PostgreSQL的扩展(extensions)-常用的扩展之pg_repack
pg_repack 是一款非常有用的 PostgreSQL 扩展工具,它能够重新打包(repack)表和索引以回收空间并减少碎片,而且在这个过程中不会锁定表,允许数据库在重整过程中继续对数据进行读写操作。这是与 PostgreSQL 内建的 VACUUM FULL 命令相比的一个重大优势,因为 VACUUM FULL 在重新组织表以回收空间时会锁定表。
特性
- 最小化锁定时间:
pg_repack在重组表和索引的时候减少了锁的使用时间,使得数据库对于读写操作几乎总是可用的。 - 重新打包表和索引:不仅可以对表进行重新打包,还可以重新打包索引,减少索引碎片。
- 兼容性:支持多个 PostgreSQL 版本。
安装 pg_repack
要使用 pg_repack,你需要先在你的 PostgreSQL 服务器上安装它。安装方法可能因操作系统而异。以下是一些常见的安装方法:
-
Debian/Ubuntu
sudo apt-get install postgresql-XX-repack其中
XX是 PostgreSQL 的版本号,例如12、13等。 -
RHEL/CentOS
首先,你需要启用 PostgreSQL 官方仓库,然后安装
pg_repack。例如,对于 PostgreSQL 12:sudo yum install pg_repack12 -
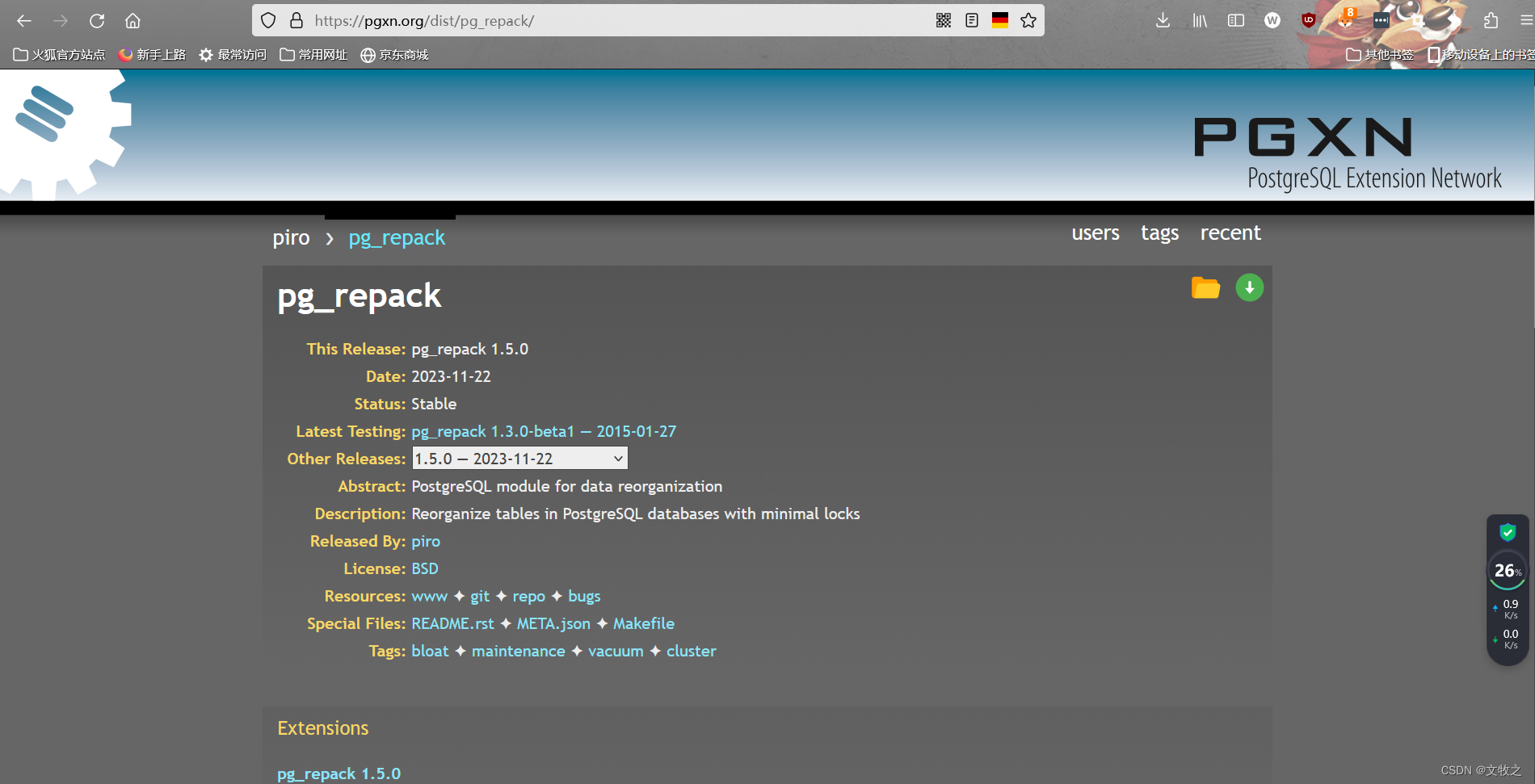
从源代码安装
如果你的系统没有预打包的
pg_repack版本,你可以从源代码编译安装。
下载网址:https://pgxn.org/dist/pg_repack/
–编译安装
cd /home/pg16/resource
[pg16@test resource]$ unzip pg_repack-1.5.0.zip
[pg16@test resource]$ cd pg_repack-1.5.0/
[pg16@test pg_repack-1.5.0]$ make
[pg16@test pg_repack-1.5.0]$ make install
```
当你安装好 pg_repack 后,需要在目标数据库上创建扩展:
[pg16@test pg_repack-1.5.0]$ psql -p 5777
psql (16.2)
Type "help" for help.postgres=# CREATE EXTENSION pg_repack;
CREATE EXTENSION
postgres=# SELECT * FROM pg_extension;oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+--------------------+----------+--------------+----------------+------------+-----------+--------------14270 | plpgsql | 10 | 11 | f | 1.0 | | 16423 | pg_stat_statements | 10 | 2200 | t | 1.10 | | 16454 | pg_repack | 10 | 2200 | f | 1.5.0 | |
(3 rows)
使用 pg_repack
在安装并配置 pg_repack 之后,你可以通过命令行工具 pg_repack 来重新组织表和索引。以下是一些基本用法:
-
重新打包特定表:
pg_repack -d databasename -t tablename -
重新打包所有表:
pg_repack -d databasename -
重新打包特定索引:
pg_repack -d databasename --only-indexes -t tablename
请记得,使用 pg_repack 之前,确保你已经有了足够的权限来执行这些操作,并且对数据库做了适当的备份。