Kafka 为什么要抛弃 ZooKeeper?取代方案是怎样的?因为确实有优化空间。
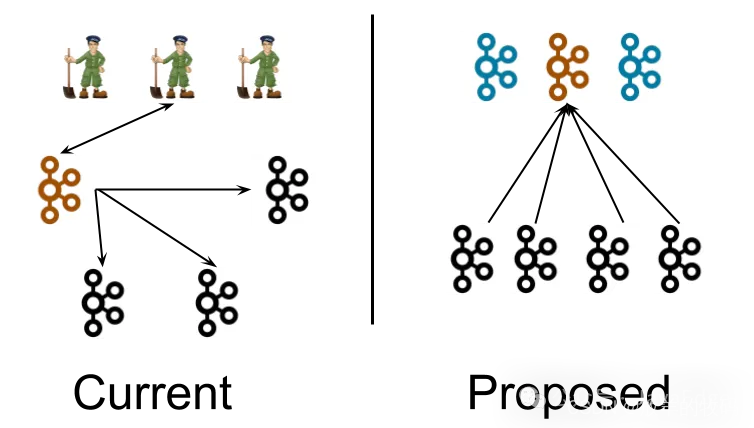
Zookeeper加kafka 的架构,有三层角色:
-
zookeeper ,提供基础的状态持久化和状态通知服务
-
controller ,基于zookeeper提供的服务,给松散的broker提供统一的状态服务,但它本身没有状态服务,它是依赖zookeeper 的服务来做主控
-
一层是broker ,无状态服务,因为他们无状态,无法自发组织起来,所以需要controller为他们做主控。其中有一个broker 兼职了controller 角色
这架构本没问题,但要优化也可以。zookeeper本来提供状态服务,但它不是kafka一部分,所以kafka不得不设计一个controller做主控。
假如controller本身就可提供状态服务,那三层架构就可简化成两层:
-
controller ,提供主控服务
-
broker ,无状态工作服务
Kafka 抛弃zookeeper 就是做这优化,自己开发基于raft 共识算法的一致性服务kraft:
-
为集群提供之前zookeeper的状态服务的同时
-
也为broker 提供主控服务即controller
相比之前架构
还有很大优点,controller故障切换很快,且切换时间几乎不随集群规模而线性增长。
以前架构
controller 只有一个,如做controller故障切换,新controller需全量从zookeeper同步集群所有元数据信息并构建到内存,为做主控服务做准备,这些元数据信息包括topic和分区信息,如一个大规模集群,topic 和分区很多,该过程很耗时,也就会造成更久停机时间。
以前的架构也可以安排一些broker作为备选controller定期从zookeeper同步元数据,但这只是解决了部分问题,https://cwiki.apache.org/confluence/display/KAFKA/KIP-500:+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum。以前的架构,只有选出来的主控才会同步数据,其他没胜出的broker 只做broker 的角色。具体辩论,大家自查。
controller有多个,只是只有一个是leader 提供主控服务,其他的作为follower ,会实时同步leader的元数据信息,也就是元数据在多个controller 里面是几乎保持一致的(raft 协议保证的),所以故障切换的时候,几乎不需要再同步元数据,就可以完成controller 切换。
官方文件解读
参照官方的KIP议案。
Colin McCabe发起提案:[KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum]
具体讨论细节参考邮件列表:https://lists.apache.org/thread/w43g74zlttpn2nl2nyppp4fsdszwg7sb
要解决问题
为啥替换zk,主要:
-
集群元数据的管理将更具有扩展性(scalable),更健壮(robust)
之前受zookeeper的影响,集群可以创建的[topic]数量是受限的,新的架构可以支持更多的topic。
-
简化Kafka的部署流程和配置成本
第一个集群状态[元数据管理]暴漏出来的问题:因为[元数据]管理(zk state)和集群状态的管理(controller state)是不同的数据管理路径,经常导致zk中的状态和集群控制器controller中的状态不一致的问题。两个数据源要进行数据状态的同步,这本身就是[分布式系统]中的一个让人头疼的事情。如果controller简单通过watch机制来监听zk的变更日志来同步状态的话,由于watch机制的限制,这个方法的性能会出问题,而且还没有考虑到watch通知机制的可靠性。
相比之前需要显示通知broker的方式,新的方式情况下,各个broker也将采取订阅 metadata event log的方式,和kafka本身要解决的问题本质上是类似的。broker本身要一个文件来存储自己维护的元数据信息。通过这种方式,kafka可以支持更多的partition数量,并且可以进一步的降低CPU的利用率。
第二个角度是从运维和配置的角度来看:
-
由于引入了zk这个独立的分布式组件系统,那我们的运维人员在部署kafka的时候,除了kafka本身,还需要有zk的部署运维经验。而如果把zk依赖去掉,降低了系统部署和运维的难度
-
去掉依赖之后,Kafka就有可能支持一个单节点的部署模式,方便大家更快的尝试Kafka。
Zookeeper在kafka生态中遇到一些问题梳理:
架构变更和产品[路线图]
提案大的架构设计变动图:
参考文献
大概的方案设计细节,大家可以参考[wiki文档]
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
- Introducing KRaft: Kafka Without Zookeeper
- Colin McCabe Updates on Apache Kafka KRaft Mode
- Removing the Dependency of Zookeeper on Kafka
- Kafka Needs No Keeper
- Colin McCabe 在CMU的个人主页
- [KIP-98 - Exactly Once Delivery and Transactional Messaging]