目录
引言
Abstract
文献阅读
1、题目
2、引言
3、创新点
4、总体流程
5、网络结构
5.1、损失函数
5.2、Confidence Maps
5.3、Part Affinity Fields(PAFs)
5.4、多人的PAFs
6、实验
7、结论
深度学习 yolov8实现目标检测和人体姿态估计
Yolov8网络结构
yaml配置文件解析
模型预训练
模型预测
总结
引言
本周阅读了一篇关于openpose的论文,本文提出了一种使用部分关联场(Part Affinity Fields)的方法,能够高效地检测图像中多个人的二维姿势。该方法通过学习将身体部位与图像中的个体关联起来,实现了全局上下文编码,并通过贪婪自底向上的解析步骤来保持高准确性并实现实时性能,无论图像中有多少人。在此基础上学习了yolov8的网络结构和代码,实现了对人体的检测和姿态估计。
Abstract
This week, I read a paper on openpose, which proposes a method using Part Affinity Fields to efficiently detect two-dimensional poses of multiple individuals in an image. This method associates body parts with individuals in the image through learning, achieving global context encoding, and maintaining high accuracy and real-time performance through greedy bottom-up parsing steps, regardless of how many people are in the image. On this basis, I learned the network structure and code of YOLOv8, and achieved human detection and pose estimation.
文献阅读
1、题目
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
2、引言
我们提出了一种方法来有效地检测图像中的多个人的2D姿态。该方法使用非参数表示,我们称之为部分亲和场(PAF),学习将身体部位与图像中的个体相关联。该架构对全局上下文进行编码,允许贪婪的自下而上的解析步骤,在实现实时性能的同时保持高准确性,而不管图像中的人数。该架构旨在通过同一顺序预测过程的两个分支共同学习零件位置及其关联。并且在性能和效率方面都大大超过了MPII MultiPerson基准测试的最新结果。
3、创新点
- 提出了一种实时方法来检测图像中多个人的2D姿势。所提出的方法使用非参数表示(称为部分亲和场(PAF))来学习将图像中的身体部位与个体相关联
- 仅使用PAF进行优化,而不是同时进行PAF和身体部位定位优化,运行时其性能和准确性均会得到大幅提高。
4、总体流程

上图展示了整个流程,输入是w×h的彩色图片 (a),输出是二维的带有每个人的人体关键点位置的图像。首先是一个前馈网络,它同时预测出关于身体部分位置的二维置信图S (b)和一组关于部分亲和度的2D向量场L (c),其中二维向量域的集合 L 编码了部分的关联的程度。集合S具有J个置信度图,S =(S1,S2,...SJ),每个部分一个映射即。集合L=(L1,L2,...LC)有C个向量域,每个四肢对应一个向量域。(这里×2可能是因为向量表示起点和终点,起点在一个w×h中,重点在一个w×h中),LC中的每个图像位置编码一个2D矢量。最后,通过贪婪推理 (d)对置信度图和亲和域进行解析,以输出图像中所有人的2D关键点。
5、网络结构
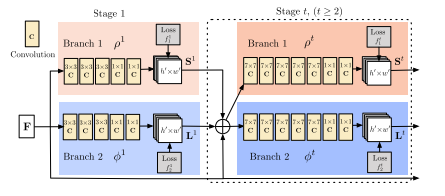
本文的网络结构如上图所示,整个网络是两个分支,多stage的卷积神经网络。其中第一个分支用来预测一个叫做confidence map的东西,可以看作是一个打分的map。而第二个分支用于预测本文提出的PAFs。每一个分支都有着多个stage,每个stage的输入是上一个stage两个branch的输出和最初的图像输入进行融合。
class rtpose_model(nn.Module):def __init__(self, model_dict):super(rtpose_model, self).__init__()self.model0 = model_dict['block0']self.model1_1 = model_dict['block1_1']self.model2_1 = model_dict['block2_1']self.model3_1 = model_dict['block3_1']self.model4_1 = model_dict['block4_1']self.model5_1 = model_dict['block5_1']self.model6_1 = model_dict['block6_1']self.model1_2 = model_dict['block1_2']self.model2_2 = model_dict['block2_2']self.model3_2 = model_dict['block3_2']self.model4_2 = model_dict['block4_2']self.model5_2 = model_dict['block5_2']self.model6_2 = model_dict['block6_2']model = rtpose_model(models)return model# model初始化:加载模型
model = get_model(trunk='vgg19') # 可以换网络, elif trunk == 'mobilenet':
model = torch.nn.DataParallel(model).cuda()
# load pretrained
use_vgg(model) # 加载预训练模型。url = 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'最核心的部分:利用标注好的信息anns 来生成热图(heatmaps)和部件关联图(pafs)的真值信息。
vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46
多了一个脖子外加一个背景
按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
ef get_ground_truth(self, anns):#vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46grid_y = int(self.input_y / self.stride)grid_x = int(self.input_x / self.stride)channels_heat = (self.HEATMAP_COUNT + 1)#19 HEATMAP_COUNT中coco给了17个,但是我们多了一个脖子所以18个,+1是背景所以是19channels_paf = 2 * len(self.LIMB_IDS)#按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]heatmaps = np.zeros((int(grid_y), int(grid_x), channels_heat))pafs = np.zeros((int(grid_y), int(grid_x), channels_paf))#对于躯干来说,没有躯干的位置,向量为0,有躯干的地方为1keypoints = []# anns有多少list,就说明有多少个人,anns里面的num_keypoints表示每个人体部位关键点有被标注的个数,有些可能没标有些可能标了但是被遮挡了(也就是1)# 第一个注释的"num_keypoints"为0,表示该注释中没有标记的关键点。第二个注释的"num_keypoints"为14,表示该注释中标记了14个关键点,等等等等for ann in anns:# 17种部位,3列(x,y,keypoint)single_keypoints = np.array(ann['keypoints']).reshape(17, 3)# 在这里添加个脖子,先找到左肩膀和右肩膀求平均,就是脖子的位置了single_keypoints = self.add_neck(single_keypoints)keypoints.append(single_keypoints)keypoints = np.array(keypoints)# 去除不合法的关节。具体而言,这个方法可能会处理一些关节坐标异常或无效的情况,例如超出图像范围、无效的坐标值等。keypoints = self.remove_illegal_joint(keypoints)生成高斯热图,从0遍历到18,每个部位都遍历
# 有了标注点后就开始生成高斯热图,在ppt的第9页# confidance maps for body parts# 从0遍历到18,每个部位都遍历for i in range(self.HEATMAP_COUNT):# print(keypoints)joints = [jo[i] for jo in keypoints] # 每次遍历所有人的同一种关键点,多少人就多少个# print(joints)# 每次遍历每个人的同一种部位的关键点生成热图(例如肩膀),然后是0的话就是没有标注的,所以判断是否大于0.5for joint in joints:# 1是标注被遮挡 2是标注且没被遮挡if joint[2] > 0.5:center = joint[:2] # 点坐标# 每次gaussian_map都要赋值,因为要在这基础上生成高斯热图。需要一直累加生成高斯图gaussian_map = heatmaps[:, :, i]# 对这个点坐标center 生成高斯热图,#7.0是sigmaheatmaps[:, :, i] = putGaussianMaps(center, gaussian_map,7.0, grid_y, grid_x, self.stride)在本文中,使用 S 来表示预测人体某个部分的位置的confidence maps,用 L 来表示part affinities,他是一连串的2D向量场。

其中 J 代表有 J 个 confidence maps, one per part。C代表C vector fields, one per limb。每个在 中的图像位置encode了一个2D向量,如下图所示

再次回看网络结构图,输入的 F 是输入的图像被VGG-19的前10层经过处理和fine-tuned之后的特征图。
对于第一个stage来说,文章定义 ,
。对于之后的每一个stage,S 和 F 都可以从下面两个式子得到

其中 ,
都是网络中的卷积神经网络。
5.1、损失函数
使用了两个损失函数,分别对应于每个stage的两个branch:

在上式当中 是 groundtruth part confidence map也被称作heat map,而
是groundtruth part affinity vector field。 W 是一个binary mask, 当位置p的annotation缺失的时候 W(p) = 0 ,否则就为 1,所以未标记的人物关节点不会影响模型的学习过程。
最后总的损失如下:

total_loss, saved_for_log = get_loss(saved_for_loss, heatmap_target, paf_target)5.2、Confidence Maps
文章指出,当一张图中出现了多个人,应该对于每个人 k 每个可见的part j 都有一个peak在confidence map中。 我们让 表示图像中人物 k 的身体部位 j 的真实位置。对于位置 p 可以以下式子计算value:

![]()
实际上就是使用2D高斯分布建模,求出一张图像中身体 j 部位的热图。在测试的时候,使用非极大值抑制来获取body part candidates。
5.3、Part Affinity Fields(PAFs)
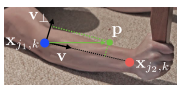
已知关键点,如何形成未知人数的全身姿态?需要对每一种关键点的连接进行置信度的度量,图a是所有的连接候选;另一种方式是附加每对连接的中点,如图b,检查中点的发生率,这样错误率依然很高。错误的原因是:1.只编码位置信息,没有方向信息;2.将一个区域只用一个点去表示。

PAFs是一个2D矢量场,保留了位置和方向,如图c所示,表示一个肢体,在肢体上的每个点是从一个关键点到下一个关键点的2D单位矢量。令和表示ground truth中的关键点 j1,j2 的坐标,这两个关键点组成第k号人的一个肢体c,如果一个点P在这个肢体上面,如图所示,则的值为j1指向j2的单位矢量;其他点都是零向量,如下公式,每一个点上都有一个向量,L可以理解为对于图像中肢体的单位向量表示。
Ground-truth的PAF计算方法如下:C=38

![]()
在肢体上的点P满足下式(其实代表的就是P在肢体对应的矩形内)

其中,L是肢体的长度,是肢体的宽度,v是垂直矢量。
(注解:点乘 又叫向量的内积、数量积,是一个向量和它在另一个向量上的投影的长度的乘积;是标量。点乘 反映着两个向量的“相似度”,两个向量越“相似”,它们的点乘 越大。)
一张图像中肢体c的PAFs是(重叠处,多个人的同一肢体)所有人物进行平均得到(此情况很少出现)

Nc(P)是P点处所有非0向量的个数,即k个人重叠肢体在像素上的平均。
在测试时,沿着“关键点对”组成的线段计算上面PAF的线积分,来度量这对“关键点对”的关联程度。换句话说,关联程度是通过度量这两者的对齐程度得到:预测的PAF,通过关键点连接形成的肢体。具体的=来说,对于两个候选关键点,位置是和,沿着线段采样预测出的PAF值(即Lc),表示这两个关键点相关联的置信度E。
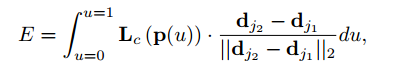
其中p(u)是两个部位(关节点)和之间内插的位置
![]()
在实践中,通过对u的均匀间隔采样来近似求积分。
生成pafs

putVecMaps函数: 必须有标注的,否则没法算向量
for i, (k1, k2) in enumerate(self.LIMB_IDS):# limb# 表示该位置是否被计算了多次(计算的数量)count = np.zeros((int(grid_y), int(grid_x)), dtype=np.uint32)for joint in keypoints:# 必须有标注的,否则没法算向量if joint[k1, 2] > 0.5 and joint[k2, 2] > 0.5:#k1,k2是self.LIMB_IDS是规定的连接规则centerA = joint[k1, :2]# [283. 280.]centerB = joint[k2, :2]# [292.34824 294.96875]# 拿到向量的结果。每次都取出两个通道? 每一个躯干位置,选择x和y两个方向0-2,2-4,4-6vec_map = pafs[:, :, 2 * i:2 * (i + 1)]# 使用putVecMaps 来真正的构建向量pafs[:, :, 2 * i:2 * (i + 1)], count = putVecMaps(centerA=centerA,centerB=centerB,accumulate_vec_map=vec_map,count=count, grid_y=grid_y, grid_x=grid_x, stride=self.stride)# backgroundheatmaps[:, :, -1] = np.maximum(1 - np.max(heatmaps[:, :, :self.HEATMAP_COUNT], axis=2),0.)return heatmaps, pafs5.4、多人的PAFs
对检测出来的置信度图执行非极大值抑制,获得离散的关键点位置候选集。由于图中有多人,对于每种关键点,有若干候选。因此有很多可能的肢体,如下图 b 所示。通过计算PAF上的线积分评估每一个候选肢体的置信度。找到最优肢体是一个NP问题,在本文中使用一个贪心松弛策略(匈牙利算法),使得每次都能产生高质量的匹配。

首先,得到一系列关键点候选(整张图像多个人),记为Dj={},表示关节j的图中第m个候选关键点。这些关键点候选需要跟同一个人的其他关键点进行关联,找到关键点的成对关系,即肢体。定义变量={0或1}表示关键点候选和是否关联。算法目标:找到所有最佳关联,记为Z。
![]()
考虑一对关键点j1,j2(例如脖子,右臀)组成肢体c,找到最佳匹配,是最大权重二分图匹配问题:节点是候选集Dj,边的权值由置信度公式计算,二分图匹配选择最大权重的边(匹配就是从边中选子集),使得没有边共享节点(由公式13-14强制要求,没有同类肢体共享一个关键点,比如一个脖子只连接一个右臀)。找最佳二分图匹配使用匈牙利算法。
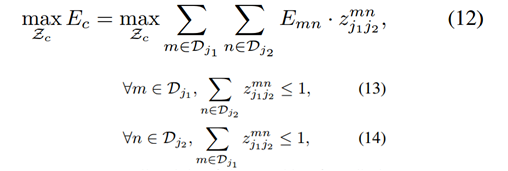
事实上,到此为止 Z 的具体决定方法还没有给出。一般来说,它是一个NPhard的问题,在这篇论文里,作者给出了两个relaxation。
- 选择最小数量的边来获得胡曼姿势的生成树骨架,而不是使用完全图
- 进一步将匹配问题分解为一组二分匹配子问题,并独立地确定相邻树节点的匹配
这样做的理由是相邻的tree nodes的关系可以被PAFs显性模拟出来,而不相邻的tree nodes的关系可以被CNN隐式地模拟出来。
根据以上的relaxation,优化就可以被分解成:
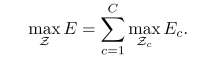
所以实际上,本文是针对每一个类型的肢体(骨骼)独立地寻找最大权重的边。
而最后对于所有的肢体(骨骼)候选,我们就可以通过分享了相同部位的肢体连接来把full-body拼出来。
6、实验
在两个基准上评估:
- MPII human mutil-person dataset
- COCO 2016 keypoints challenge dataset
包含了不同场景、拥挤、遮挡、接触、比例变化。
MPII Multi-Person
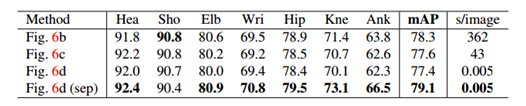
下表本篇论文方法与其他方法在相同的288幅测试图像子集和整个MPII测试集上的MAP性能,以及在自己的验证集上的自我比较。此外,还比较了每幅图像的平均推理/优化时间(以秒为单位)。对于288个图像子集,本方法比以前最先进的自下而上方法高出8.5%的MAP。值得注意的是,推理时间减少了6个数量级。
对于整个MPII测试集,本方法在没有尺度搜索的情况下已经大大超过了以前最先进的方法,即在MAP上增加了13%的权重。使用3比例尺搜索(×0.7、×1和×1.3)进一步将MAP的性能提高到75.6%。AP与以前自下而上的方法的比较表明了新特征表示PAF在关联身体部位方面的有效性。基于树结构,贪婪解析方法比基于完全连通图结构的图形切割优化公式获得了更高的准确率。

下表说明贪心策略可行,效率提高很多,且效果更好(收敛更快)。
下图 a 示出了对验证集的消融分析。对于PCKh-0.5的阈值,使用PAFS的结果比使用中点表示的结果要好,具体来说,它比一个中点高2.9%,比两个中间点高2.3%。对人体肢体的位置和姿态信息进行编码的PAF能够更好地区分常见的交叉情况,例如重叠的手臂。使用未标记人员的面具进行训练可以进一步提高2.3%的性能,因为它避免了对训练过程中损失的真实正面预测的惩罚。如果将地面真实关键点定位与我们的解析算法结合使用,可以获得88.3%的mAP值。在图 a 中,由于无定位误差,使用 GT 检测进行解析的 mAP 在不同的 PCKh 阈值上是恒定的。 使用 GT 连接和关键点检测实现了 81.6% 的 mAP。 值得注意的是,基于 PAF 的解析算法使用 GT 连接实现了类似的 mAPas(79.4% 对 81.6%)。 这表明基于 PAF 的解析在关联正确部分检测方面非常稳健。 图 b 显示了跨阶段的性能比较。 mAP 随着迭代细化框架单调增加。

COCO key points challenge
Openpose在小尺度人群上的准确性低于自上而下的方法。 原因是本方法必须处理的范围要大得多,图像中的所有人都可以在一次拍摄中扫视。相比之下,自上而下的方法可以将每个检测区域的斑块重新缩放到更大的尺寸,从而在较小的尺度上受到较小的退化。

如果使用GT Bbox和单人CPM,使用CPM可以达到自上而下方法的上限,为62.7%的AP;如果使用最先进的对象检测器Single Shot Multi Box检测器(SSD),性能下降了10%,这表明自顶向下方法的性能严重依赖于Person检测器。相比之下,作者的自底向上方法达到了58.4%的AP。如果改进作者的方法的结果,将单人CPM应用于本方法分析的每个重新缩放的估计人的区域,得到了2.6%的总体AP增加。请注意,只更新对两种方法完全一致的预测的估计,从而提高了精确度和召回率。
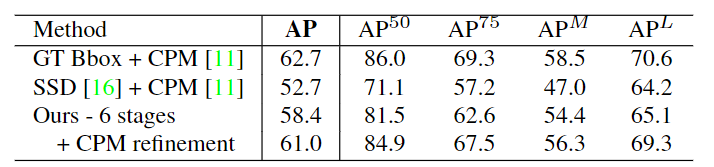
期望更大范围的搜索可以进一步提高自下而上方法的性能。下图显示了本方法在COCO验证集上的错误明细。大多数误报来自于不精确的定位,而不是背景混乱。这表明在捕捉空间相关性方面比在识别身体部位外观方面有更大的改进空间。

7、结论
在本文中,考虑了这种感知的一个关键组成部分:实时算法来检测图像中多人的 2D 姿势。 提出了关键点关联的显式非参数表示,该关联对人体四肢的位置和方向进行编码。 其次,设计了一种用于联合学习部位检测和部位关联的架构。 第三,证明了贪心解析算法(greedy parsing algorithm)能够产生高质量的身体姿势解析,即使图像中的人数增加也能保持效率。
深度学习 yolov8实现目标检测和人体姿态估计
Yolov8网络结构
Yolov8模型网络结构图如下所示

Backbone
Yolov8的Backbone借鉴了CSPDarkNet结构网络结构,与Yolov5最大区别是,Yolov8使用C2f模块代替C3模块。具体改进如下:
- 第一个卷积层的Kernel size从6×6改为3x3。
- 所有的C3模块改为C2f模块,如下图所示,多了更多的跳层连接和额外Split操作。
- Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。
C2f与C3对比

由上图可以看出,C2f中每个BottleNeck的输入Tensor的通道数channel都只是上一级的0.5倍,因此计算量明显降低。从另一方面讲,梯度流的增加,也能够明显提升收敛速度和收敛效果。
C2f模块首先以输入tensor(n,c,h,w)经过Conv1层进行split拆分,分成两部分(n,0.5c,h,w),一部分直接经过n个Bottlenck,另一部分经过每一操作层后都会以(n,0.5c,h,w)的尺寸进行Shortcut,最后通过Conv2层卷积输出。也就是对应n+2的Shortcut(第一层Conv1的分支tensor和split后的tensor为2+n个bottenlenneck)。
Neck
YOLOv8的Neck采用了PANet结构,如下图所示

Backbone最后SPPF模块(Layer9)之后H、W经过32倍下采样,对应地Layer4经过8倍下采样,Layer6经过16倍下采样。输入图片分辨率为640*640,得到Layer4、Layer6、Layer9的分辨率分别为80*80、40*40和20*20。
Layer4、Layer6、Layer9作为PANet结构的输入,经过上采样,通道融合,最终将PANet的三个输出分支送入到Detect head中进行Loss的计算或结果解算。
与FPN(单向,自上而下)不同的是,PANet是一个双向通路网络,引入了自下向上的路径,使得底层信息更容易传递到顶层。
Head
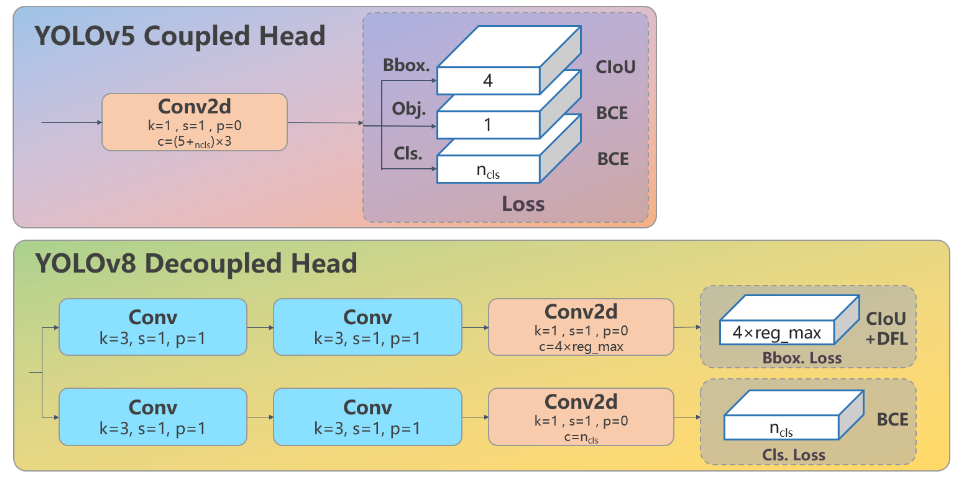
Head部分相比Yolov5改动较大,直接将耦合头改为类似Yolox的解耦头结构(Decoupled-Head),将回归分支和预测分支分离,并针对回归分支使用了Distribution Focal Loss策略中提出的积分形式表示法。之前的目标检测网络将回归坐标作为一个确定性单值进行预测,DFL将坐标转变成一个分布。
yaml配置文件解析
参数部分
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 768]l: [1.00, 1.00, 512]x: [1.00, 1.25, 512]Yolov8采用Anchor-Free方式,因而在yaml文件中移除了anchors参数,并且将多个不同版本的模型参数写在一个yaml,同时在深度因子和宽度因子后面增加了 最大通道数 这一参数。
Backbone
# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# [from, repeats, module, args]
from:本层的来源,即就是输入。-1表示将上层的输出作为本层的输入。
repeats:本层重复次数。
module:本层名称。
args:本层参数。
- 第0层:[-1,1,Conv,[64, 3, 2]]
- -1表示将上层的输出作为本层的输入,第0层的输入是640*640*3的图像。
- Conv表示卷积层。
- [64, 3, 2]:输出通道数64,卷积核大小k为3,stride步长为2。由此计算padding为1。
- 输出特征图大小(向下取整1):f_out=((f_in - k + 2*p ) / s )=((640 - 3 + 2*1 ) / 2 )=320。
- 所以本层输出特征图尺寸为320*320*64,长宽为原输入图片的1/2。
- 第1层:[-1,1,Conv,[128, 3, 2]]
- [128, 3, 2]:输出通道数128,卷积核大小k为3,stride步长为2。
- 输出特征图大小(向下取整1):f_out=((f_in - k + 2*p ) / s )=((320 - 3 + 2*1 ) / 2 )=160。
- 所以本层输出特征图尺寸为160*160*128,长宽为原输入图片的1/4。
- 第2层:[-1,3,C2f,[128, True]]
- [128, True]:128表示输出通道数,True表示Bottleneck有shortcut。
- 本层输出特征图尺寸仍为160*160*128。
- 第3层:[-1,1,Conv,[256,3,2]]
- [256,3,2]:输出通道数256,卷积核大小k为3,stride步长为2。
- 输出特征图大小(向下取整1):f_out=((f_in - k + 2*p ) / s )=((160-3+ 2*1 )/2)=80。
- 所以本层输出特征图尺寸为80*80*256,长宽为原输入图片的1/8。
- …
- 第9层:[-1,1,SPPF,[1024, 5]]
- [1024, 5]:1024表示输出通道数,5表示池化核大小k。
- 输出特征图尺寸为20*20*1024。
Head
# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)- 第10层:[-1,1,nn.Upsample,[None,2,‘nearest’]]
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)本层为上采样层,-1表示将上层的输出作为本层的输入。None表示上采样的输出尺寸size不指定。2表示scale_factor=2,即输出尺寸是输入的2倍,nearest表示使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变为原来的二倍,通道数不变,所以输出特征图尺寸为40*40*1024。
- 第11层:[[-1,6],1,Concat,[1]]
- 本层为cancat层,[-1,6]表示将上层和第6层的输出作为本层的输入,[1]表示concat拼接的维度为1。上层的输出尺寸为40*40*1024,第6层的输出尺寸为40*40*512,最终本层的输出尺寸为40*40*1536。
- …
- 第21层:[-1,3,C2f,[1024]]
- 本层是C2f模块,3表示本层重复3次。1024表示输出通道数。经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成原输入图片的1/32。
- 第22层:[[15, 18, 21], 1, Detect, [nc]]
- 本层是Detect层,[15, 18, 21]表示将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。
模型预训练


从官网下载预训练模型,epochs设置为300,训练模型,根据训练过程中得到loss优化相关的可视化图。
模型预测

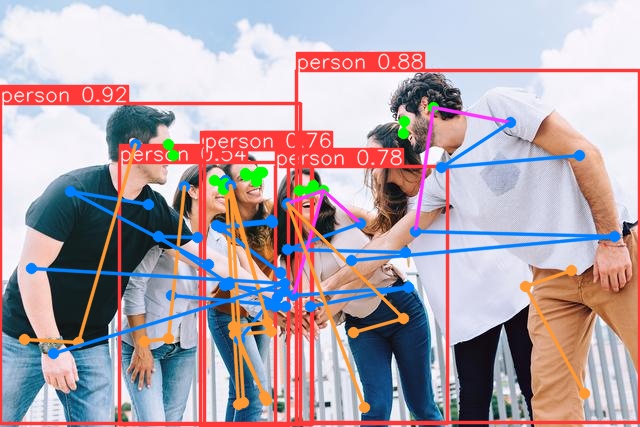
根据训练完成的模型,得到person的目标检测,以及检测到对应每个人的姿态估计的姿势。
总结
本周加深了关于姿态估计的知识,并且通过代码对人体的关键点检测和连接有了更深的认识。