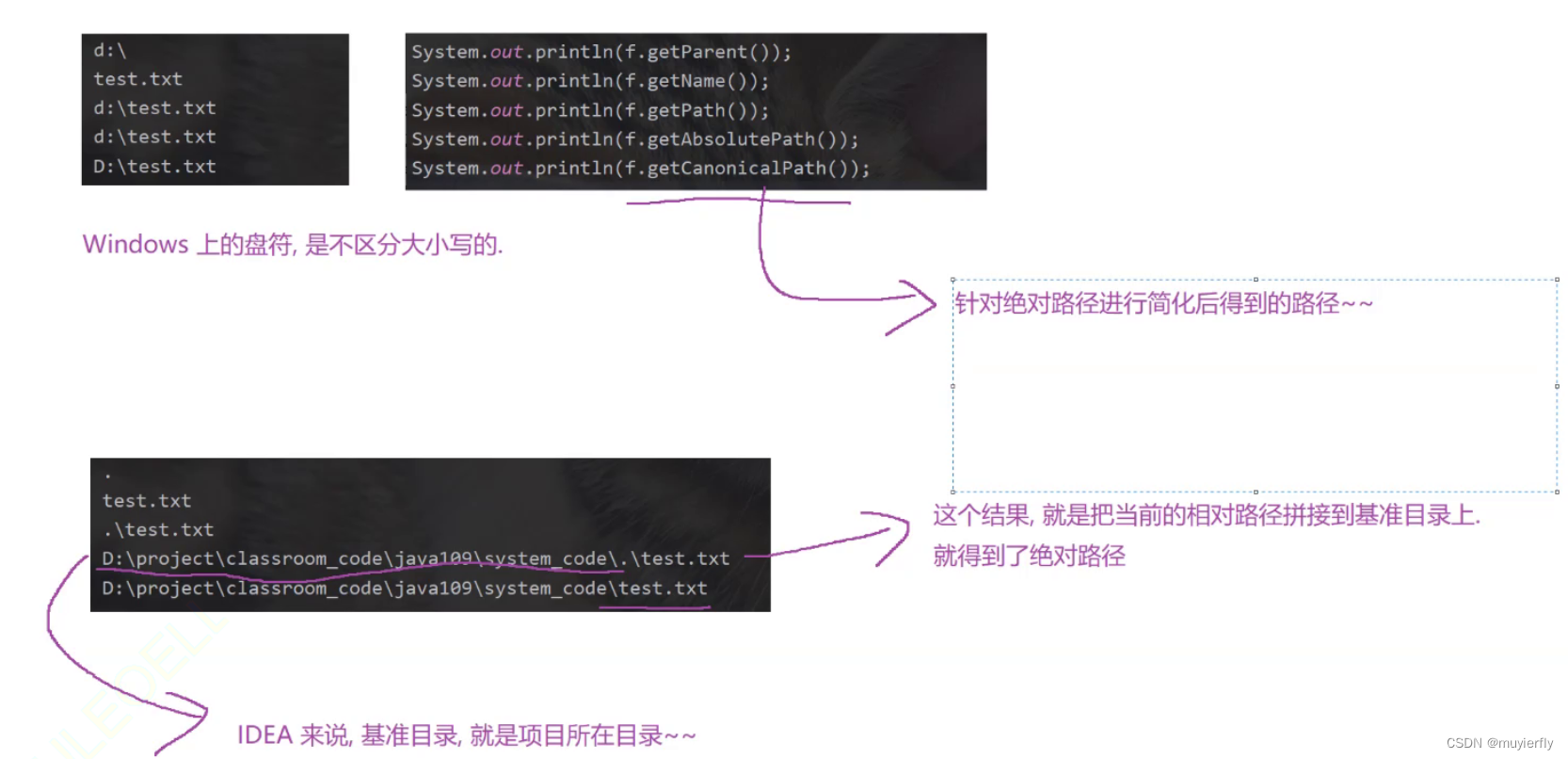
形如这样的一个字符串,体现出了当前文件在哪个目录中就可以通过文件路径,来确定当前文件具体所在的位置了1.绝对路径: 是以 C:D: 盘符开头的,这种路径称为"绝对路径"
2.相对路径:需要先指定一个目录,作为基准目录.从基准目录出发,看看沿着啥样的路线能够找到指定文件..此时涉及到的路径就是"相对路径!往往是以.或者.开头的(.这种情况可以省略).当前目录
..上一层目录
4.文件类型
文件类型.
从编程的角度看,文件类型,主要就是两大类
1.文本 (文件中保存的数据,都是字符串.保存的内容都是 合法的字符)
2.二进制 (文件中保存的数据, 仅仅是二进制数据.不要求保存的内容是 合法的字符)
本身计算机存储的数据都是二进制的。
什么叫合法的字符???
字符集/字符编码utf8
有一个大的表格.就列出了什么字符,对应到什么编码如果你的文件是 utf8 编码的此时文件中的每个数据都是合法的 utf8 编码的字符就可以认为这个文件是文本文件了如果存在一些不是 utf8 合法字符的情况,就是二进制了【如何判定一个文件是文本还是二进制?】【简单有效的技巧】
就直接使用记事本,打开这个文件如果打开之后,乱码,文件就是二进制。否则就是文本.
(记事本就是尝试按照字符的方式来展示内容,这个过程就会自动查码表)
很多文件都是二进制的. tocx, pptx...都属于二进制的.
区分文本和二进制,是很重要的!!
写代码的时候,文本文件和二进制文件,代码编写方式是不同的!!!
5.JAVA中操作文件
Java 针对文件的操作,分成两类
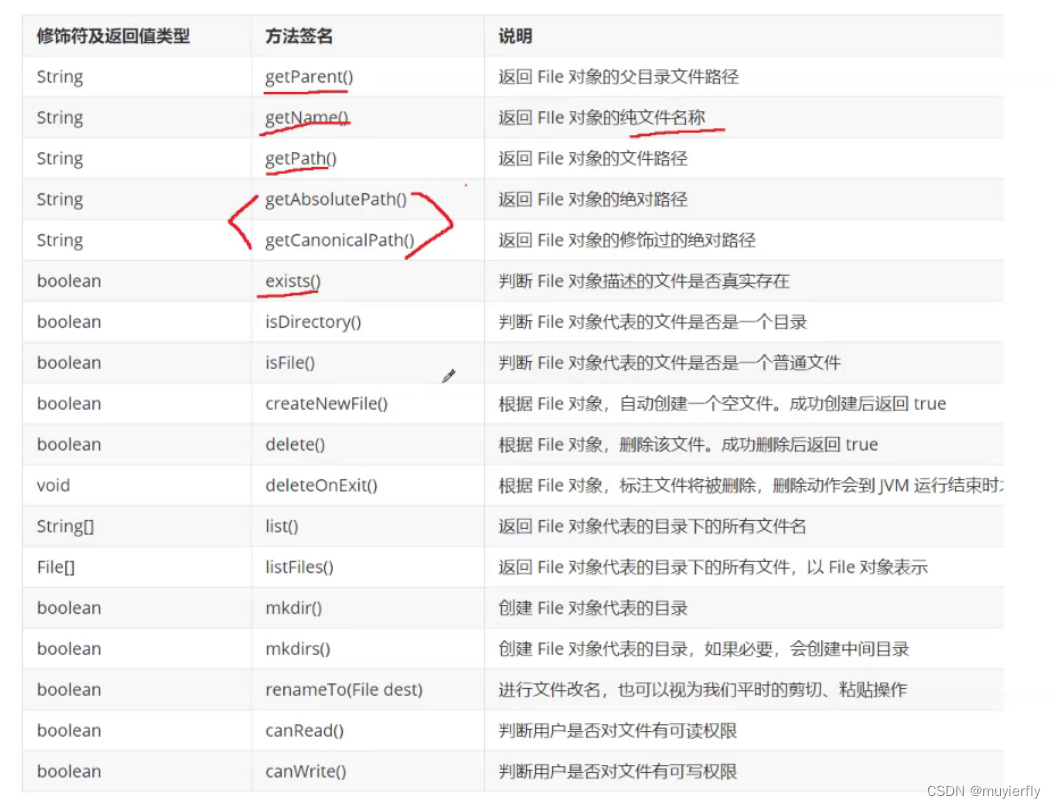
1.文件系统的操作.(File)
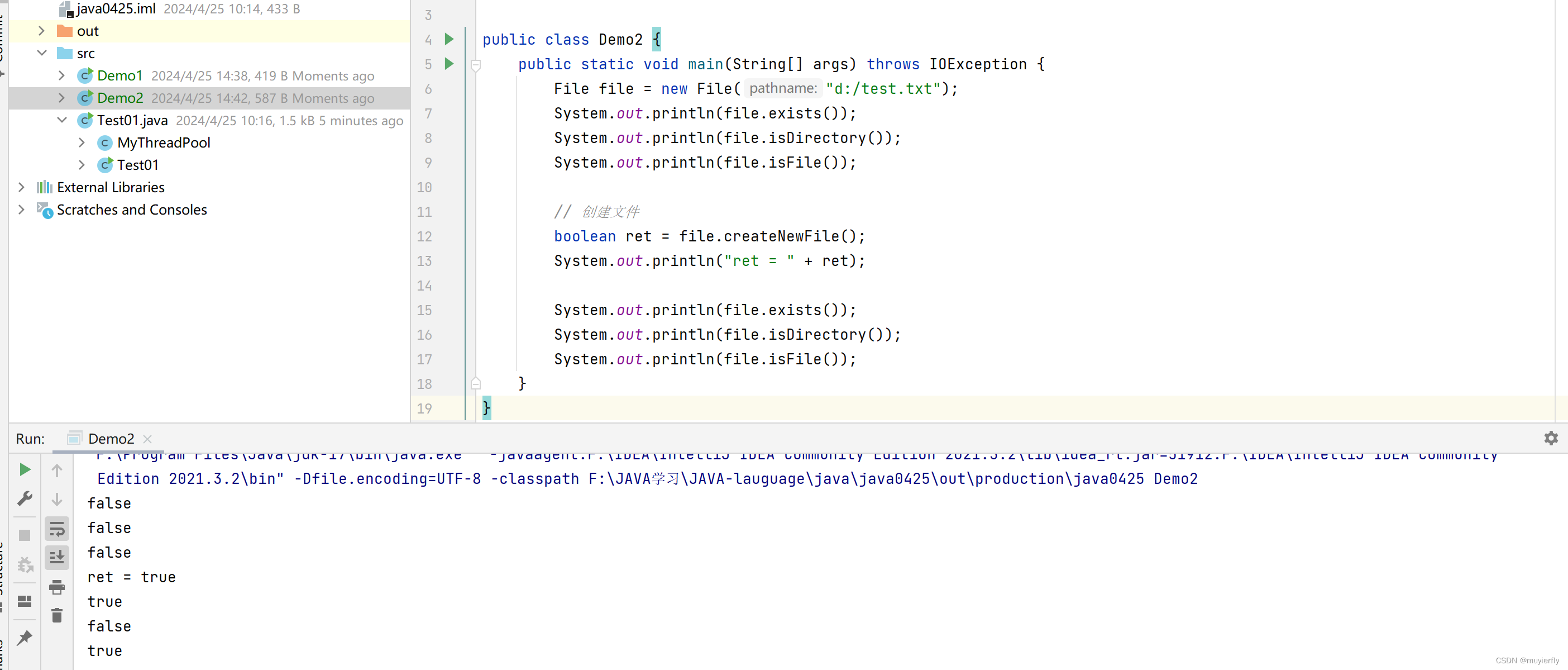
创建文件, 删除文件, 判定文件是否存在, 判定文件类型,重命名.….
2.文件内容的操作.(流对象)
读文件/写文件
- 属性
- 构造一个对象
- 方法
//文件名 = 前缀 + 扩展名
//使用路径构造 File 对象,一定要把前缀和扩展名都带上//canRead,canWrite一般文件系统上都会对文件有权限的限制,(这个事情在 Windows 上不太明显)很多同学, Windows 系统里的用户都是管理员管理员的权限最大,可以无视文件本身的权限(约定了这个文件, 哪些用户可以读, 哪些用户可以写~~)

执行效果
创建文件
//删除文件
java">import java.io.File;public class Demo3 {public static void main(String[] args) throws InterruptedException {File f = new File("d:/test.txt"); // boolean ret = f.delete(); // System.out.println("ret = " + ret);f.deleteOnExit();Thread.sleep(5000);System.out.println("进程结束!");} }//生活中的例子
office 软件, 在编辑一个文件的时候,就会自动的产生一个隐藏的文件,会在你关闭文件的时候自动删除掉.
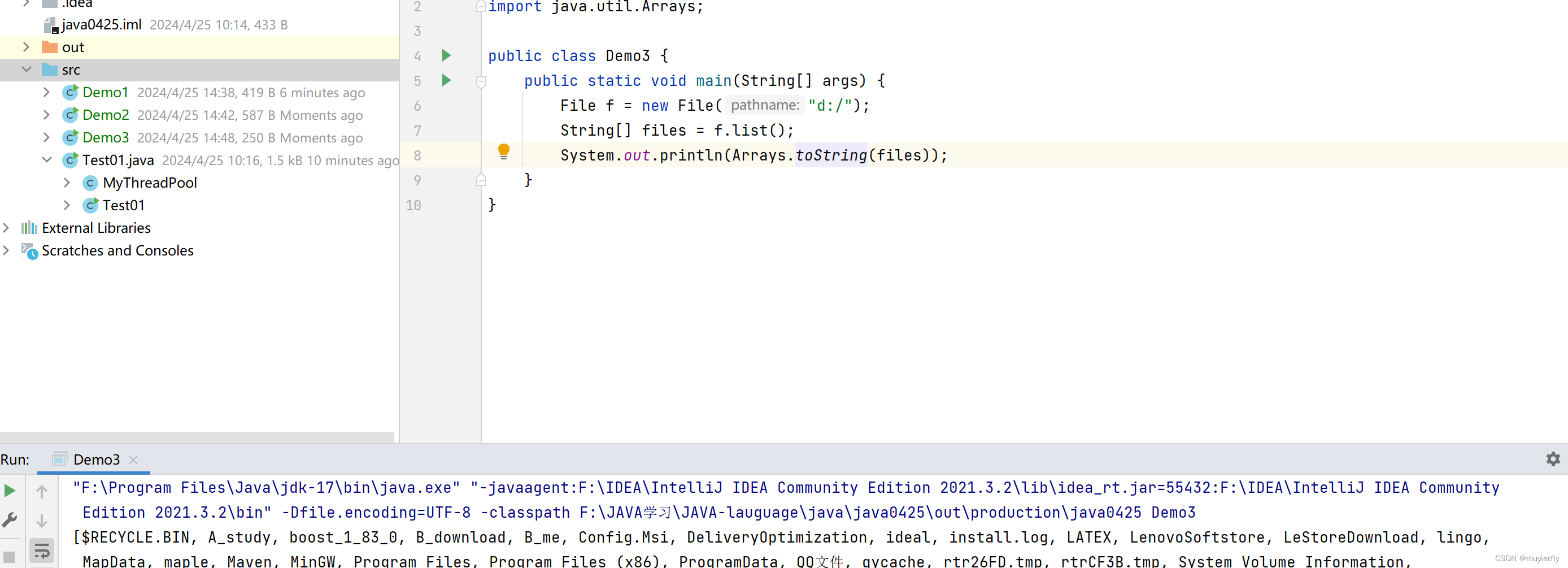
//列出文件目录
通过调用 hashCode 方法
在 JVM 上层, Java 代码中,是没有任何办法获取到"内存地址"的要想拿到内存地址,只能靠 native 方法, 进入 JVM 内部, 通过C++代码获取到~~
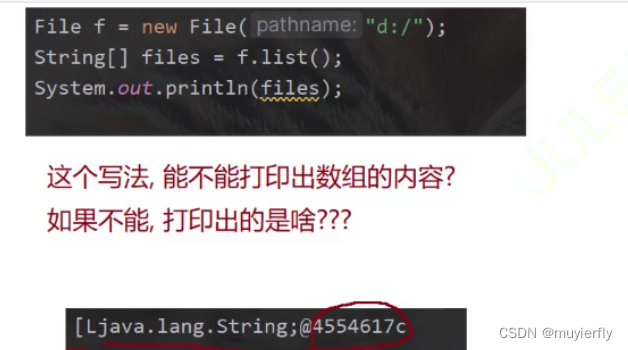
//创建1级目录和多级目录
java">import java.io.File;public class Demo5 {public static void main(String[] args) {File f = new File("d:/java109/aaa/bbb/ccc");// boolean ret = f.mkdir();boolean ret = f.mkdirs();System.out.println("ret = " + ret);} }
//重命名
java">import java.io.File;public class Demo6 {public static void main(String[] args) {// src 就是 "源", dest 就是 "目标"File srcFile = new File("d:/test.txt");File destFile = new File("d:/test2.txt");boolean ret = srcFile.renameTo(destFile);System.out.println("ret = " + ret);} }
6.文件内容的读写 —— 数据流
6.1 流对象(stream)
在标准库中,提供的读写文件的流对象,不是一两个类,而是有很多很多类,虽然这里有很多的类,实际上这些类都可以归结到两个大的类别中.
1.字节流(对应着二进制文件)
每次读/写的最小单位,都是"字节"(8bit)
2.字符流(对应着文本文件)
【本质上,是针对字节流进行了又一层封装.~~字符流, 就能自动的帮咱们把文件中几个相邻的字节,转换成一个字符 (帮我们完成了一个自动查字符集表)】
每次读/写的最小单位,是"字符"(一个字符可能是对应多个字节)
一个字符对应几个字节? 看当前的字符集是哪种~~
- GBK,一个中文字符 =>两个字节
- UTF8,一个中文字符 =>三个字节
到底啥叫做输入?啥叫做输出?
我把一个数据保存到硬盘中,这个过程算输入还是输出??
如果你是站在硬盘的视角 =>输入如果你是站在 cpu 的视角 =>输出(我们是以CPU为视角)一共分为四个类
//字节流
InputStream
OutputStream
//字符流
reader
writer
基本流程:
1.打开文件 (构造方法)
2.读(输入read)/写(输出write)
3.关闭文件(使用文件完毕之后, 一定要记得关闭)否则容易造成 文件资源泄露!!!
6.2 Reader 概述
- 抽象类, 不能 new 实例.
- 只能 new 子类
java">import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.io.Reader;// Reader public class Demo7 {public static void main(String[] args) throws IOException {// Reader reader = new FileReader("d:/test.txt");// 1. 一次 read 一个字符 // while (true) { // int c = reader.read(); // if (c == -1) { // // 读取完毕 // break; // } // char ch = (char)c; // System.out.println(ch); // }// try { // // 2. 一次 read 多个字符 // while (true) { // char[] cbuf = new char[3]; // // n 表示当前读到的字符的个数. // int n = reader.read(cbuf); // if (n == -1) { // // 读取完毕 // break; // } // System.out.println("n = " + n); // for (int i = 0; i < n; i++) { // System.out.println(cbuf[i]); // } // } // } finally { // // 3. 一个文件使用完了, 要记得, close !!! // reader.close(); // }try (Reader reader = new FileReader("d:/test.txt")) {while (true) {char[] cbuf = new char[3];int n = reader.read(cbuf);if (n == -1) {break;}System.out.println("n = " + n);for (int i = 0; i < n; i++) {System.out.println(cbuf[i]);}}}} }
用int是为了用-1描述出特殊场景
- 如果是 utf8 编码, 一个中文字符,应该是 3 个字节!!!
在 Java 标准库内部, 对于字符编码是进行了很多的处理工作的,如果是只使用 char,此时使用的字符集, 固定就是 unicode如果是使用 String,此时就会自动的把每个字符的 unicode 转换成 utf8把多个 unicode 连续放到一起,是很难区分出从哪里到哪里是一个完整的字符的.utf8 是可以做到区分的~~
utf8 可以认为是针对连续多个字符进行传输时候的一种改进方案.(也是从 unicode 演化过来的)


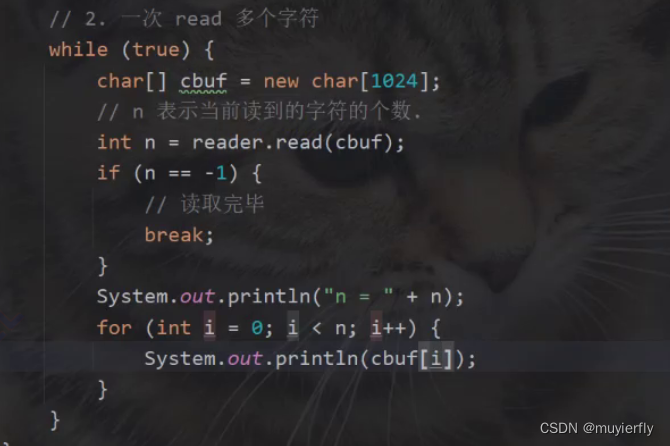
一次read一个字符
由此可以将文件中任意的字符读取出来
一次read多个字符
- 代码加入while的原因
- 如果文件内容特别长,超出了数组的范围,就可以循环执行多次,保证最终能把文件读完尤其是,你要读的文件本身就很大,大概率是需要通过多次循环才能读取完毕的。
- 如果文件为空,直接返回 -1 了,break


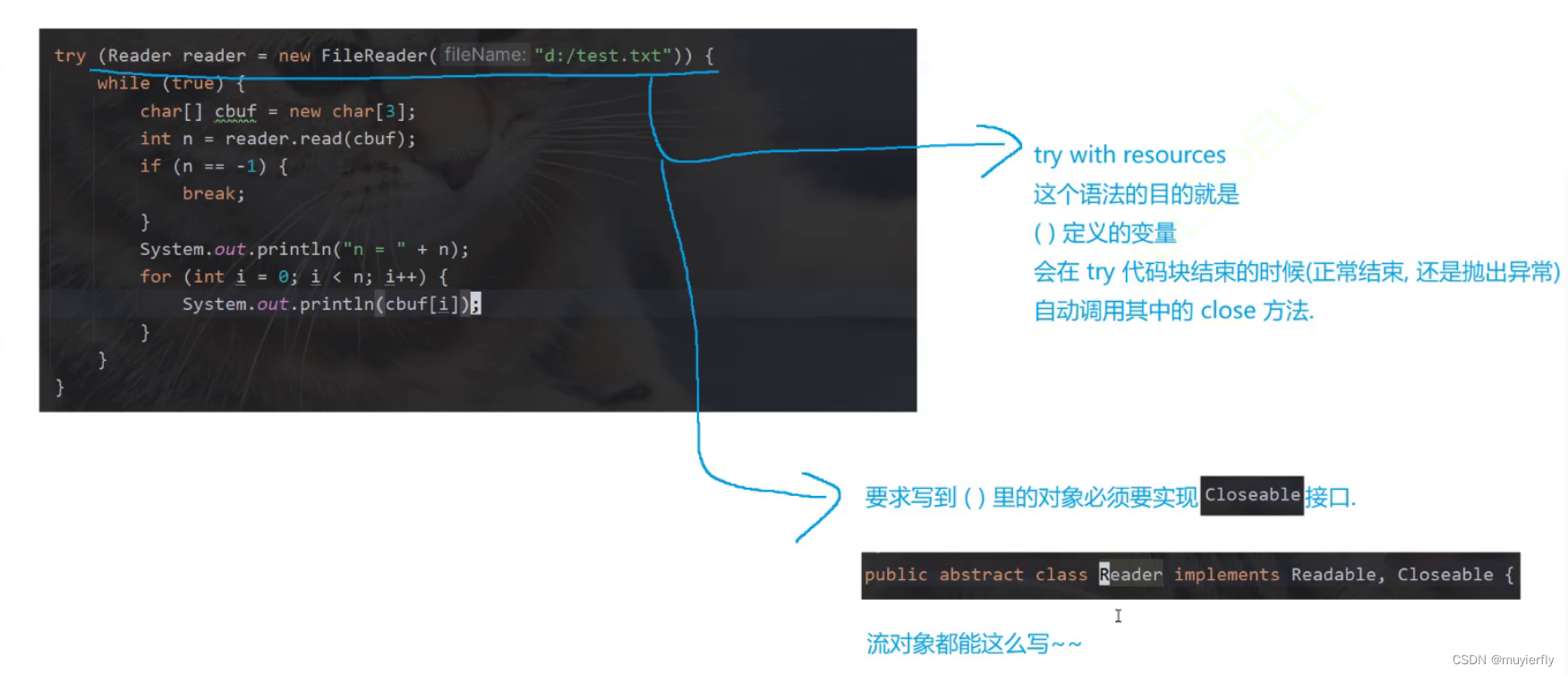
close方法
一个文件使用完了,一定要记得close()

由此会导致文件资源泄漏(文件资源泄漏不会立即暴露,会突然爆发,后果极其严重)
类似于内存泄漏,malloc没有free
使用try...finally(close)的写法(不够优雅)
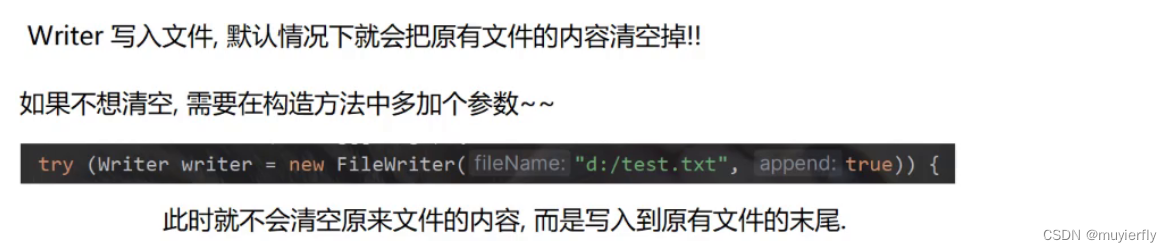
6.2 Writer
java">import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;public class Demo8 {public static void main(String[] args) {try (Writer writer = new FileWriter("d:/test.txt", true)) {// 直接使用 write 方法就可以写入数据.writer.write("我在学习文件IO");} catch (IOException e) {throw new RuntimeException(e);}}
}
6.3 InputStream 概述
方法
| 修饰符及 返回值类 型 | 方法签名 | 说明 |
| int | read() | 读取一个字节的数据,返回 -1 代表已经完全读完了 |
| int | read(byte[] b) | 最多读取 b.length 字节的数据到 b 中,返回实际读到的数量;-1 代表以及读完了 |
| int | read(byte[] b, int off, int len) | 最多读取 len - off 字节的数据到 b 中,放在从 off 开始,返 回实际读到的数量;-1 代表以及读完了 |
| void | close() | 关闭字节流 |
java">import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class Demo9 {public static void main(String[] args) {try (InputStream inputStream = new FileInputStream("d:/test.txt")) {byte[] buffer = new byte[1024];int n = inputStream.read(buffer);System.out.println("n = " + n);for (int i = 0; i < n; i++) {System.out.printf("%x\n", buffer[i]);}} catch (IOException e) {e.printStackTrace();}}
}利用 Scanner 进行字符读取
| 构造方法 | 说明 |
| Scanner(InputStream is, String charset) | 使用 charset 字符集进行 is 的扫描读取 |
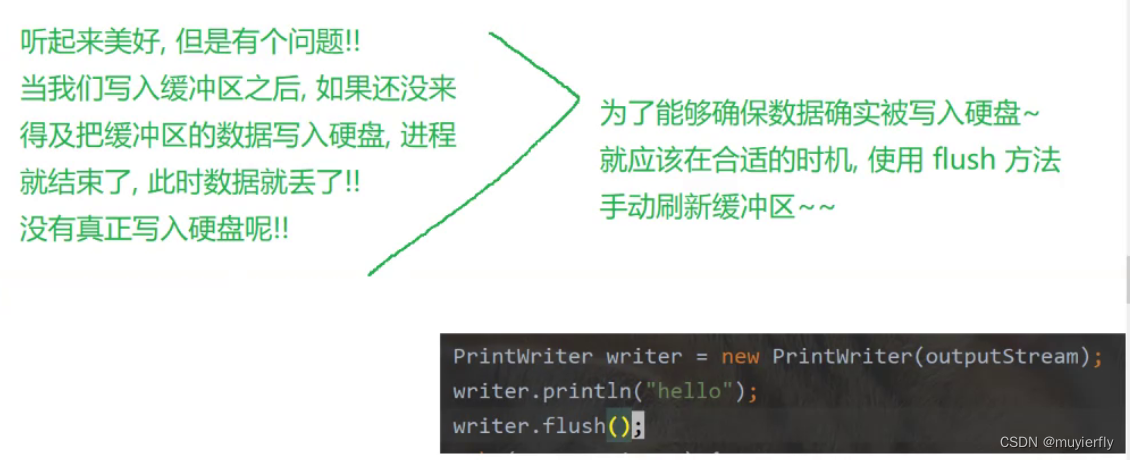
把数据写入内存,非常快的,
把数据写入硬盘,非常慢的!!!(比内存慢个几干倍,上万倍)为了提高效率,就也应该想办法减少写硬盘的次数,
这样就可以确保数据落到硬盘上。
6.4 OutputStream 概述
//类似write
7.例题
java">import java.io.File;
import java.util.Scanner;public class Demo13 {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);// 1. 先让用户输入一个要扫描的目录System.out.println("请输入要扫描的路径: ");String path = scanner.next();File rootPath = new File(path);if (!rootPath.isDirectory()) {System.out.println("您输入的扫描的路径有误!! ");return;}// 2. 再让用户输入一个要查询的关键词.System.out.println("请输入要删除文件的关键词: ");String word = scanner.next();// 3. 可以进行递归的扫描了.// 通过这个方法进行递归.scanDir(rootPath, word);}private static void scanDir(File rootPath, String word) {// 1. 先列出 rootPath 中所有的文件和目录.File[] files = rootPath.listFiles();if (files == null) {// 当前目录为 null, 就可以直接返回了.return;}// 2. 遍历这里的每个元素, 针对不同类型做出不同的处理.for (File f : files) {// 加个日志, 方便观察当前递归的执行过程.System.out.println("当前扫描的文件: " + f.getAbsolutePath());if (f.isFile()) {// 普通文件. 检查文件是否要删除. 并执行删除动作.checkDelete(f, word);} else {// 目录. 递归的再去判定子目录里包含的内容scanDir(f, word);}}}private static void checkDelete(File f, String word) {if (!f.getName().contains(word)) {// 不必删除, 直接方法结束return;}// 需要删除System.out.println("当前文件为: " + f.getAbsolutePath() + ", 请确认是否要删除(Y/n): ");Scanner scanner = new Scanner(System.in);String choice = scanner.next();if (choice.equals("Y") || choice.equals("y")) {// 真正执行删除操作f.delete();System.out.println("删除完毕!");} else {// 如果输入其他值, 不一定非得是 n, 都会取消删除操作.System.out.println("取消删除!");}}
}